三十、MapReduce之wordcount案例(环境搭建及案例实施)

环境准备:
Hadoop2.6.0
IDEA
maven3.5.4
案例分析:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。本项目用到的便是俗称Helloword的数据提取案例,官网源码见hadoop安装目录:
/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar
注意:在windows下直接查看需要反编译工具,解析jar包
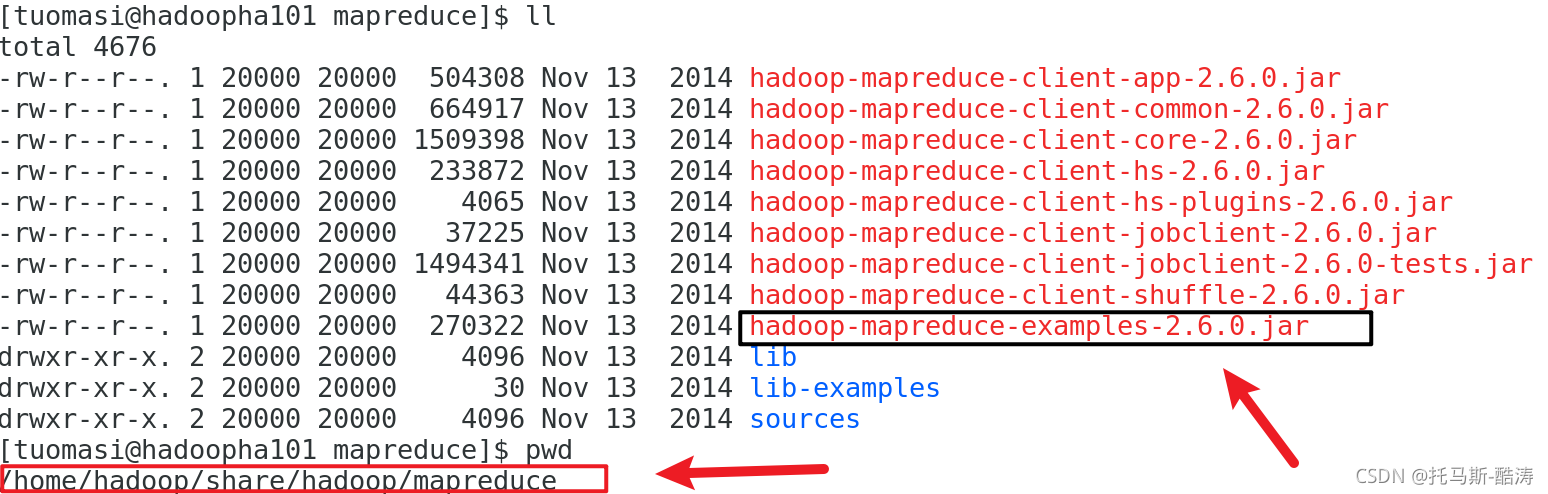
输入数据:
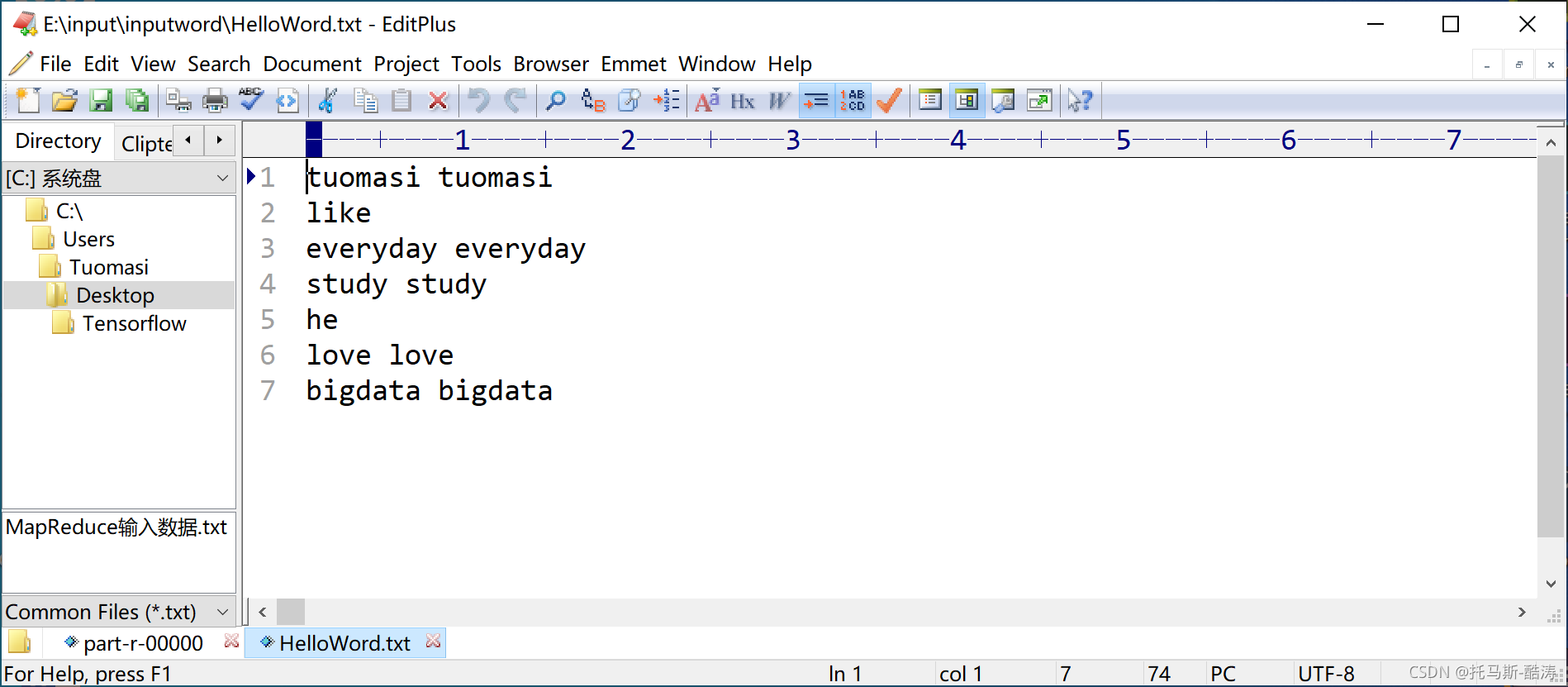
期望输出数据:
环境搭建:
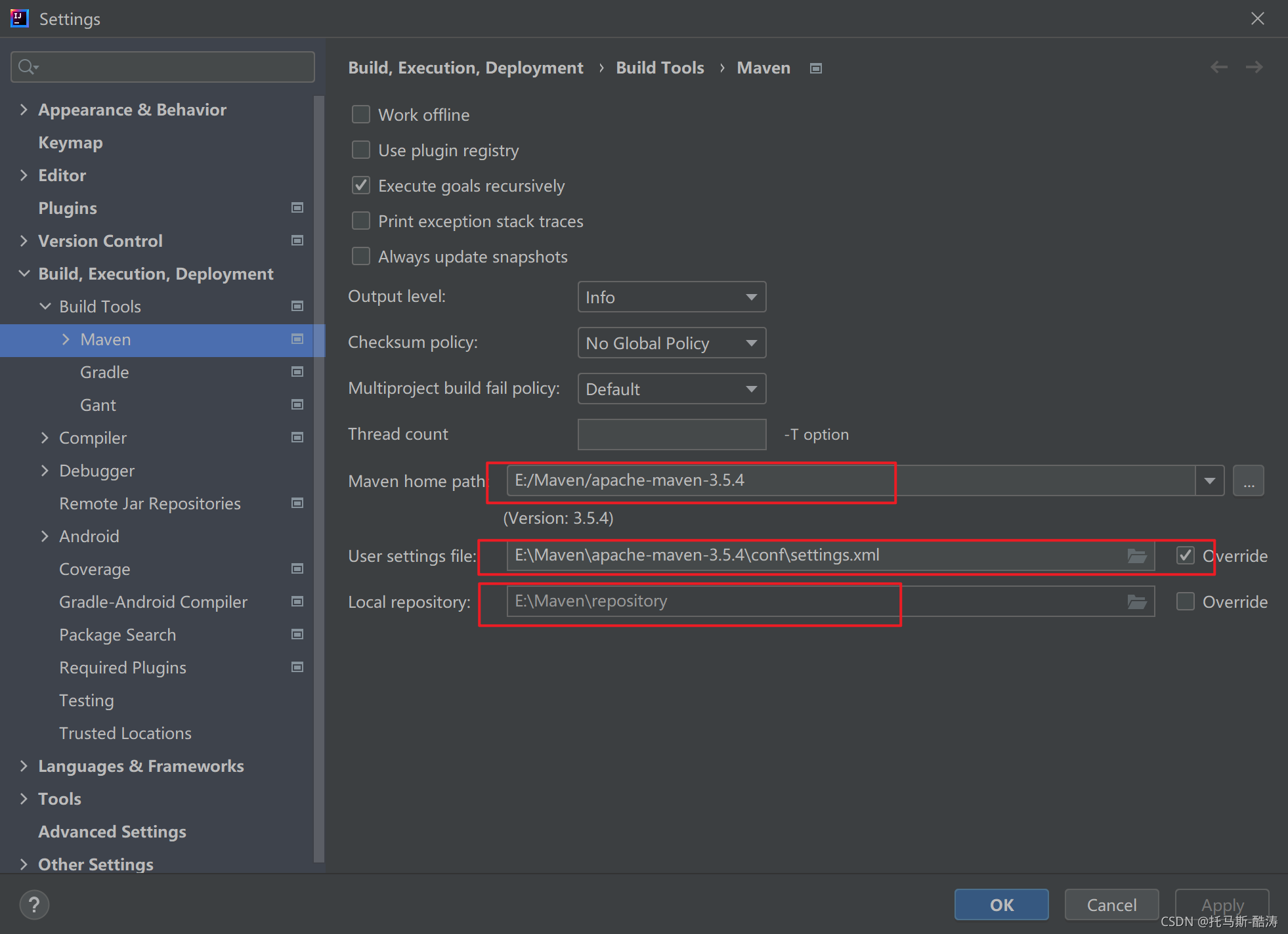
1.配置maven
将下载好的maven路径配置进去
2.配置解释器
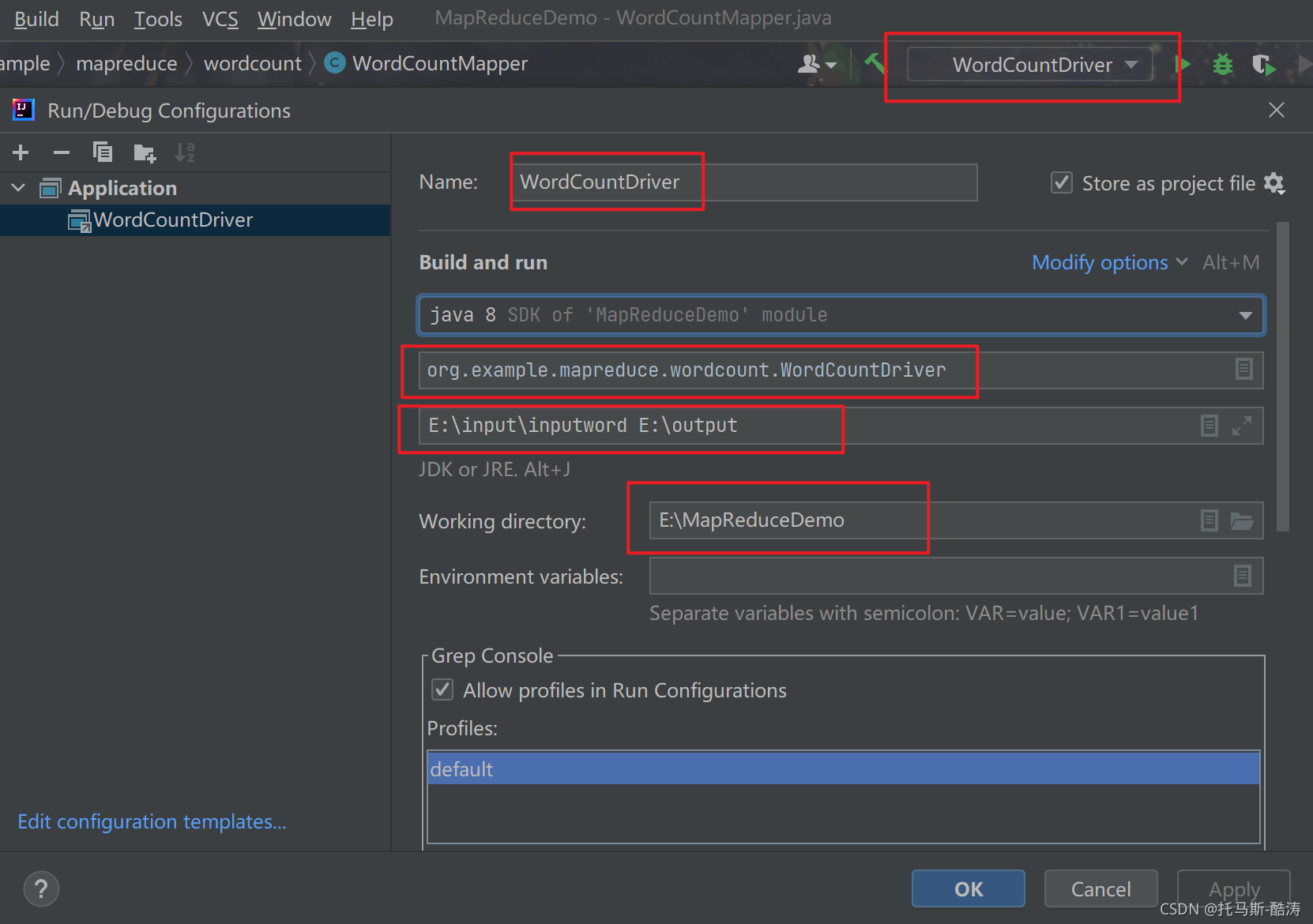
3.在pom.xml文件中添加如下依赖
如下依赖只需要更改版本号即可,导入后刷新IDEA即可自动下载依赖
-
<dependencies>
-
<dependency>
-
<groupId>junit</groupId>
-
<artifactId>junit</artifactId>
-
<version>RELEASE</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.logging.log4j</groupId>
