java操作ElasticSearch(包含增删改查及基础语法操作)

ElasticSearch流程图
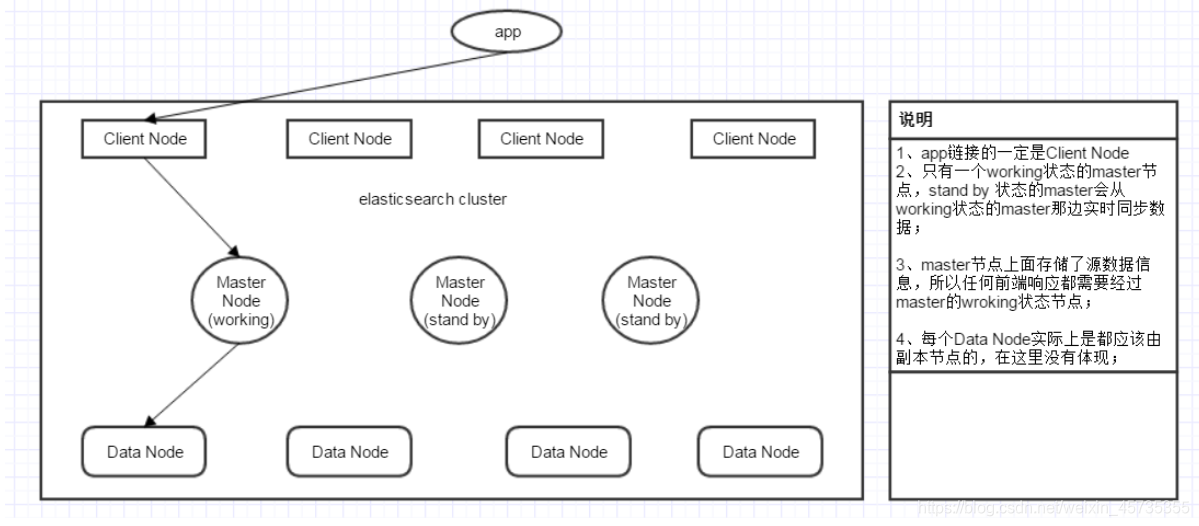
ElasticSearch简介
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎
ElasticSearch环境搭建
引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>x-pack-transport</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
初始化客户端
跟操作数据库一样,写入地址、账号密码,获取一个客户端,有兴趣的可以看org.springframework.data.elasticsearch.client.ClusterNodesspring boot是怎么解析集群的
private TransportClient client;
private String[] nodes = new String[]{"127.0.0.1:9200"};
@Before
public void initClint() {
Settings settings = Settings.builder()
// es 集群的名称
.put("cluster.name", "elasticsearch")
.put("client.transport.sniff", "true")
//账号密码
.put("xpack.security.user", "elastic:123456")
.build();
client = new PreBuiltXPackTransportClient(settings)
//添加集群节点
.addTransportAddresses(parseAddress());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
创建索引
可以理解为创建一个mysql数据库表
@Test
public void createIndex() {
client.admin()
.indices()
.prepareCreate("elastic").get();
client.close();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
设置mappings
mappings可以理解为mysql的表字段(json数据)
对应的json格式:
{
"properties": {
"id": {
"type": "long",
"store": true
},
"name": {
"type": "text",
"store": true
},
"age": {
"type": "integer",
"store": true
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
对应的Java格式:
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject() // 相当于json的'{'
.startObject("properties")
.startObject("id")
.field("type", "long") //字段类型
.field("store", true) //是否存储
.endObject() //相当于json的'}'
.startObject("name")
.field("type", "text")
.field("store", true)
.field("analyzer", "ik_smart") //采用ik_smart分词 "search_analyzer": "ik_smart"
.endObject()
.startObject("age")
.field("type", "integer")
.field("store", true)
.endObject()
.startObject("desc")
.field("type", "text")
.field("store", true)
.field("analyzer", "ik_max_word")
.endObject()
.startObject("registerTime")
.field("type", "date")
.field("store", true)
.field("format", "yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
.endObject()
.endObject()
.endObject();
client.admin().indices()
.preparePutMapping("elastic")
.setType("user") //对应数据库的表名称
.setSource(builder)
.get();
client.close();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
基础语法
1.1常用查询
1、查询全部:match_all
2、模糊匹配: match (类似sql 的 like)
3、全句匹配: match_phrase (类似sql 的 = )
4、多字段匹配:muti_match (多属性查询)
5、语法查询:query_string (直接写需要配置的 关键字 )
6、字段查询 : term (针对某个属性的查询,这里注意 term 不会进行分词,比如 在 es 中 存了 “火锅” 会被分成 “火/锅” 当你用 term 去查询 “火时能查到”,但是查询 “火锅” 时,就什么都没有,而 match 就会将词语分成 “火/锅”去查)
7、范围查询:range ()
1.2 增删改查
1.2.1.插入操作
Java插入操作代码:
示例一:
String index = "test1";
String type = "_doc";
// 唯一编号
String id = "1";
IndexRequest request = new IndexRequest(index, type, id);
String jsonString = "{" + "\"uid\":\"1234\","+ "\"phone\":\"12345678909\","+ "\"msgcode\":\"1\"," + "\"sendtime\":\"2019-03-14 01:57:04\","
+ "\"message\":\"xuwujing study Elasticsearch\"" + "}";
request.source(jsonString, XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
示例二:
String index = "test1";
String type = "_doc";
// 唯一编号
String id = "1";
IndexRequest request = new IndexRequest(index, type, id);
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("uid", 1234);
jsonMap.put("phone", 12345678909L);
jsonMap.put("msgcode", 1);
jsonMap.put("sendtime", "2019-03-14 01:57:04");
jsonMap.put("message", "xuwujing study Elasticsearch");
request.source(jsonMap);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
示例三:
String index = "test1";
String type = "_doc";
// 唯一编号
String id = "1";
IndexRequest request = new IndexRequest(index, type, id);
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("uid", 1234);
builder.field("phone", 12345678909L);
builder.field("msgcode", 1);
builder.timeField("sendtime", "2019-03-14 01:57:04");
