组合数据类型

【摘要】
学习自中国大学mooc
文章目录
组合数据类型1.集合类型及操作集合类型定义集合操作符集合处理方法集合类型应用场景
2.序列类型及操作(重要)序列类型定义序列处理函数及方法元组类型及操作列...

学习自中国大学mooc
组合数据类型
目标:
- 学会Python三种主流组合数据类型的使用方法
- 能够编写处理一组数据的程序
1.集合类型及操作
集合类型定义
集合是多个元素的无序组合
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
为什么集合类型元组不可更改,因为集合元素要求每个元素是唯一的,如果我们在更改元素的过程中出现了元素相同,就会出错。
- 集合用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set()
- 建立空集合类型,必须使用set()

重点:
- 集合用大括号{}表示,元素间用逗号分割
- 集合中元素唯一,不存在相同元素
- 无序性
集合操作符
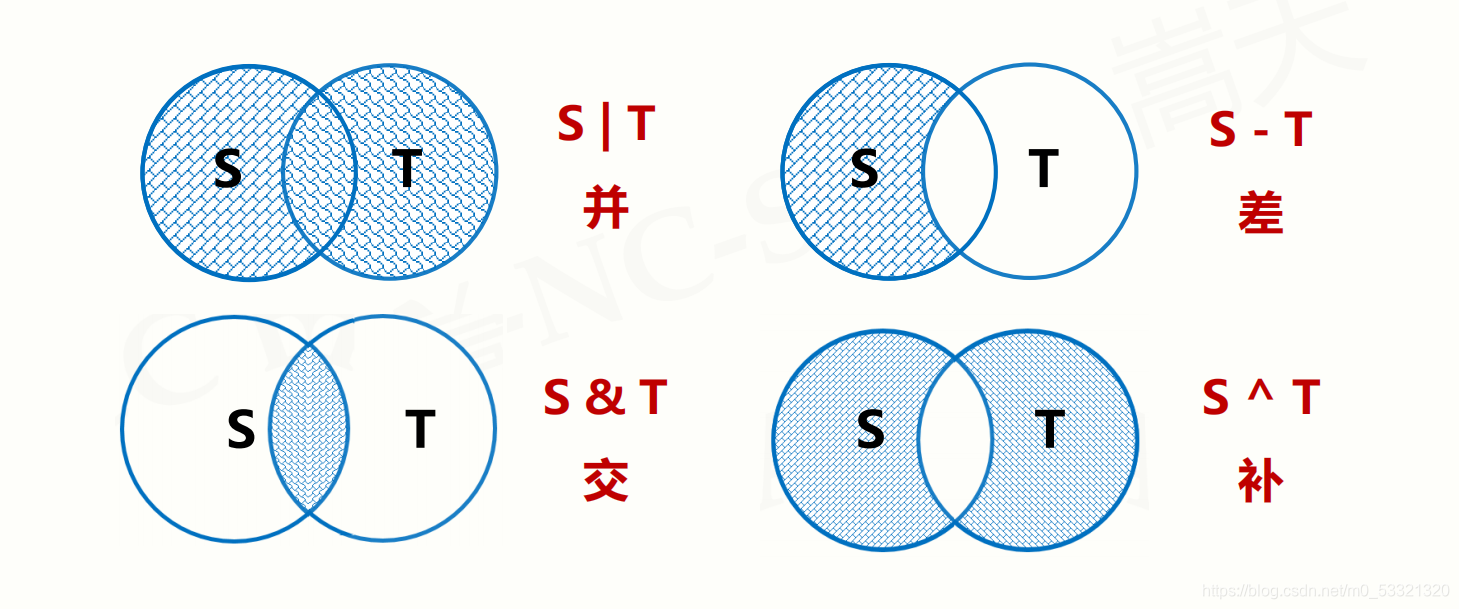
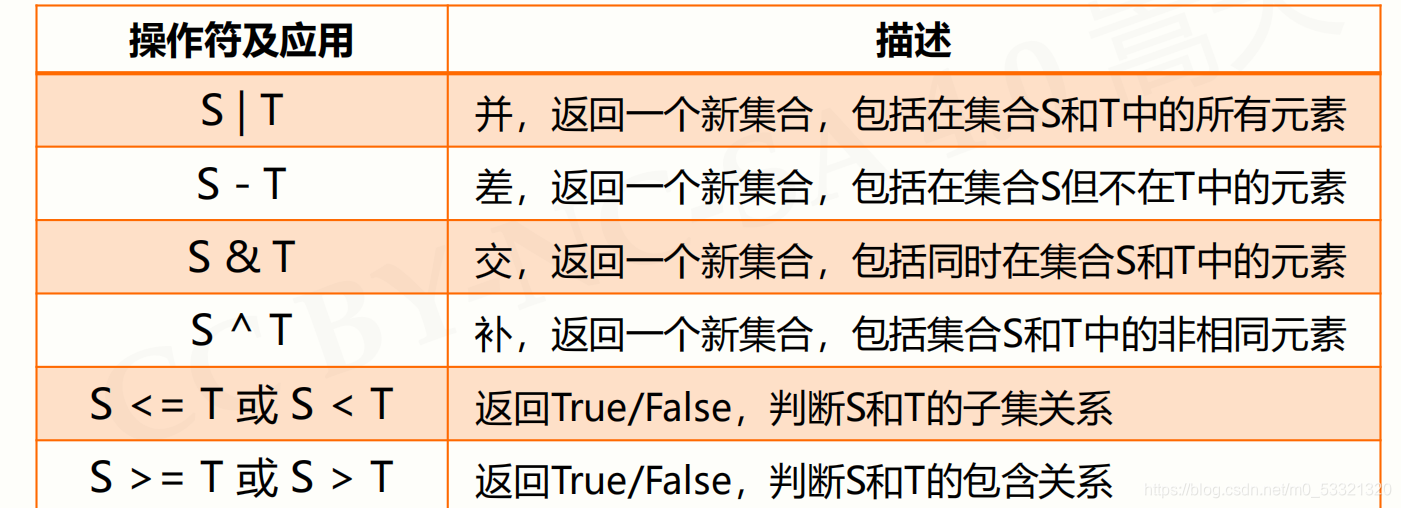