-
<artifactId>log4j-core</artifactId>
-
<version>2.8.2</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.hadoop</groupId>
-
<artifactId>hadoop-common</artifactId>
-
<version>2.7.2</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.hadoop</groupId>
-
<artifactId>hadoop-client</artifactId>
-
<version>2.7.2</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.hadoop</groupId>
-
<artifactId>hadoop-hdfs</artifactId>
-
<version>2.7.2</version>
-
</dependency>
-
</dependencies>
4.在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
-
log4j.rootLogger=INFO, stdout
-
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
-
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
-
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
-
log4j.appender.logfile=org.apache.log4j.FileAppender
-
log4j.appender.logfile.File=target/spring.log
-
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
-
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
程序编写:
(1)编写Mapper类
-
package org.example.mapreduce.wordcount;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.LongWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Mapper;
-
-
import java.io.IOException;
-
-
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
-
private Text outk = new Text();
-
private IntWritable outv = new IntWritable(1);
-
-
@Override
-
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
-
//获取一行
-
String line = value.toString();
-
//切割
-
String[] words = line.split(" ");
-
//循环写出
-
for (String word : words) {
-
//封装
-
outk.set(word);
-
//写出
-
context.write(outk, outv);
-
}
-
}
-
}
(2)编写Reducer类
-
package org.example.mapreduce.wordcount;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Reducer;
-
-
import java.io.IOException;
-
-
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
-
IntWritable outV = new IntWritable();
-
-
@Override
-
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
-
int sum = 0;
-
//tuomasi(1,1)
-
//累加
-
for (IntWritable value : values) {
-
sum += value.get();
-
}
-
