利用pandas将多张表按照行索引横向连接到一起,concat的用法

【摘要】
比如将如下12个月份如图一的表合并成合并成图二的表(这里我已经将inst_id设置为索引,之后都是以它连接)
这里使用concat连接
...
比如将如下12个月份如图一的表合并成合并成图二的表(这里我已经将inst_id设置为索引,之后都是以它连接)
这里使用concat连接
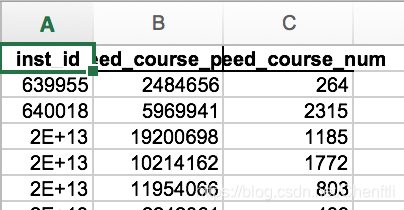
图一

图二
-
import pandas as pd
-
import numpy as np
-
-
# 读取excel
-
df1 = pd.read_excel('合同1.xls')
-
# 将sinst_id的数据类型转化成string类型
-
df1['sinst_id'] = df1.sinst_id.astype(np.str)
-
# 将sinst_id设置成行索引
-
df1 = df1.set_index('sinst_id')
-
-
df2 = pd.read_excel('合同2.xls')
-
df2['sinst_id'] = df2.sinst_id.astype(np.str)
-
df2 = df2.set_index('sinst_id')
-
-
df3 = pd.read_excel('合同3.xls')
-
df3['sinst_id'] = df3.sinst_id.astype(np.str)
-
df3 = df3.set_index('sinst_id')
-
-
df4 = pd.read_excel('合同4.xls')
-
df4['sinst_id'] = df4.sinst_id.astype(np.str)
-
df4 = df4.set_index('sinst_id')
-
-
df5 = pd.read_excel('合同5.xls')
-
df5['sinst_id'] = df5.sinst_id.astype(np.str)
-
df5 = df5.set_index('sinst_id')
-
-
df6 = pd.read_excel('合同6.xls')
-
df6['sinst_id'] = df6.sinst_id.astype(np.str)
-
df6 = df6.set_index('sinst_id')
-
-
df7 = pd.read_excel('合同7.xls')
-
df7['sinst_id'] = df7.sinst_id.astype(np.str)
-
df7 = df7.set_index('sinst_id')
-
-
df8 = pd.read_excel('合同8.xls')
-
df8['sinst_id'] = df8.sinst_id.astype(np.str)
-
df8 = df8.set_index('sinst_id')
-
-
df9 = pd.read_excel('合同9.xls')
-
df9['sinst_id'] = df9.sinst_id.astype(np.str)
-
df9 = df9.set_index('sinst_id')
-
-
df10 = pd.read_excel('合同10.xls')
-
df10['sinst_id'] = df10.sinst_id.astype(np.str)
-
df10 = df10.set_index('sinst_id')
-
-
df11 = pd.read_excel('合同11.xls')
-
df11['sinst_id'] = df11.sinst_id.astype(np.str)
-
df11 = df11.set_index('sinst_id')
-
-
df12 = pd.read_excel('合同12.xls')
-
df12['sinst_id'] = df12.sinst_id.astype(np.str)
-
df12 = df12.set_index('sinst_id')
-
-
-
frames = [df1, df2, df3, df4, df5, df6, df7, df8, df9, df10, df11, df12]
-
-
# 连接表axis=1时是表横向连接,keys可以设置连接后的列索引,join为外连接
-
result = pd.concat(frames, axis=1, keys=['{}月'.format(i) for i in range(1, 13)], join='outer')
-
-
print(result)
-
-
# 存储进excel,index=True时,存储索引,header是存储以前的行索引
-
result.to_excel('合同总.xls', sheet_name='Sheet1', index=True, header=True)
注意:pandas对于长整型的数据在存储excel是要进行强制类型转化,可能会丢失精度(此外在读取数据库数据时也可能出现问题)所以最好将数据类型转化成string类型时再存储。
文章来源: blog.csdn.net,作者:橙子园,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/Chenftli/article/details/84791771

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)