实例:

集合处理方法


循环变量,while死循环有 A.pop() 一直取元素,空时会产生异常try except捕获异常,程序退出。

集合类型应用场景
包含关系比较

数据去重:集合类型所有元素无重复(最重要)

2.序列类型及操作(重要)
- 序列类型应用场景
序列类型定义
定义:序列是具有先后关系的一组元素(感觉像C数组)
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列: s0, s1, … , sn-1
- 元素间由序号引导,通过下标访问序列的特定元素
序列是一个基类类型,衍生出字符串类型,元组类型,列表类型
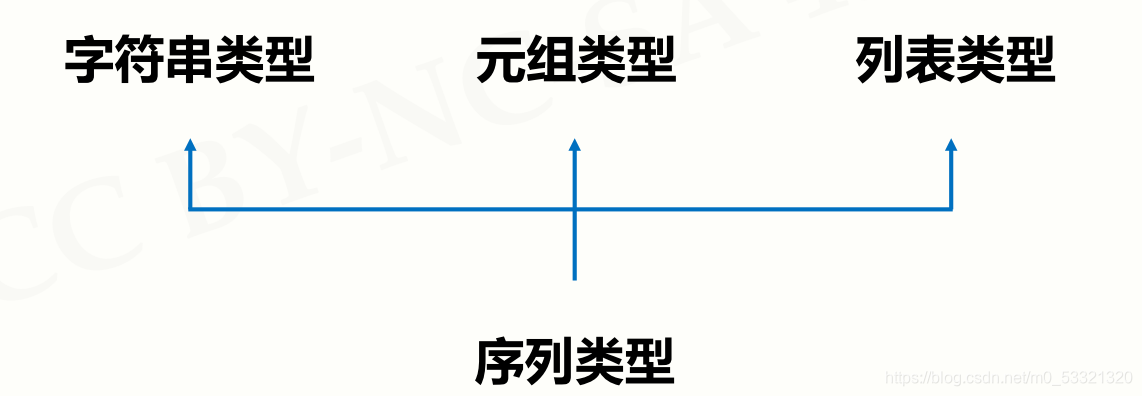
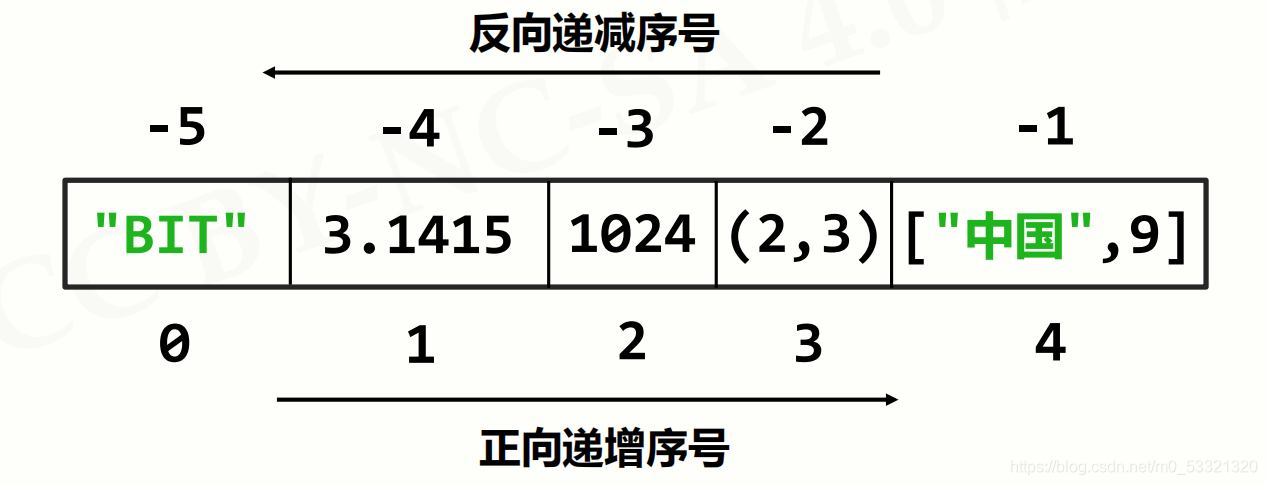
前面的字符串类型大同小异,只不过字符串类型元素只能是字符,而序列可以是任意类型。
序列处理函数及方法
操作符
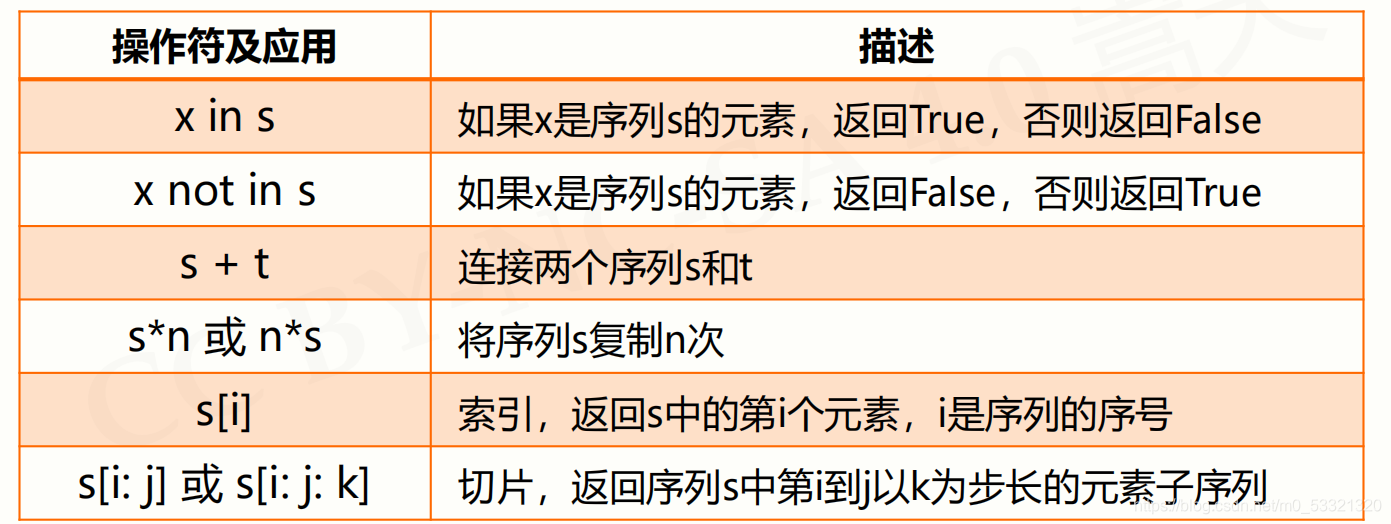
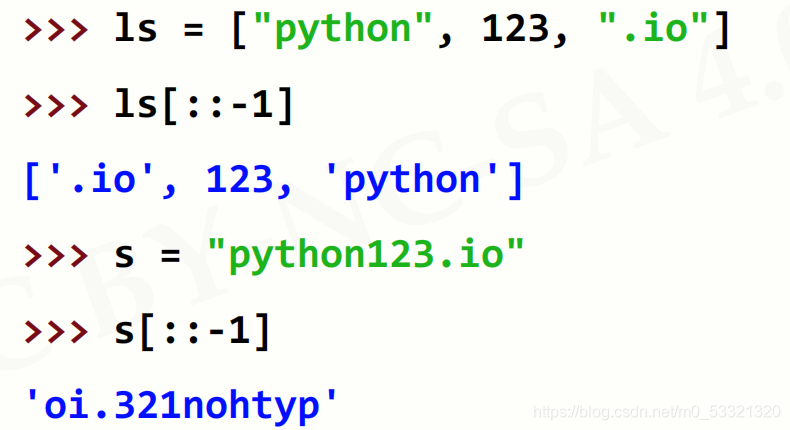
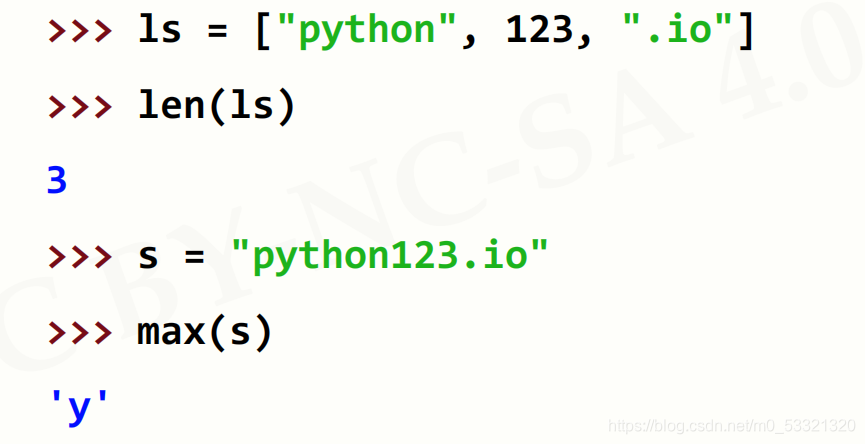
函数

