蓝桥杯算法竞赛系列第八章——提高篇之广度优先搜索(BFS)


欢迎回到:遇见蓝桥遇见你,不负代码不负卿!

目录
【前言】
搜索算法在蓝桥中考的还是很频繁的,之前发表了二叉树数据结构以及深度优先搜索章节,前面还是比较简单的,这里的广度优先搜索可能稍微复杂那么一丢丢,因为要用到队列,不过我们可以使用STL容器也是很方便就解决了。
【声明】:由于前半部分是基础知识点定义部分,所以前面一小半部分的赘述笔者是参考力扣官方给出的定义以及《算法笔记》一书。

一、广度优先搜索算法(BFS)
对于广度优先搜索的定义及特点,力扣官方是这样给出的:
广度优先搜索算法(Breadth-First Search,缩写为 BFS),又称为宽度优先搜索,是一种图形搜索算法。简单的说,BFS是从根节点开始,沿着树的宽度遍历树的节点。广度优先搜索也广泛应用于图论问题中。
齐头并进的广度优先遍历
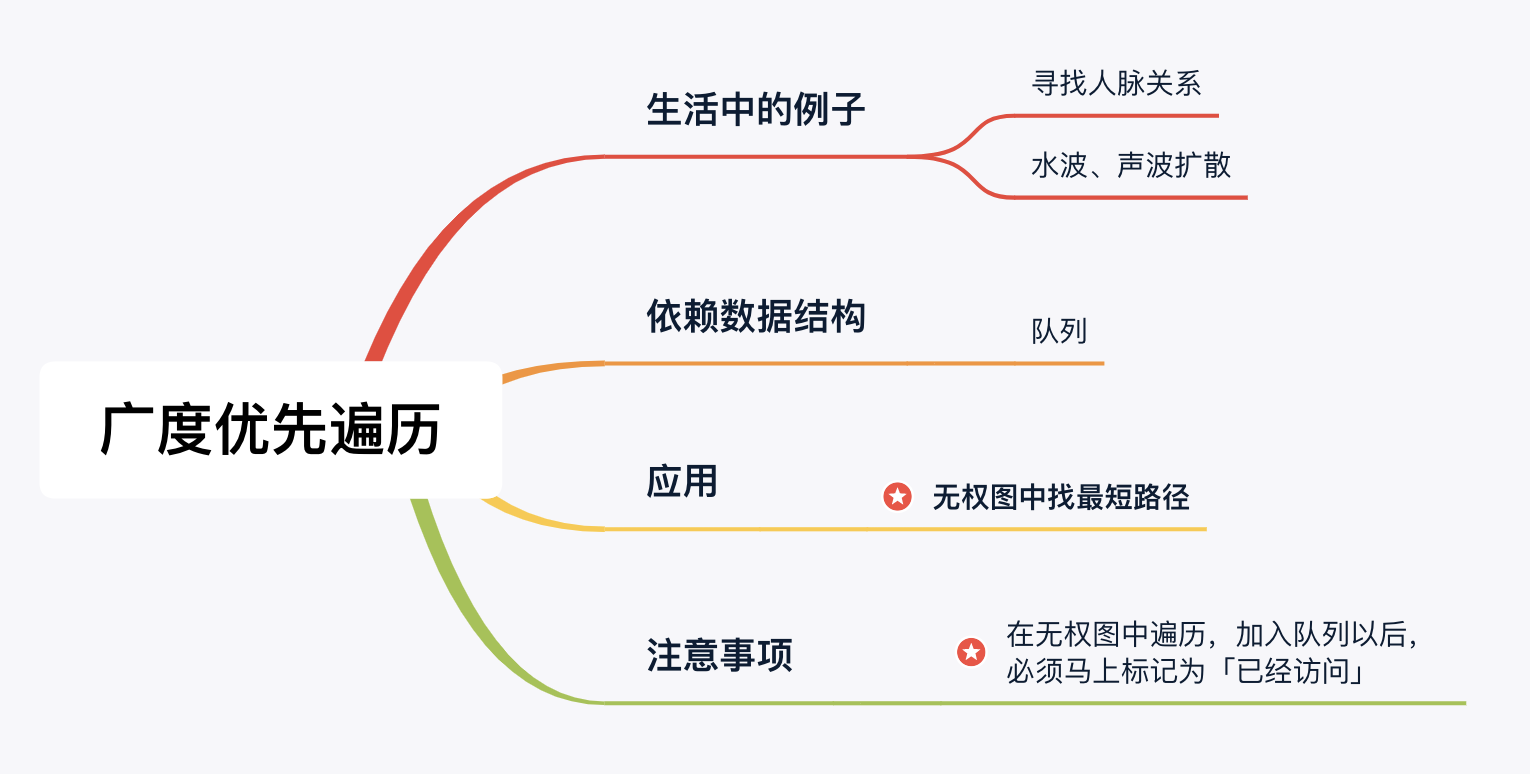
说明:遍历到一个结点时,如果这个结点有左(右)孩子结点,依次将它们加入队列。
可能上面讲的不够细节,下面详细介绍何为”广搜”:
首先呢,铁汁们先将之前的DFS章节前面的迷宫问题再回顾一下,知道何为“死胡同”以及“岔道口”
前面介绍了深度优先搜索,可知DFS是以深度作为第一关键词的,即当岔道口时总是先选择其中的一条岔道前进,而不管其他岔路,直到碰到死胡同时才返回岔道口并选择其他岔路。接下来将介绍的广度优先搜索(Breadth First Search, BFS)则是以广度为第一关键词,当碰到岔道口时,总是先依次访问从该岔道口能直接到达的所有节点,然后再按这些节点被访问的顺序去依次访问它们能直接到达的所有节点,以此类推,直到所有节点都被访问为止。
这就跟在平静的水面中投入一颗小石子一样,水花总是以石子落水处为中心,并以同心圆的方式向外扩散至整个水面,从这点来看和DFS那种沿着一条线前进的思路是完全不同的。