//写出
-
outV.set(sum);
-
-
context.write(key, outV);
-
}
-
}
(3)编写Driver类
-
package org.example.mapreduce.wordcount;
-
-
import org.apache.hadoop.conf.Configuration;
-
import org.apache.hadoop.fs.Path;
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Job;
-
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
-
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
-
-
-
import java.io.IOException;
-
-
public class WordCountDriver {
-
public static void main(String[] args) throws IOException, ClassNotFoundException ,InterruptedException{
-
//1.获取job
-
Configuration conf = new Configuration();
-
Job job = Job.getInstance(conf);
-
-
//2.设置jor包路径
-
job.setJarByClass(WordCountDriver.class);
-
-
//3.关联mapper和reducer
-
job.setMapperClass(WordCountMapper.class);
-
job.setReducerClass(WordCountReducer.class);
-
-
//4.设置mapper输出的k,v类型
-
job.setMapOutputKeyClass(Text.class);
-
job.setMapOutputValueClass(IntWritable.class);
-
-
//5.设置最终输出的K,V类型
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(IntWritable.class);
-
-
//6.设置输入路径和输出路径
-
FileInputFormat.setInputPaths(job, new Path("E:\\input\\inputword"));
-
FileOutputFormat.setOutputPath(job, new Path("E:\\output\\outputword"));
-
-
//7.提交job作业
-
boolean result = job.waitForCompletion(true);
-
System.exit(result ? 0 : 1);
-
-
}
-
}
本地测试:

注意:此处输出路径不能在运行前存在(提前存在会报错),运行后会自动生成
运行:
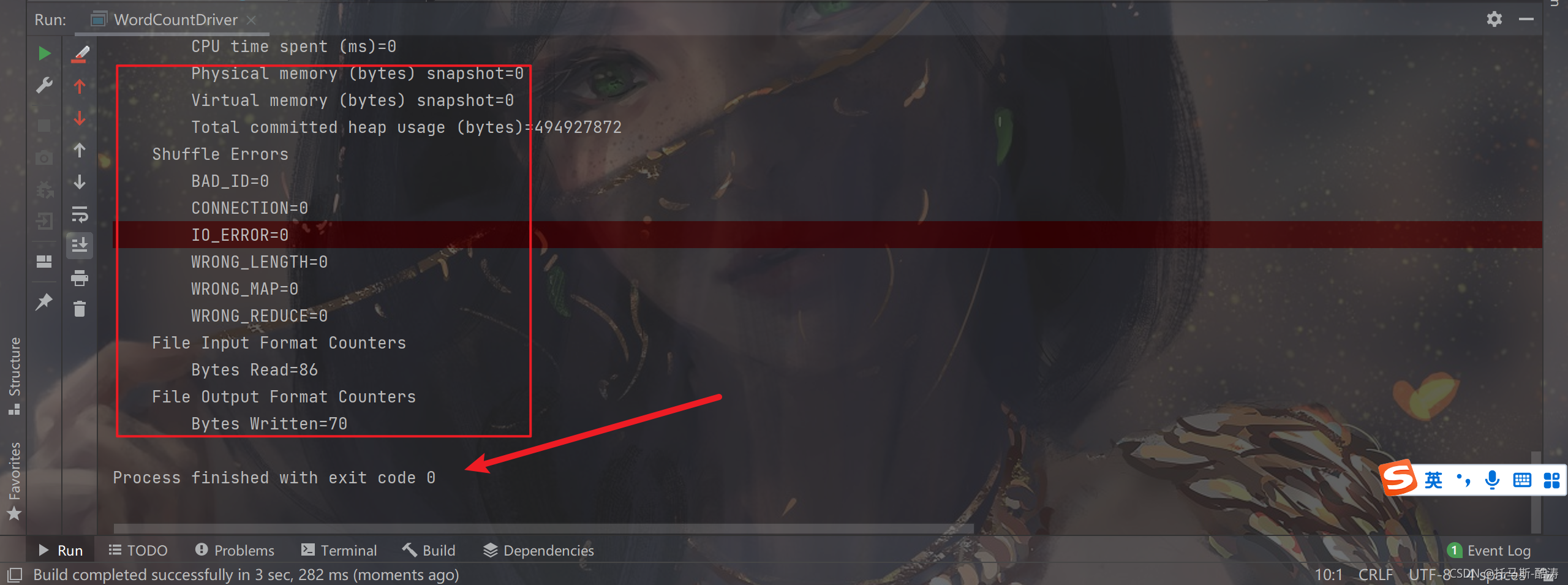