元组类型及操作
元组是序列类型的一种扩展
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号

列表类型及操作
列表是序列类型的一种扩展,十分常用
- 列表是一种序列类型,创建后可以随意被修改
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
- 列表中各元素类型可以不同,无长度限制

这里注意,仅仅通过赋值只是将列表重复命名,此时这两个名字指向一个列表,并未创建新的列表。
列表类型操作函数和方法




序列类型应用场景
- 元组用于元素不改变的应用场景,更多用于固定搭配场景
- 列表更加灵活,它是最常用的序列类型
- 最主要作用:表示一组有序数据,进而操作它们
数据保护
如果不希望数据被程序所改变,转换成元组类型

3.字典类型及操作
字典类型定义
映射
- 映射是一种键(索引)和值(数据)的对应

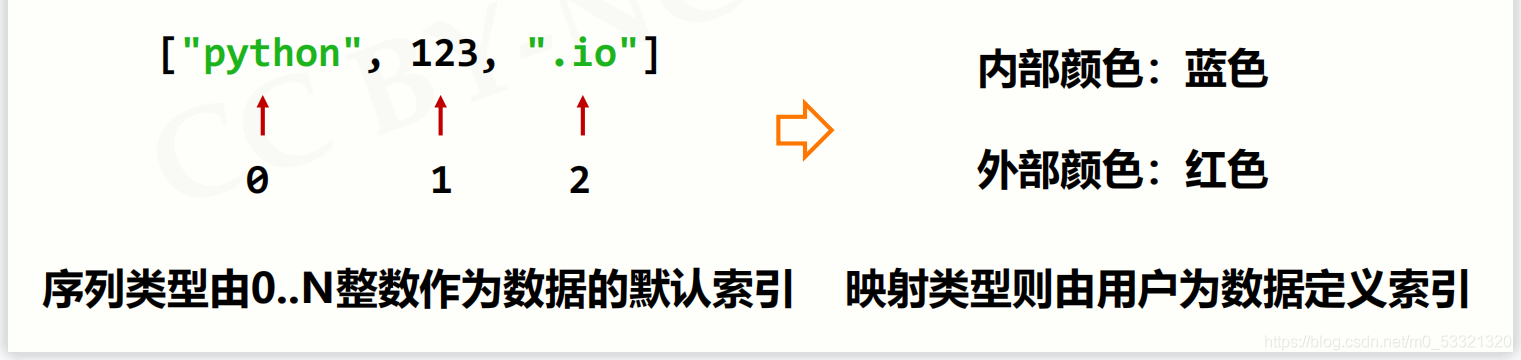
- 键值对:键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号: 表示
在字典变量中,通过键获得值
[ ] 用来向字典变量中索引或增加元素
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
<字典变量> = {<键1>:<值1>, … , <键n>:<值n>}
<值> = <字典变量>[<键>]
<字典变量>[<键>] = <值>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