概念部分就讲这么多咯,我呢一直是以讲题目练习为主,OK,废话不多说,咱们走起来!


典例一:二叉搜索树的范围和
注意:二叉搜索树的特点就是左子树都比根要小,右子树都比根要大!
题目描述:

示例1:
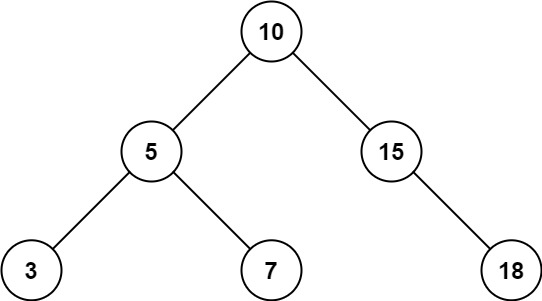
-
输入:root = [10,5,15,3,7,null,18], low = 7, high = 15
-
输出:32
示例2:

-
输入:root = [10,5,15,3,7,13,18,1,null,6], low = 6, high = 10
-
输出:23
方法一:DFS解法
思路:
本题很简单,铁汁们看代码里面的注释就能理解啦。
代码执行:
-
/**
-
* Definition for a binary tree node.
-
* struct TreeNode {
-
* int val;
-
* struct TreeNode *left;
-
* struct TreeNode *right;
-
* };
-
*/
-
-
-
int rangeSumBST(struct TreeNode* root, int low, int high){
-
// //方法一:递归法
-
// //找边界
-
// if(root == NULL){
-
// return 0;
-
// }
-
// //左子树
-
// int leftSum = rangeSumBST(root->left, low, high);
-
// //右子树
-
// int rightSum = rangeSumBST(root->right, low, high);
-
// int result = leftSum + rightSum;
-
// //判断根节点
-
// if(root->val >= low && root->val <= high){
-
// result += root->val;
-
// }
-
// return result;
-
-
//方法二:DFS
-
//判断特殊情况
-
if(root == NULL){
-
return 0;
-
}
-
//如果根节点的值大于high,那么右子树不满足,此时只需要判断左子树
-
if(root->val > high){
-
return rangeSumBST(root->left, low, high);
-
}
-
//如果根节点的值小于low,那么左子树一定不满足,此时只需要判断右子树
-
if(root->val < low){
-
return rangeSumBST(root->right, low, high);
-
}
-
//否则如果根节点的值在low和high之间,那么三者都需要判断
-
return root->val + rangeSumBST(root->left, low, high) + rangeSumBST(root->right, low, high);
-
}
方法二:BFS解法
思路:
使用广度优先搜索的方法,用一个队列 q 存储需要计算的节点。每次取出队首节点时,若节点为空则跳过该节点,否则按方法一中给出的大小关系来决定加入队列的子节点。
代码执行:
-
/**
-
* Definition for a binary tree node.
-
* struct TreeNode {
-
* int val;
-
* TreeNode *left;
-
* TreeNode *right;
-
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
-
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
-
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
-
* };
-
*/
-
class Solution {
-
public:
-
int rangeSumBST(TreeNode* root, int low, int high) {
-
-
queue<TreeNode*>q;//定义一个队列
-
//首先将根节点入队
-
if(root)
-
q.push(root);
-
int res = 0;
-
while(!q.empty())//队列非空时循环继续
-
{
-
int n = q.size();//队列的长度
-
for(int i = 0; i < n; i++)
-
{
-
TreeNode* t = q.front();//访问队首元素
-
q.pop();//队首元素出队
-
//注意输入格式中有空节点,所以要加一个判断
-
//当访问到的节点是空节点时,跳过该节点
-
if(t == nullptr)
-
{
-
continue;
-
}
-
//注意哦,由于是二叉搜索树,有它自己的特性
-
//节点的值大于high时,只需要左子树入队
-
if(t->val > high)
-
q.push(t->left);
-
//节点的值小于low时,只需要右子树入队
-
if(t->val < low)
-
q.push(t->right);
-
//节点的值在low和high之间时,需要加上该节点值以及左右子树入队
-
if(t->val >= low && t->val <= high)
-
{
-
res += t->val;
-
q.push(t->left);
-
q.push(t->right);
-
}
-
}
-
}
-
return res;
-
}
-
};

