六十七、Spark-两种运行方式(本地运行,提交集群运行)

【摘要】
本地运行:在IDEA中直接运行控制台输出结果即可
集群运行:在本地将程序打包为 jar,提交至集群运行其程序(将结果上传至hdfs)
文章目录
一、本地运行spark程序
二、集群运行spark程序
一、本地运行spark程序
 ...
本地运行:在IDEA中直接运行控制台输出结果即可
集群运行:在本地将程序打包为 jar,提交至集群运行其程序(将结果上传至hdfs)
文章目录
一、本地运行spark程序
1、pom依赖
注:依赖配置项及其版本一定要与集群环境相适配
-
<?xml version="1.0" encoding="UTF-8"?>
-
<project xmlns="http://maven.apache.org/POM/4.0.0"
-
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
-
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
-
<modelVersion>4.0.0</modelVersion>
-
-
<groupId>cn.itcast</groupId>
-
<artifactId>SparkDemo</artifactId>
-
<version>1.0-SNAPSHOT</version>
-
-
<repositories>
-
<repository>
-
<id>aliyun</id>
-
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
-
</repository>
-
<repository>
-
<id>apache</id>
-
<url>https://repository.apache.org/content/repositories/snapshots/</url>
-
</repository>
-
<repository>
-
<id>cloudera</id>
-
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
-
</repository>
-
</repositories>
-
<properties>
-
<encoding>UTF-8</encoding>
-
<maven.compiler.source>1.8</maven.compiler.source>
-
