五十、Spark组件部署(MINI版)

前景连接:
环境准备:
| 编号 | 主机名 | 类型 | 用户 | 密码 |
|---|---|---|---|---|
| 1 | master1-1 | 主节点 | root | passwd |
| 2 | slave1-1 | 从节点 | root | passwd |
| 3 | slave1-2 | 从节点 | root | passwd |
注:提取码均为:0000
环境部署:
一、需前置 Hadoop 环境,并检查 Hadoop 环境是否可用,截图并保存结果
1、使用 jps 命令查看集群状态



二、解压 scala 安装包到“/usr/local/src”路径下,并更名为 scala,截图并保存结果
1、进入/h3cu/目录下找到压缩包
cd /h3cu/

2、解压scala
tar -zxvf scala-2.11.8.tgz -C /usr/local/src
3、重命名scala
mv scala-2.11.8 scala

三、 设置 scala 环境变量,并使环境变量只对当前用户生效,截图并保存结果
1、添加scala环境变量
vi /root/.bashrc

2、使环境变量立即生效
source /root/.bashrc
四、进入 scala 并截图,截图并保存结果
1、输入命令 scala 进入scala界面

五、解压 Spark 安装包到“/usr/local/src”路径下,并更名为 spark,截图并保存结果
1、退出scala界面
使用ctrl + c 键退出scala界面

2、进入/h3cu/目录找到Spark
cd /h3cu/

3、解压Spark
tar -zxvf spark-2.0.0-bin-hadoop2.7.tgz -C /usr/local/src/
4、重命名Spark
mv spark-2.0.0-bin-hadoop2.7 spark

六、设置 Spark 环境变量,并使环境变量只对当前用户生效,截图并保存结果
1、添加Spark环境变量
vi /root/.bashrc

2、使环境变量立即生效
source /root/.bashrc
七、修改 Spark 参数配置,指定 Spark slave 节点,截图并保存结果
1、进入/usr/local/src/spark/conf目录
cd /usr/local/src/spark/conf
2、新建slaves文件并写入
vi slaves
注:该文件内容不可多无用空格或其他字符,严格遵守规范

3、新建spark-env.sh文件并写入
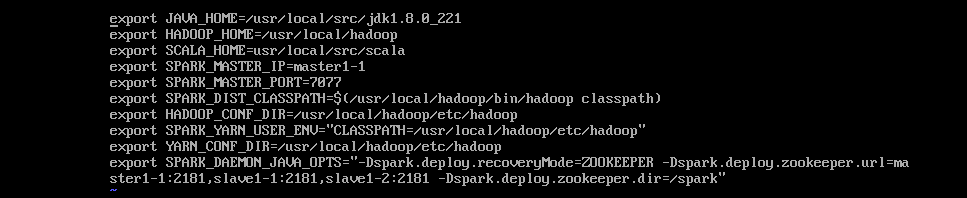
vi spark-env.sh
注:其中,三个参数的意义分别为: SPARK_DIST_CLASSPATH 是完成 spark 和 hadoop 的挂接,HADOOP_CONF_DIR 是说明了 hadoop 相关配置信息的目录, SPARK_MASTER_IP 是指明该集群中主节点的 IP 地址或者名称
4、集群分发
-
scp -r /usr/local/src/spark slave1-1:/usr/local/src/
-
scp -r /usr/local/src/spark slave1-2:/usr/local/src/
-
scp -r /root/.bashrc slave1-1:/root/.bashrc
-
scp -r /root/.bashrc slave1-2:/root/.bashrc
5、确保所有机器环境变量已经生效
source /root/.bashrc注:三台机器均需执行
八、启动 Spark,并使用命令查看 webUI 结果,截图并保存结果
1、进入spark安装目录下启动spark
sbin/start-all.sh
注:确保zookeeper已经正常启动



2、浏览器输入master1-1:8080查看web UI

3、slave端启动master
sbin/start-master.sh
注:通过观察可知,主节点的 Master 状态为活动状态,从节点的Master状态为备用状态,即为集群成功运行

Spark组件部署(MINI版)完成
不能打败你的必将使你愈发强大!
文章来源: tuomasi.blog.csdn.net,作者:托马斯-酷涛,版权归原作者所有,如需转载,请联系作者。
原文链接:tuomasi.blog.csdn.net/article/details/121615781

- 点赞
- 收藏
- 关注作者
评论(0)