典例二:二叉树的层序遍历
题目描述:
示例:

思路:
代码中注释给得很详细咯,快去康康叭。
代码执行:
-
class Solution {
-
public:
-
/**
-
*
-
* @param root TreeNode*
-
* @return int整型vector<vector<>>
-
*/
-
vector<vector<int> > levelOrder(TreeNode* root) {
-
// write code here
-
queue<TreeNode*>q;//定义一个队列
-
if(root)
-
q.push(root);
-
vector<vector<int> >ans;//定义一个二维数组用于存放遍历结果
-
while(!q.empty()){//队列为空时停下来
-
int n = q.size();//注意哦,n不能放在循环外边,队列中的元素是在变化的
-
vector<int>tmp;//定义一维数组用于存放每一层的节点(注意一维数组定义的位置)
-
for(int i = 0;i < n;i++){
-
TreeNode* t = q.front();//访问队首元素
-
q.pop();//队首元素出队
-
tmp.push_back(t->val);//将队首元素的值存放到该层的一维数组中
-
if(t->left)//左子节点入队
-
q.push(t->left);
-
if(t->right)//右子节点入队
-
q.push(t->right);
-
}
-
ans.push_back(tmp);//将第一层的一维数组存放二维数组中
-
}
-
return ans;
-
}
-
};

典例三:二叉树的层序遍历 II
题目描述:
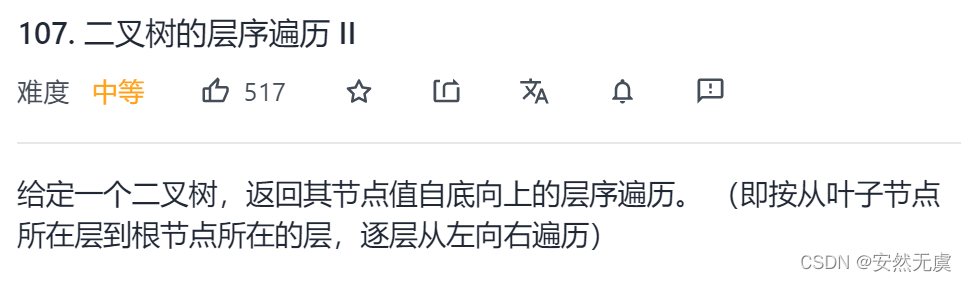
示例:

思路:
哈哈,本题主要是让大家熟练掌握二叉树的层序遍历才添加进来的,本题呢,直接将最后存放到二维数组中的数据反转(#include<algorithm>头文件下)即可。
代码执行:
-
/**
-
* Definition for a binary tree node.
-
* struct TreeNode {
-
* int val;
-
* TreeNode *left;
-
* TreeNode *right;
-
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
-
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
-
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
-
* };
-
*/
-
class Solution {
-
public:
-
vector<vector<int>> levelOrderBottom(TreeNode* root) {
-
//定义一个队列
-
queue<TreeNode*>q;
-
//定义一个二维数组用于返回结果
-
vector<vector<int> >ans;
-
//先将根节点入队
-
if(root)
-
q.push(root);
-
while(!q.empty())
-
{
-
//定义一个一维数组用于存放每一层节点的值
-
vector<int>temp;
-
int n = q.size();//队列的长度
-
for(int i = 0; i < n; i++)
-
{
-
//访问队首元素
-
TreeNode* t = q.front();
-
//队首元素出队
-
q.pop();
-
//将队首元素的值存放到一维数组中
-
temp.push_back(t->val);
-
//访问左子树
-
if(t->left)
-
q.push(t->left);
-
//访问右子树
-
if(t->right)
-
q.push(t->right);
-
}
-
ans.push_back(temp);
-
}
-
reverse(ans.begin(), ans.end());//反转二维数组中的结果
-
return ans;
-
}
-
};