<maven.compiler.target>1.8</maven.compiler.target>
-
<scala.version>2.12.11</scala.version>
-
<spark.version>3.0.1</spark.version>
-
<hadoop.version>2.7.5</hadoop.version>
-
</properties>
-
<dependencies>
-
<!--依赖Scala语言-->
-
<dependency>
-
<groupId>org.scala-lang</groupId>
-
<artifactId>scala-library</artifactId>
-
<version>${scala.version}</version>
-
</dependency>
-
-
<!--SparkCore依赖-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-core_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<!-- spark-streaming-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-streaming_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<!--spark-streaming+Kafka依赖-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<!--SparkSQL依赖-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-sql_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<!--SparkSQL+ Hive依赖-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-hive_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-hive-thriftserver_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<!--StructuredStreaming+Kafka依赖-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<!-- SparkMlLib机器学习模块,里面有ALS推荐算法-->
-
<dependency>
-
<groupId>org.apache.spark</groupId>
-
<artifactId>spark-mllib_2.12</artifactId>
-
<version>${spark.version}</version>
-
</dependency>
-
-
<dependency>
-
<groupId>org.apache.hadoop</groupId>
-
<artifactId>hadoop-client</artifactId>
-
<version>2.7.5</version>
-
</dependency>
-
-
<dependency>
-
<groupId>com.hankcs</groupId>
-
<artifactId>hanlp</artifactId>
-
<version>portable-1.7.7</version>
-
</dependency>
-
-
<dependency>
-
<groupId>mysql</groupId>
-
<artifactId>mysql-connector-java</artifactId>
-
<version>8.0.23</version>
-
</dependency>
-
-
<dependency>
-
<groupId>redis.clients</groupId>
-
<artifactId>jedis</artifactId>
-
<version>2.9.0</version>
-
</dependency>
-
-
<dependency>
-
<groupId>com.alibaba</groupId>
-
<artifactId>fastjson</artifactId>
-
<version>1.2.47</version>
-
</dependency>
-
-
<dependency>
-
<groupId>org.projectlombok</groupId>
-
<artifactId>lombok</artifactId>
-
<version>1.18.2</version>
-
<scope>provided</scope>
-
</dependency>
-
</dependencies>
-
-
<build>
-
<sourceDirectory>src/main/scala</sourceDirectory>