如图所示即为运行成功。
找到本地生成的文件,查看是否与期望值相同,如图:
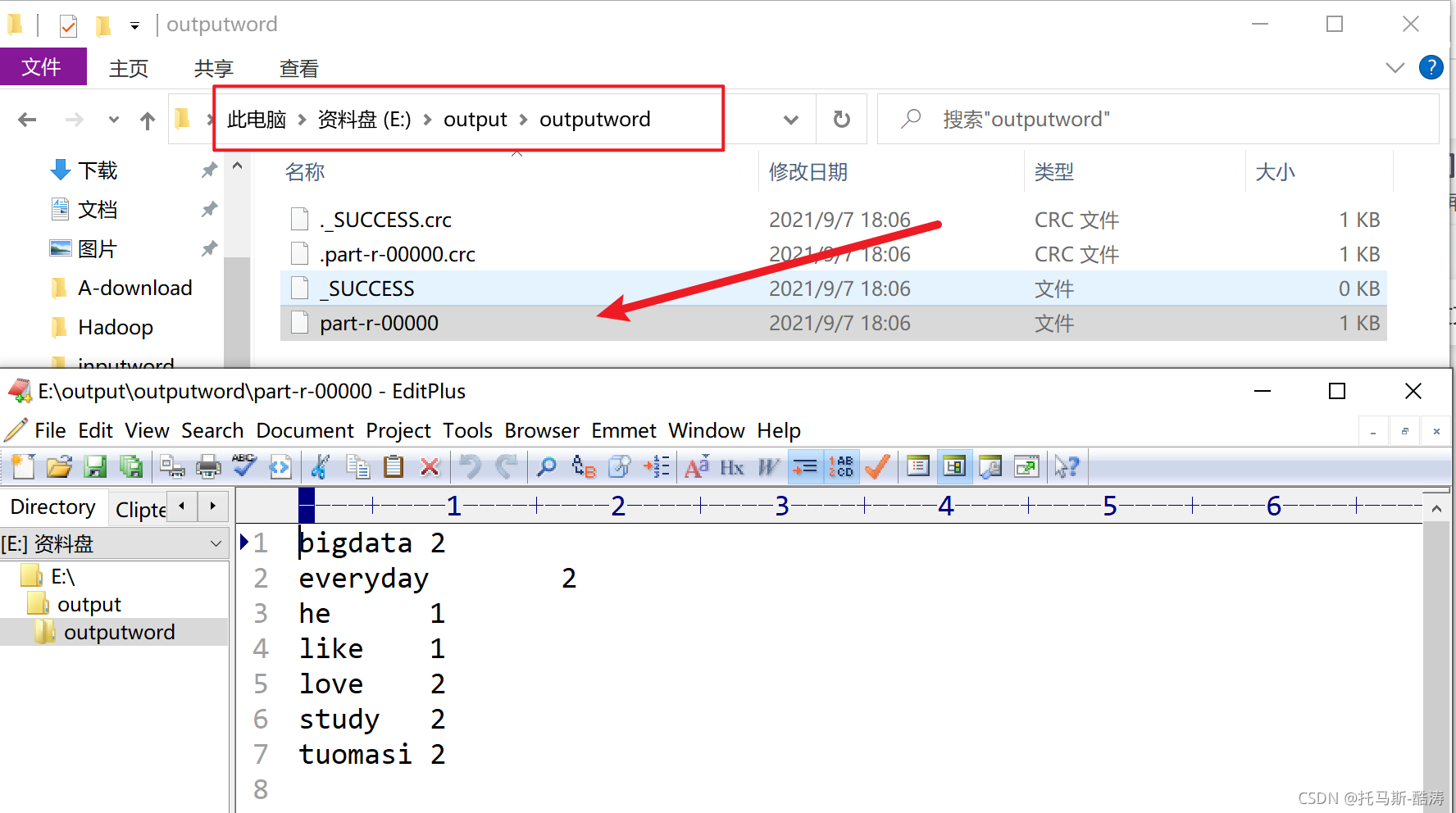
涉及到的问题:
注意:在第一次运行可能会报缺少winutils错误,只需下载对应版本的winutils.exe文件解压到本地,配置Hadoop的环境变量即可
我的Hadoop为2.6.0版即使用如下包,提取码:0000 下方链接:
https://pan.baidu.com/s/1CMgma_VoO2mJ6iRROd7HCg
或:
https://download.csdn.net/download/m0_54925305/22011870?spm=1001.2014.3001.5501

环境变量:
1.配置系统变量HADOOP_HOME,路径指向hadoop-common-2.6.0-bin-master
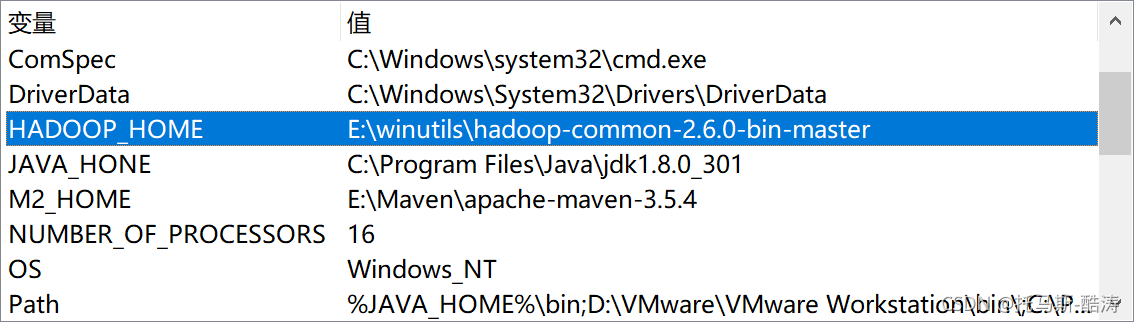
2.Path配置,加入:%HADOOP_HOME%\bin

友情提示:
如遇代码运行过程中有多处警告或报错大多都是因为导包出错的,请仔细查看包是否导入正确。
环境搭建及WordCount案例完成。
文章来源: tuomasi.blog.csdn.net,作者:托马斯-酷涛,版权归原作者所有,如需转载,请联系作者。
原文链接:tuomasi.blog.csdn.net/article/details/120155693

- 点赞
- 收藏
- 关注作者
评论(0)