典例四:岛屿数量
题目描述:
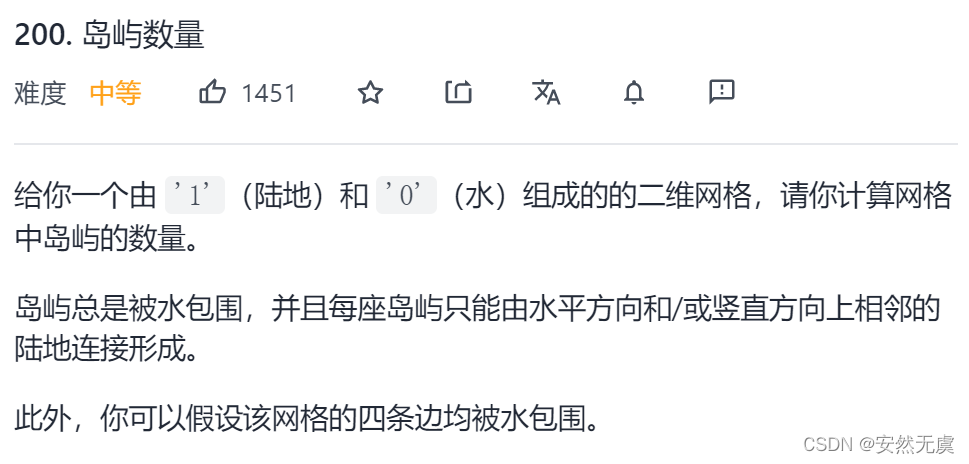
示例1:
-
输入:grid = [
-
["1","1","1","1","0"],
-
["1","1","0","1","0"],
-
["1","1","0","0","0"],
-
["0","0","0","0","0"]
-
]
-
输出:1
示例2:
-
输入:grid = [
-
["1","1","0","0","0"],
-
["1","1","0","0","0"],
-
["0","0","1","0","0"],
-
["0","0","0","1","1"]
-
]
-
输出:3
方法一:DFS解法
思路:
为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 1,则以其为起始节点开始进行深度优先搜索。在深度优先搜索的过程中,每个搜索到的 1 都会被重新标记为 0(也就是下面代码中所说的“同化”)
代码执行:
-
int numIslands(char** grid, int gridSize, int* gridColSize){
-
//找递归边界
-
if(grid == NULL || gridSize == 0)
-
{
-
return 0;
-
}
-
int row = gridSize;//行数
-
int col = *gridColSize;//列数
-
int count = 0;//用于计数
-
int i = 0;
-
int j = 0;
-
//遍历这个二维网格
-
for(i = 0; i < row; i++)
-
{
-
for(j = 0; j < col; j++)
-
{
-
if(grid[i][j] == '1')
-
{
-
count++;
-
//将‘1’周围的‘1’全部同化成0
-
dfs(grid, i, j, row, col);
-
}
-
}
-
}
-
return count;
-
}
-
-
void dfs(char** grid, int x, int y, int row, int col)
-
{
-
//判断特殊情况
-
if(x < 0 || x >= row || y < 0 || y >= col || grid[x][y] == '0')//注意哦,下标等于行数列数时也是不可以的哟
-
{
-
return;
-
}
-
grid[x][y] = '0';//将‘1’同化成0
-
dfs(grid, x - 1, y, row, col);
-
dfs(grid, x + 1, y, row, col);
-
dfs(grid, x, y - 1, row, col);
-
dfs(grid, x, y + 1, row, col);
-
}
方法二:BFS解法
思路:
同样地,我们也可以使用广度优先搜索代替深度优先搜索。
为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 1,则将其加入队列(注意哦,是将其对应的下标存放到队列中的)开始进行广度优先搜索。在广度优先搜索的过程中,每个搜索到的 1 都会被重新标记为 0。直到队列为空,搜索结束。
代码执行:
-
//由于需要用到queue和pair容器,所以选择C++编写代码
-
class Solution {
-
public:
-
int numIslands(vector<vector<char>>& grid) {
-
int nr = grid.size();//行数
-
if (!nr) return 0;//判断边界情况
-
int nc = grid[0].size();//列数
-
-
int num_islands = 0;//用于计数
-
//遍历二维网格
-
for (int r = 0; r < nr; ++r) {
-
for (int c = 0; c < nc; ++c) {
-
//满足条件时进来,否则进入下一次循环
-
if (grid[r][c] == '1') {
-
++num_islands;
-
grid[r][c] = '0';
-
//定义一个队列,用于存放下标信息
-
//注意对pair的理解,可以看作是内部有两个元素的结构体
-
queue<pair<int, int>> neighbors;
-
neighbors.push({r, c});//将'1'的下标信息入队
-
while (!neighbors.empty()) {
-
pair<int,int> rc = neighbors.front();//访问队首元素
-
neighbors.pop();//队首元素出队
-
int row = rc.first;//队首元素所对应的行号
-
int col = rc.second;//队首元素所对应的列号
-
//将它上下左右的‘1’都同化成‘0’
-
//上
-
//row - 1 >= 0 判断位置是否合法
-
if (row - 1 >= 0 && grid[row-1][col] == '1') {
-
neighbors.push({row-1, col});
-
grid[row-1][col] = '0';
-
}
-
//下
-
//row + 1 < nr 判断位置是否合法
-
if (row + 1 < nr && grid[row+1][col] == '1') {
-
neighbors.push({row+1, col});
-
grid[row+1][col] = '0';
-
}
-
//左
-
//col - 1 >= 0 判断位置是否合法
-
if (col - 1 >= 0 && grid[row][col-1] == '1') {
-
neighbors.push({row, col-1});
-
grid[row][col-1] = '0';
-
}
-
//右
-
//col + 1 < nc 判断位置是否合法
-
if (col + 1 < nc && grid[row][col+1] == '1') {
-
neighbors.push({row, col+1});
-
grid[row][col+1] = '0';
-
}
-
}
-
}
-
}
-
}
-
-
return num_islands;
-
}
-
};

