九十一、Spark-SparkSQL(多数据源处理)

【摘要】
读取JSON文件,以JSON,CSV,jdbc格式写出
数据展示
代码
package org.example.SQL import org.apache.log4j.{Level, Logger}import org.apache.spark.sql.{DataFrame, SaveMode, SparkSes...
读取JSON文件,以JSON,CSV,jdbc格式写出
数据展示
代码
-
package org.example.SQL
-
-
import org.apache.log4j.{Level, Logger}
-
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
-
-
import java.util.Properties
-
-
object sql_DataSource { //支持外部数据源
-
//支持的文件数据格式:text/json/csv/parquet/orc...
-
def main(args: Array[String]): Unit = {
-
//不打印日志
-
Logger.getLogger("org").setLevel(Level.ERROR)
-
val spark: SparkSession = SparkSession.builder().appName("test2")
-
.master("local[*]").getOrCreate()
-
val sc = spark.sparkContext
-
-
val df1: DataFrame = spark.read.json("data/input/json")
-
-
df1.printSchema()
-
df1.show()
-
df1.coalesce(1).write.mode(SaveMode.Overwrite).json("data/output/json")
-
df1.coalesce(1).write.mode(SaveMode.Overwrite).csv("data/output/csv")
-
val prop = new Properties()
-
prop.setProperty("user", "root")
-
prop.setProperty("password", "123456")
-
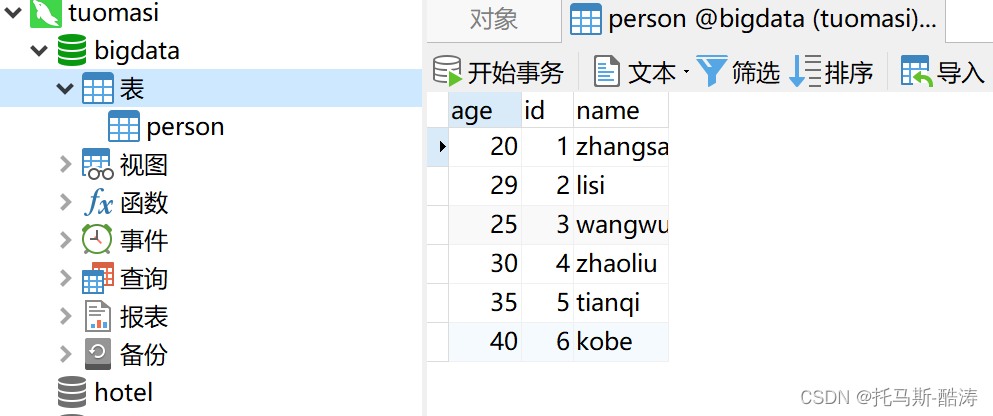
df1.coalesce(1).write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "person", prop)
-
//如果没有,表自动创建
-
-
spark.stop()
-
-
}
-
}
约束
-
root
-
|-- age: long (nullable = true)
-
|-- id: long (nullable = true)
-
|-- name: string (nullable = true)
数据打印
-
+---+---+--------+
-
|age| id| name|
-
+---+---+--------+
-
| 20| 1|zhangsan|
-
| 29| 2| lisi|
-
| 25| 3| wangwu|
-
| 30| 4| zhaoliu|
-
| 35| 5| tianqi|
-
| 40| 6| kobe|
-
+---+---+--------+
结果文件输出
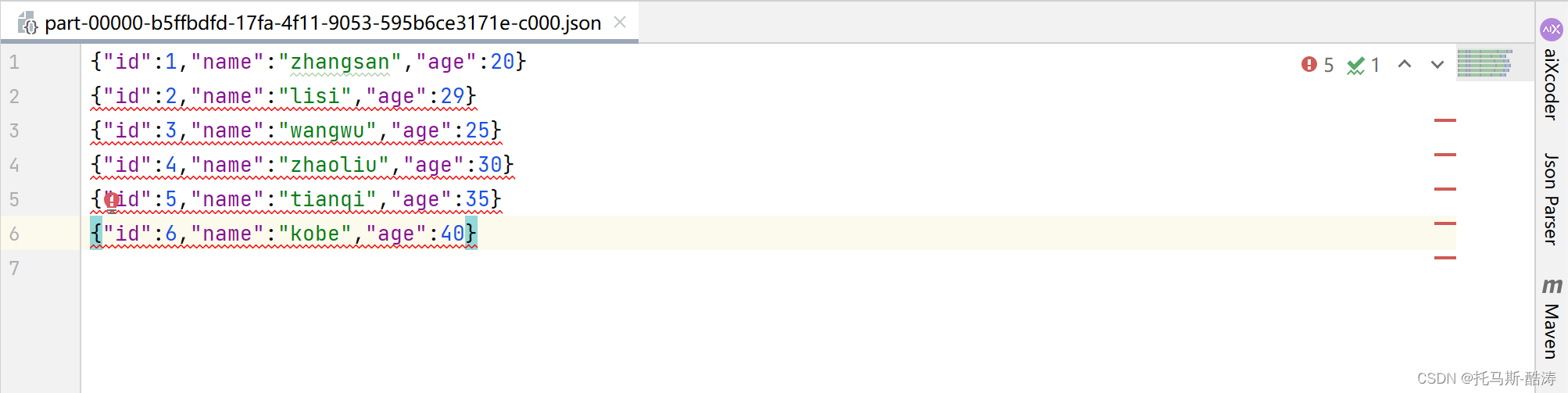
json
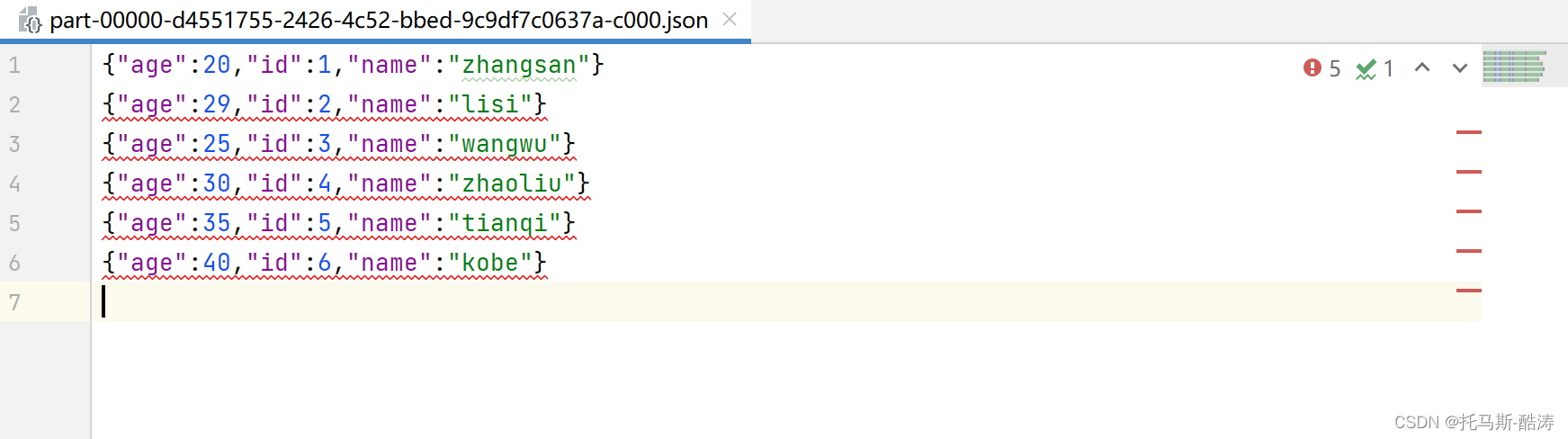
csv
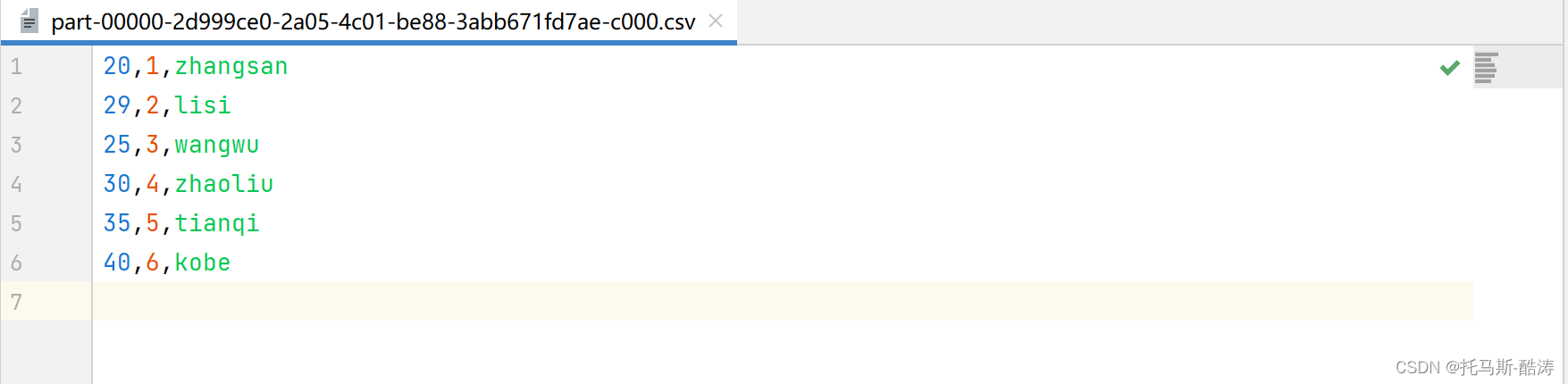
jdbc
文章来源: tuomasi.blog.csdn.net,作者:托马斯-酷涛,版权归原作者所有,如需转载,请联系作者。
原文链接:tuomasi.blog.csdn.net/article/details/124018945

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)