-
<plugins>
-
<!-- 指定编译java的插件 -->
-
<plugin>
-
<groupId>org.apache.maven.plugins</groupId>
-
<artifactId>maven-compiler-plugin</artifactId>
-
<version>3.5.1</version>
-
</plugin>
-
<!-- 指定编译scala的插件 -->
-
<plugin>
-
<groupId>net.alchim31.maven</groupId>
-
<artifactId>scala-maven-plugin</artifactId>
-
<version>3.2.2</version>
-
<executions>
-
<execution>
-
<goals>
-
<goal>compile</goal>
-
<goal>testCompile</goal>
-
</goals>
-
<configuration>
-
<args>
-
<arg>-dependencyfile</arg>
-
<arg>${project.build.directory}/.scala_dependencies</arg>
-
</args>
-
</configuration>
-
</execution>
-
</executions>
-
</plugin>
-
<plugin>
-
<groupId>org.apache.maven.plugins</groupId>
-
<artifactId>maven-surefire-plugin</artifactId>
-
<version>2.18.1</version>
-
<configuration>
-
<useFile>false</useFile>
-
<disableXmlReport>true</disableXmlReport>
-
<includes>
-
<include>**/*Test.*</include>
-
<include>**/*Suite.*</include>
-
</includes>
-
</configuration>
-
</plugin>
-
<plugin>
-
<groupId>org.apache.maven.plugins</groupId>
-
<artifactId>maven-shade-plugin</artifactId>
-
<version>2.3</version>
-
<executions>
-