字典处理函数及方法




字典类型应用场景
- 映射无处不在,键值对无处不在
- 例如:统计数据出现的次数,数据是键,次数是值
- 最主要作用:表达键值对数据,进而操作它们
4.jieba库的使用
jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
安装:
(cmd命令行) pip install jieba
jieba分词依靠中文词库
- 利用一个中文词库,确定中文字符之间的关联概率
- 中文字符间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
jieba库常用函数

5.文本词频统计
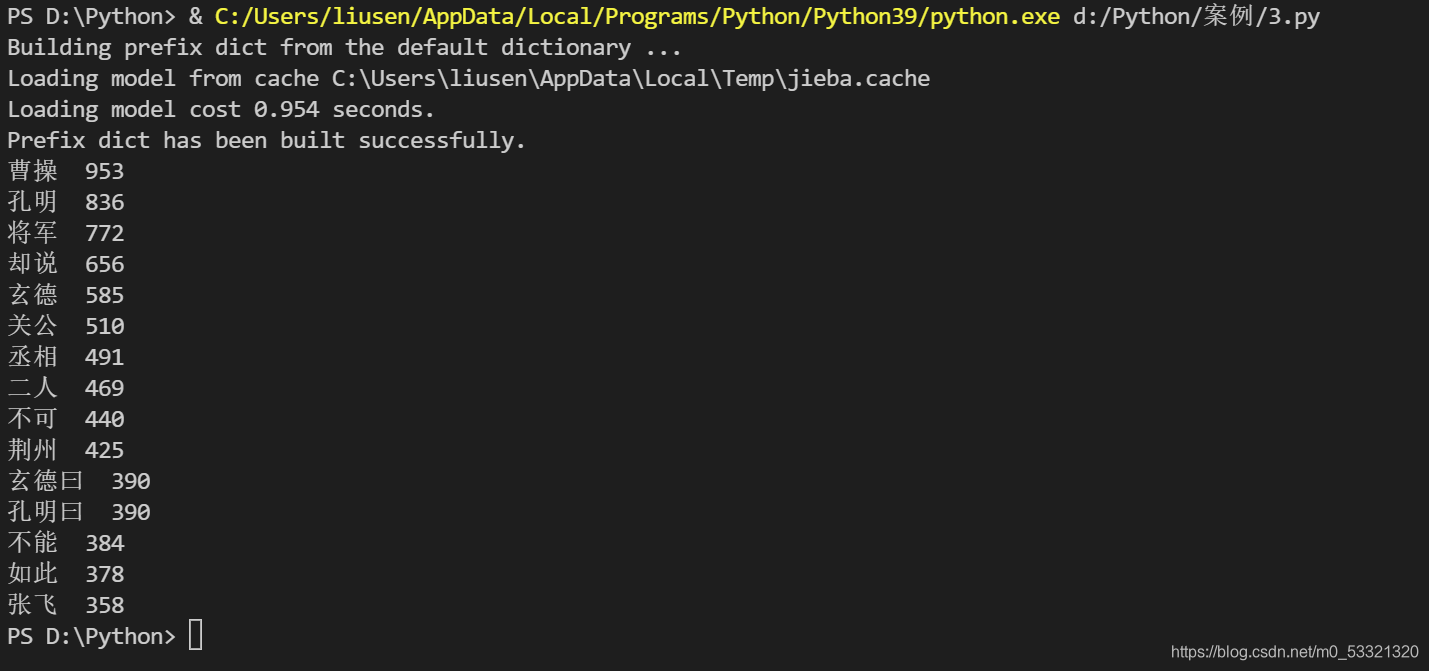
需求:一篇文章,出现了哪些词?哪些词出现得最多?
就找三国演义
import jieba
txt = open("D:\Python\案例\三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
it = list(counts.items())
it.sort(key=lambda x:x[1], reverse=True)
for i in range(15):
word, count = it[i]
print ("{0:<5}{1:>5}".format(word, count))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
先下载,再通过jieba库对文章的高频词条进行了统计

码 住 夏 天
文章来源: blog.csdn.net,作者:周棋洛ყ ᥱ ᥉,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/m0_53321320/article/details/118366845

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)