builder.field("message", "xuwujing study Elasticsearch");
}
builder.endObject();
request.source(builder);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1> 使用自定义的id
使用put方式,并自己提供id
类似于下面的格式
PUT /{index}/{type}/{id}
{
"field": "value",
...
}
- 1
- 2
- 3
- 4
- 5
请求
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
- 1
- 2
- 3
- 4
- 5
- 6
响应
{
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 1,
"created": true
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。
1.2.2.更改操作
Java示例代码:
private static void update() throws IOException {
String type = "_doc";
String index = "test1";
// 唯一编号
String id = "1";
UpdateRequest upateRequest = new UpdateRequest();
upateRequest.id(id);
upateRequest.index(index);
upateRequest.type(type);
// 依旧可以使用Map这种集合作为更新条件
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("uid", 12345);
jsonMap.put("phone", 123456789019L);
jsonMap.put("msgcode", 2);
jsonMap.put("sendtime", "2019-03-14 01:57:04");
jsonMap.put("message", "xuwujing study Elasticsearch");
upateRequest.doc(jsonMap);
// upsert 方法表示如果数据不存在,那么就新增一条
upateRequest.docAsUpsert(true);
client.update(upateRequest, RequestOptions.DEFAULT);
System.out.println("更新成功!");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
控制台输入
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
- 1
- 2
- 3
- 4
- 5
- 6
在响应体中,我们能看到 Elasticsearch 已经增加了 _version 字段值,created 标志设置成 false ,是因为相同的索引、类型和 ID 的文档已经存在。
{
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 2,
"created": false
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2.3.删除操作
Java示例代码:
示例一(正常根据ID删除):
private static void delete() throws IOException {
String type = "_doc";
String index = "test1";
// 唯一编号
String id = "1";
DeleteRequest deleteRequest = new DeleteRequest();
deleteRequest.id(id);
deleteRequest.index(index);
deleteRequest.type(type);
// 设置超时时间
deleteRequest.timeout(TimeValue.timeValueMinutes(2));
// 设置刷新策略"wait_for"
// 保持此请求打开,直到刷新使此请求的内容可以搜索为止。此刷新策略与高索引和搜索吞吐量兼容,但它会导致请求等待响应,直到发生刷新
deleteRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
// 同步删除
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
示例二(条件删除):
private static void deleteByQuery() throws IOException {
String type = "_doc";
String index = "test1";
DeleteByQueryRequest request = new DeleteByQueryRequest(index,type);
// 设置查询条件
request.setQuery(QueryBuilders.termsQuery("uid",1234));
// 同步执行
BulkByScrollResponse bulkResponse = client.deleteByQuery(request, RequestOptions.DEFAULT);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
DELETE /website/blog/123
- 1
如果找到该文档,Elasticsearch 将要返回一个 200 ok 的 HTTP 响应码,和一个类似以下结构的响应体。注意,字段 _version 值已经增加:
{
"found" : true,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果文档没有 找到,我们将得到 404 Not Found 的响应码和类似这样的响应体:
{
"found" : false,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 4
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2.4.查询操作
查询API
等值(term查询:QueryBuilders.termQuery(name,value);
多值(terms)查询:QueryBuilders.termsQuery(name,value,value2,value3…);
范围(range)查询:QueryBuilders.rangeQuery(name).gte(value).lte(value);
存在(exists)查询:QueryBuilders.existsQuery(name);
模糊(wildcard)查询:QueryBuilders.wildcardQuery(name,+value+);
组合(bool)查询: BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
1.2.4.1.查询所有代码示例
在这里插入代码片 private static void allSearch() throws IOException {
SearchRequest searchRequestAll = new SearchRequest();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequestAll.source(searchSourceBuilder);
// 同步查询
SearchResponse searchResponseAll = client.search(searchRequestAll, RequestOptions.DEFAULT);
System.out.println("所有查询总数:" + searchResponseAll.getHits().getTotalHits());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.2.4.2.一般查询代码示例
private static void genSearch() throws IOException {
String type = "_doc";