<execution>
-
<phase>package</phase>
-
<goals>
-
<goal>shade</goal>
-
</goals>
-
<configuration>
-
<filters>
-
<filter>
-
<artifact>*:*</artifact>
-
<excludes>
-
<exclude>META-INF/*.SF</exclude>
-
<exclude>META-INF/*.DSA</exclude>
-
<exclude>META-INF/*.RSA</exclude>
-
</excludes>
-
</filter>
-
</filters>
-
<transformers>
-
<transformer
-
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
-
<mainClass></mainClass>
-
</transformer>
-
</transformers>
-
</configuration>
-
</execution>
-
</executions>
-
</plugin>
-
</plugins>
-
</build>
-
</project>
2、数据展示

3、代码编写
-
package org.example.spark
-
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.{SparkConf, SparkContext}
-
-
object word {
-
def main(args: Array[String]): Unit = {
-
//准备环境
-
val conf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
-
val sc = new SparkContext(conf)
-
-
//加载文件
-
val rdd1: RDD[String] = sc.textFile("data/input/words.txt")
-
-
// 处理数据
-
val rdd2: RDD[String] = rdd1.flatMap(lp => {
-
lp.split(" ")
-
})
-
-
val rdd3: RDD[(String, Int)] = rdd2.map(it => (it, 1))
-
-
val rdd4: RDD[(String, Int)] = rdd3.reduceByKey((curr, agg) => curr + agg)