五、易错误区
最后需要指出的是,当使用STL的queue时,元素入队的push操作只是制造了该元素的一个副本入队,因此在入队后对原元素的修改是不会影响队列中的副本,同样的,对队列中副本的修改也不会改变原元素,需要注意由此可能引入的bug!
例如下面这个例子:
-
#include<cstdio>
-
#include<queue>
-
-
using namespace std;
-
-
struct node
-
{
-
int data;
-
}a[10];
-
-
int main()
-
{
-
queue<int> q;
-
for (int i = 1; i <= 3; i++)
-
{
-
a[i].data = i;//a[1] = 1, a[2] = 2, a[3] = 3
-
q.push(a[i]);
-
}
-
-
//尝试直接把队首元素(即a[1])的数据域改为100
-
q.front().data = 100;
-
//事实上对队列元素的修改无法改变原元素
-
printf("%d %d %d\n", a[1].data, a[2].data, a[3].data);//输出1 2 3 注意哦,并不是100 2 3
-
//尝试直接修改a[1]的数据域为200(即a[1],上面已经修改为100)
-
a[1].data = 200;
-
//事实上对原元素的修改也无法改变队列中的元素
-
printf("%d\n", q.front().data);//输出100 注意哦,并不是200
-
-
return 0;
-
}
发现上面出现的问题了吗,这就是说,当需要对队列中的元素进行修改而不仅仅是访问时,队列中存放的元素最好不要是元素本身,而是它们对应的编号(如果是数组的话则是下标)。
例如把上面的程序改成下面这样:
-
#include<stdio.h>
-
#include<queue>
-
using namespace std;
-
-
struct node
-
{
-
int data;
-
}a[10];
-
-
int main()
-
{
-
queue<int> q;//q存放数组中元素的下标
-
for (int i = 1; i <= 3; i++)
-
{
-
a[i].data = i;//a[1] = 1, a[2] = 2, a[3] = 3
-
q.push(i);//这里是将数组下标i入队,而不是节点a[i]本身
-
}
-
a[q.front()].data = 100;//q.front()为下标,通过a[q.front()]即可修改原元素
-
printf("%d\n", a[1].data);//输出100
-
return 0;
-
}
六、蓝桥结语:遇见蓝桥遇见你,不负代码不负卿!
搜索的基础部分到这里就结束咯,不过嘞,不会这么简单就结束掉的,后面的话笔者还会出一个蓝桥杯冲刺专栏,还有大量的练习以及相当一部分的真题!OK,今天就到这里咯,下一章节讲的是动态规划(DP)哈。
如果大家有所收获的话,麻烦给俺个三连呗,万分感谢,抱拳了哈。

文章来源: bit-runout.blog.csdn.net,作者:安然无虞,版权归原作者所有,如需转载,请联系作者。
原文链接:bit-runout.blog.csdn.net/article/details/121844343

- 点赞
- 收藏
- 关注作者
评论(0)