String index = "test1";
// 查询指定的索引库
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 设置查询条件
sourceBuilder.query(QueryBuilders.termQuery("uid", "1234"));
// 设置起止和结束
sourceBuilder.from(0);
sourceBuilder.size(5);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 设置路由
// searchRequest.routing("routing");
// 设置索引库表达式
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
// 查询选择本地分片,默认是集群分片
searchRequest.preference("_local");
// 排序
// 根据默认值进行降序排序
// sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));
// 根据字段进行升序排序
// sourceBuilder.sort(new FieldSortBuilder("id").order(SortOrder.ASC));
// 关闭suorce查询
// sourceBuilder.fetchSource(false);
String[] includeFields = new String[]{"title", "user", "innerObject.*"};
String[] excludeFields = new String[]{"_type"};
// 包含或排除字段
// sourceBuilder.fetchSource(includeFields, excludeFields);
searchRequest.source(sourceBuilder);
System.out.println("普通查询的DSL语句:"+sourceBuilder.toString());
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// HTTP状态代码、执行时间或请求是否提前终止或超时
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
// 供关于受搜索影响的切分总数的统计信息,以及成功和失败的切分
int totalShards = searchResponse.getTotalShards();
int successfulShards = searchResponse.getSuccessfulShards();
int failedShards = searchResponse.getFailedShards();
// 失败的原因
for (ShardSearchFailure failure : searchResponse.getShardFailures()) {
// failures should be handled here
}
// 结果
searchResponse.getHits().forEach(hit -> {
Map<String, Object> map = hit.getSourceAsMap();
System.out.println("普通查询的结果:" + map);
});
System.out.println("\n=================\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
1.2.4.3.或查询代码示例
private static void orSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("test1");
searchRequest.types("_doc");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
BoolQueryBuilder boolQueryBuilder2 = new BoolQueryBuilder();
/**
* SELECT * FROM test1 where (uid = 1234 or uid =12345) and phone = 12345678909
* */
boolQueryBuilder2.should(QueryBuilders.termQuery("uid", 1234));
boolQueryBuilder2.should(QueryBuilders.termQuery("uid", 12345));
boolQueryBuilder.must(boolQueryBuilder2);
boolQueryBuilder.must(QueryBuilders.termQuery("phone", "12345678909"));
searchSourceBuilder.query(boolQueryBuilder);
System.out.println("或查询语句:" + searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
searchResponse.getHits().forEach(documentFields -> {
System.out.println("查询结果:" + documentFields.getSourceAsMap());
});
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.2.4.4.模糊查询代码示例
模糊查询
相当于SQL语句中的like查询。
private static void likeSearch() throws IOException {
String type = "_doc";
String index = "test1";
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(index);
searchRequest.types(type);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
/**
* SELECT * FROM p_test where message like '%xu%';
* */
boolQueryBuilder.must(QueryBuilders.wildcardQuery("message", "*xu*"));
searchSourceBuilder.query(boolQueryBuilder);
System.out.println("模糊查询语句:" + searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
searchResponse.getHits().forEach(documentFields -> {
System.out.println("模糊查询结果:" + documentFields.getSourceAsMap());
});
System.out.println("\n=================\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.2.4.5.多值查询代码示例
也就是相当于SQL语句中的in查询。
private static void inSearch() throws IOException {
String type = "_doc";
String index = "test1";
// 查询指定的索引库
SearchRequest searchRequest = new SearchRequest(index,type);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
/**
* SELECT * FROM p_test where uid in (1,2)
* */
// 设置查询条件
sourceBuilder.query(QueryBuilders.termsQuery("uid", 1, 2));
searchRequest.source(sourceBuilder);
System.out.println("in查询的DSL语句:"+sourceBuilder.toString());