-
-
val result: Array[(String, Int)] = rdd4.collect()
-
-
result.foreach(i => println(i))
-
-
-
}
-
}
4、本地运行
注:单词统计案例本地效果如图所示
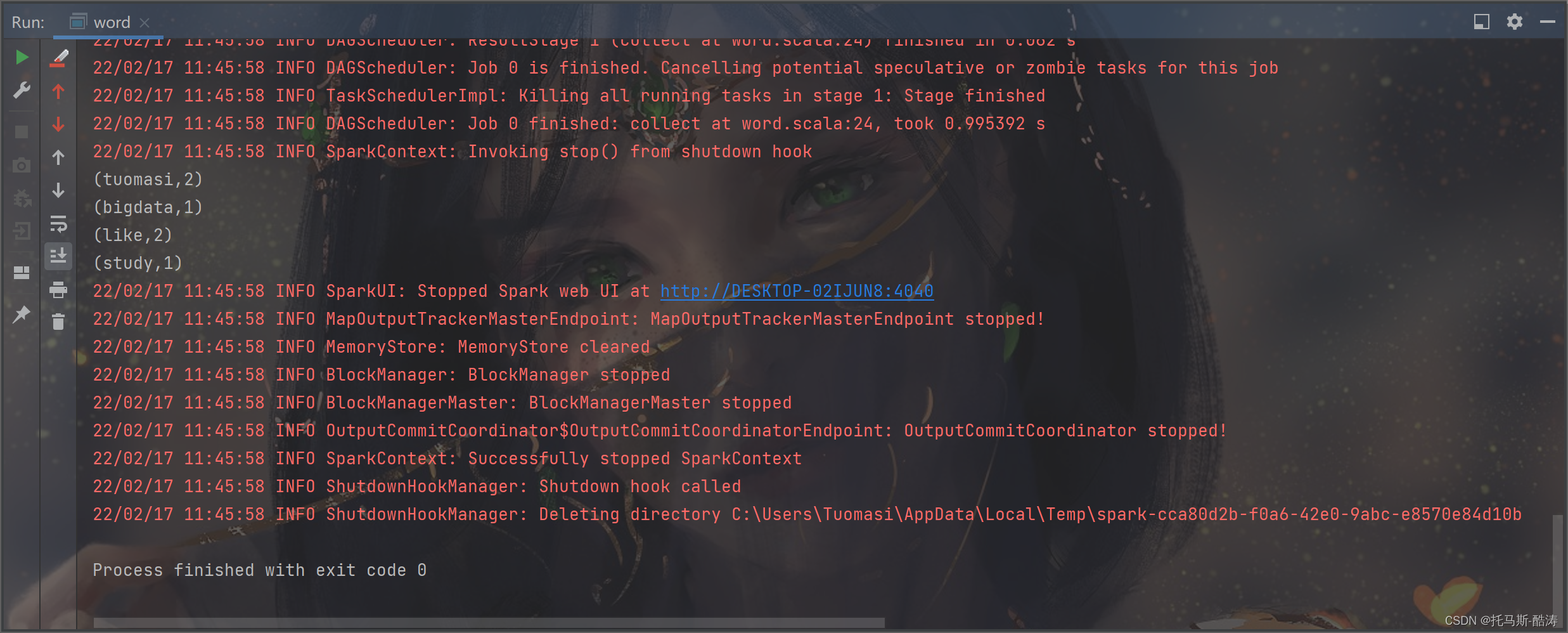
二、集群运行spark程序
1、修改代码
val rdd1: RDD[String] = sc.textFile("hdfs:///input/wordcount.txt")
rdd4.saveAsTextFile("hdfs://192.168.231.247:8020/output/output1")
注:集群运行文件加载路径设置为hdfs,即每次集群运行从hdfs拿取数据,并将实时数据上传至hdfs
2、打包jar
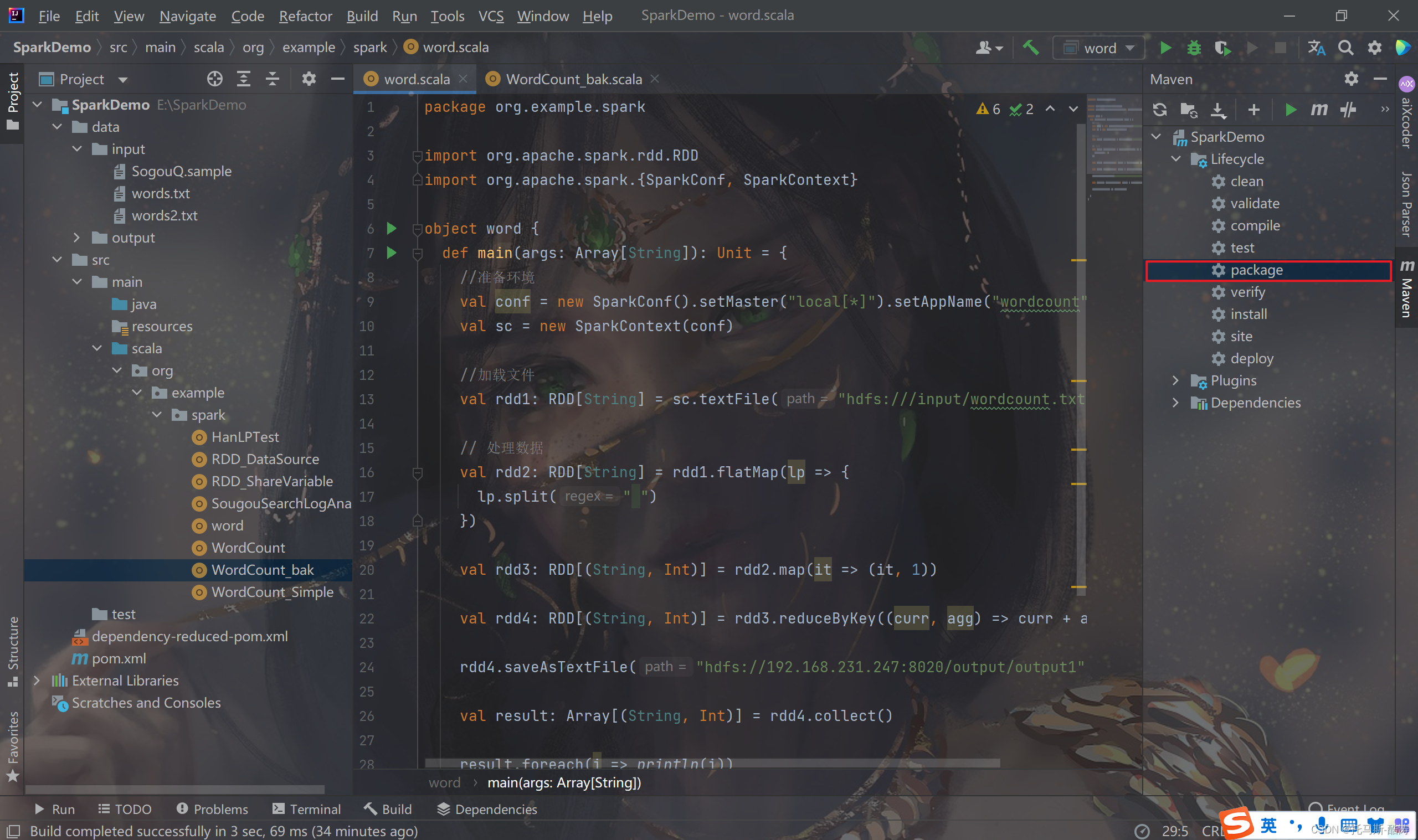
注:双击maven中的package,maven会自动进行清除缓存,测试并打包为jar
3、找到项目路径中的jar包
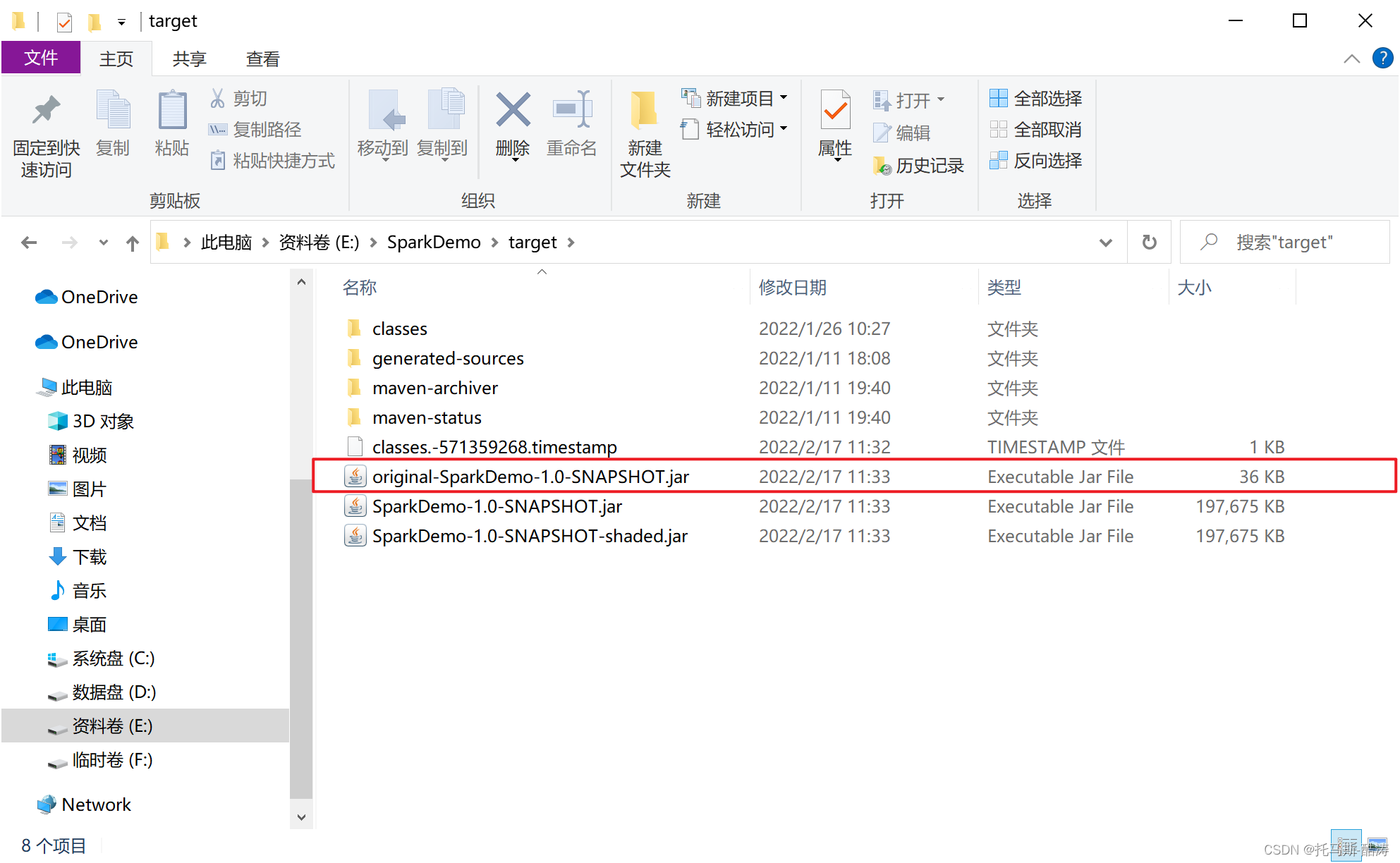
注:jar包大小最小的为不是带全部依赖的jar包,在集群运行不需要全部的依赖,即上传最小依赖的jar包即可
4、上传至linux
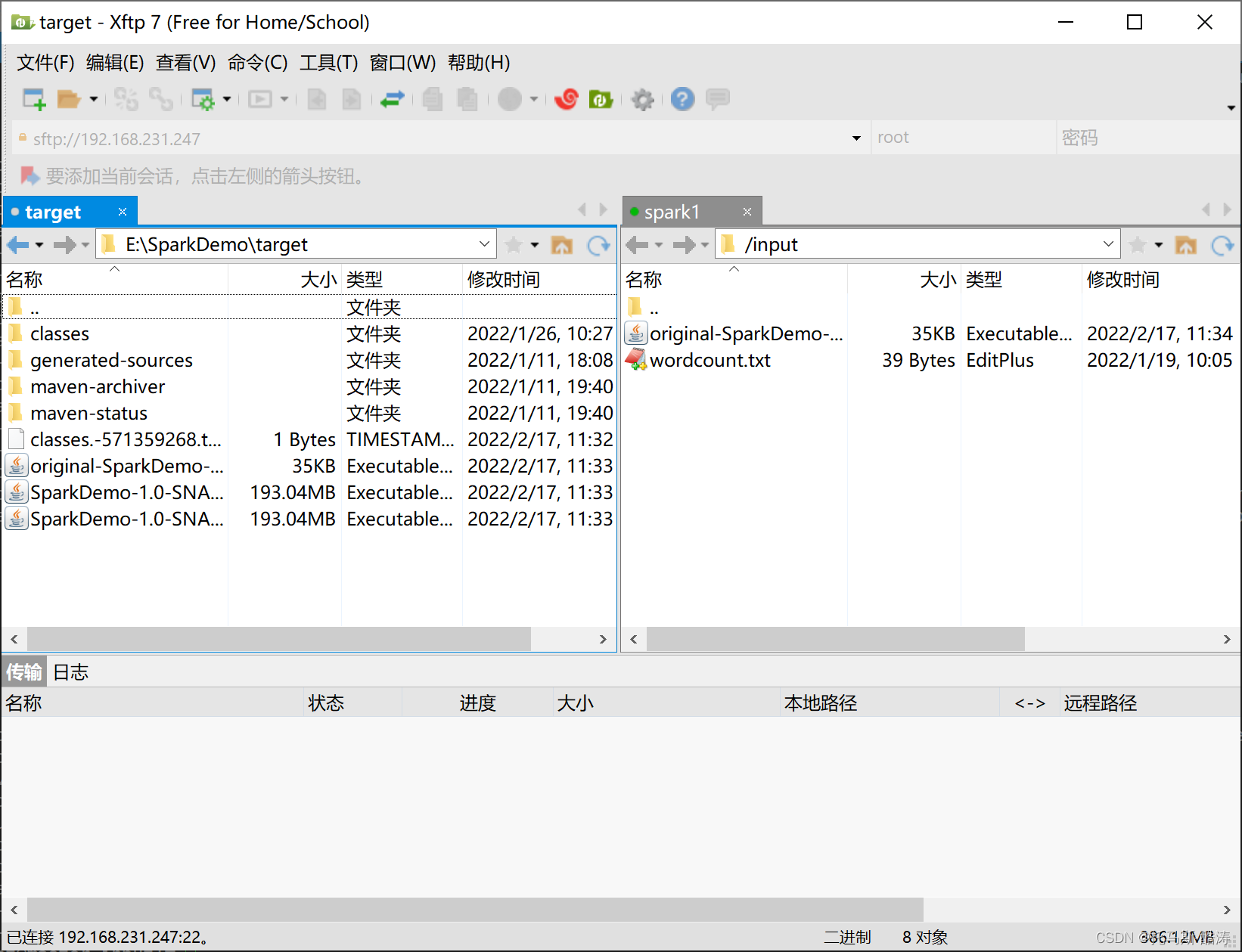
注:此处使用xftp进行传输 jar包
5、启动 hadoop 以及 spark 集群

6、进入spark安装目录下执行
bin/spark-submit --class org.example.spark.word --master spark://master:8020 /input/original-SparkDemo-1.0-SNAPSHOT.jar
注:单词统计集群运行如图所示

7、进入hdfs web端目录进行查看
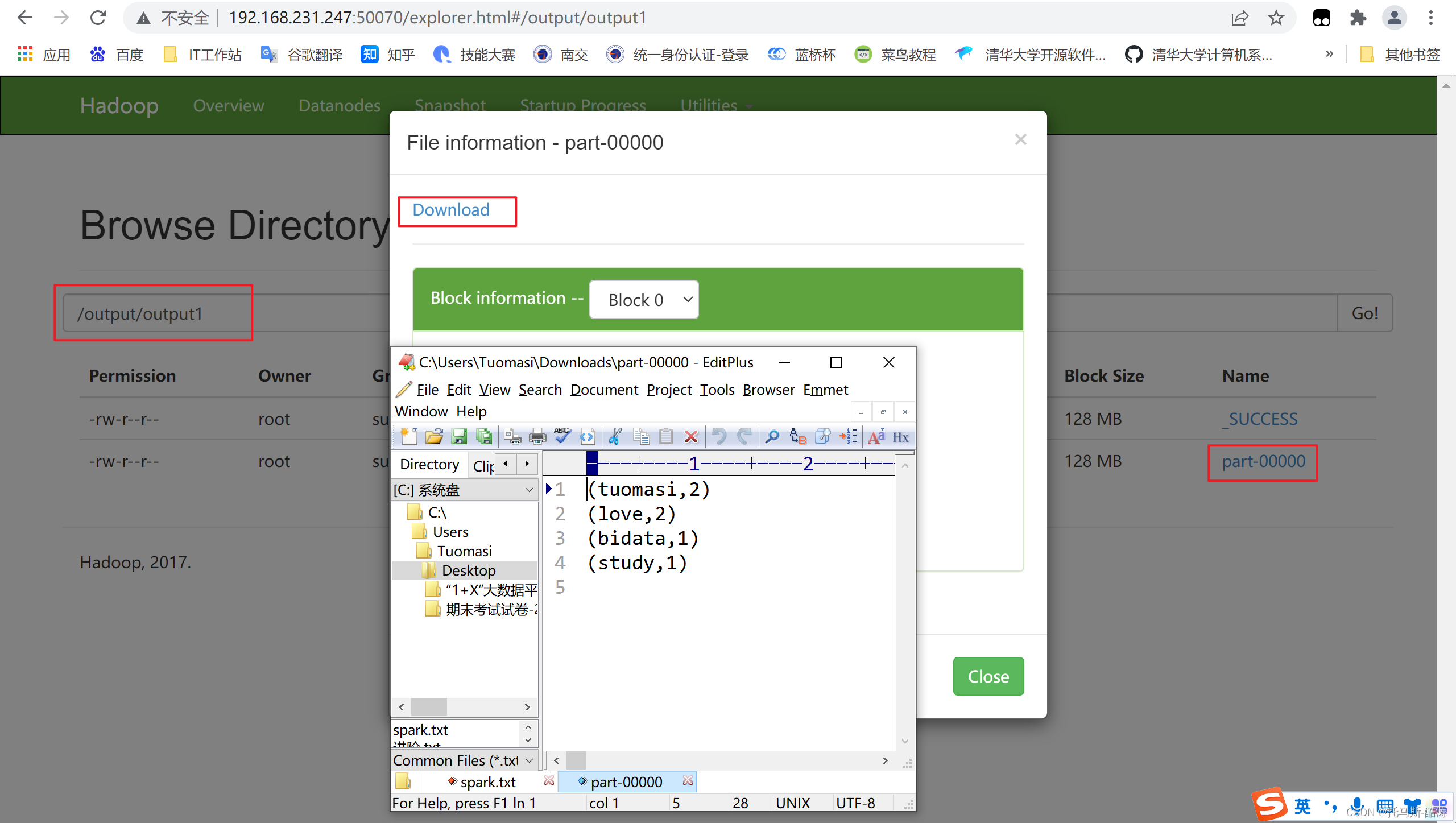
Spark-两种运行方式(本地运行,提交集群运行)完成
文章来源: tuomasi.blog.csdn.net,作者:托马斯-酷涛,版权归原作者所有,如需转载,请联系作者。
原文链接:tuomasi.blog.csdn.net/article/details/122919106

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)