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 结果
searchResponse.getHits().forEach(hit -> {
Map<String, Object> map = hit.getSourceAsMap();
String string = hit.getSourceAsString();
System.out.println("in查询的Map结果:" + map);
System.out.println("in查询的String结果:" + string);
});
System.out.println("\n=================\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1.2.4.6.存在查询
判断是否存在该字段,用法和SQL语句中的exist类似。
private static void existSearch() throws IOException {
String type = "_doc";
String index = "test1";
// 查询指定的索引库
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 设置查询条件
sourceBuilder.query(QueryBuilders.existsQuery("msgcode"));
searchRequest.source(sourceBuilder);
System.out.println("存在查询的DSL语句:"+sourceBuilder.toString());
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 结果
searchResponse.getHits().forEach(hit -> {
Map<String, Object> map = hit.getSourceAsMap();
String string = hit.getSourceAsString();
System.out.println("存在查询的Map结果:" + map);
System.out.println("存在查询的String结果:" + string);
});
System.out.println("\n=================\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.2.4.7.范围查询
和SQL语句中<>使用方法一样,其中gt是大于,lt是小于,gte是大于等于,lte是小于等于。
private static void rangeSearch() throws IOException{
String type = "_doc";
String index = "test1";
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 设置查询条件
sourceBuilder.query(QueryBuilders.rangeQuery("sendtime").gte("2019-01-01 00:00:00").lte("2019-12-31 23:59:59"));
searchRequest.source(sourceBuilder);
System.out.println("范围查询的DSL语句:"+sourceBuilder.toString());
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 结果
searchResponse.getHits().forEach(hit -> {
String string = hit.getSourceAsString();
System.out.println("范围查询的String结果:" + string);
});
System.out.println("\n=================\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1.2.4.8.正则查询
ES可以使用正则进行查询,查询方式也非常的简单,代码示例如下:
private static void regexpSearch() throws IOException{
String type = "_doc";
String index = "test1";
// 查询指定的索引库
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 设置查询条件
sourceBuilder.query(QueryBuilders.regexpQuery("message","xu[0-9]"));
searchRequest.source(sourceBuilder);
System.out.println("正则查询的DSL语句:"+sourceBuilder.toString());
// 同步查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 结果
searchResponse.getHits().forEach(hit -> {
Map<String, Object> map = hit.getSourceAsMap();
String string = hit.getSourceAsString();
System.out.println("正则查询的Map结果:" + map);
System.out.println("正则查询的String结果:" + string);
});
System.out.println("\n=================\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
面试中es常问问题总结:
2.1Elasticsearch是如何实现Master选举的?
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
补充:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
2.2 Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
当集群master候选数量不小于3个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题。
2.3 客户端在和集群连接时,如何选择特定的节点执行请求的?
TransportClient利用transport模块远程连接一个elasticsearch集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的transport地址,并以 轮询 的方式与这些地址进行通信。
2.4 详细描述一下Elasticsearch索引文档的过程。
协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。
shard = hash(document_id) % (num_of_primary_shards)
当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh;
当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush;
在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时;
2.5 详细描述一下Elasticsearch更新和删除文档的过程。
删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更;
磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
2.6 详细描述一下Elasticsearch搜索的过程。
搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
补充:Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
文章来源: baidaguo.blog.csdn.net,作者:白大锅,版权归原作者所有,如需转载,请联系作者。
原文链接:baidaguo.blog.csdn.net/article/details/117995325

- 点赞
- 收藏
- 关注作者
评论(0)