【大数据】HBase集群安装部署

【摘要】
一、前提条件
服务器配置好,搭建大数据集群服务器看这篇:搭建学习使用的大数据集群环境:windows使用vmware安装三台虚拟机,配置好网络环境安装好对应版本的hadoop集群,并启动安装好对应版本的...
一、前提条件
- 服务器配置好,搭建大数据集群服务器看这篇:搭建学习使用的大数据集群环境:windows使用vmware安装三台虚拟机,配置好网络环境
- 安装好对应版本的hadoop集群,并启动
- 安装好对应版本的zookeeper集群,并启动
1. HBase集群安装部署
1.1 准备安装包
- 下载安装包并上传到node01服务器
- 安装包下载地址:
http://archive.cloudera.com/cdh5/cdh/5/hbase-1.2.0-cdh5.14.2.tar.gz - 将安装包上传到node01服务器/book/soft路径下,并进行解压
[book@bigdatanode01 ~]$ cd /book/soft/
[book@bigdatanode01 soft]$ tar -xzvf hbase-1.2.0-cdh5.14.2.tar.gz -C /book/install/
- 1
- 2
1.2 修改HBase配置文件
1.2.1 hbase-env.sh
- 修改文件
[book@bigdatanode01 soft]$ cd /book/install/hbase-1.2.0-cdh5.14.2/conf/
[book@bigdatanode01 conf]$ vim hbase-env.sh
- 1
- 2
- 修改如下两项内容,值如下
export JAVA_HOME=/book/install/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
- 1
- 2


1.2.2 hbase-site.xml
- 修改文件
[book@bigdatanode01 conf]$ vim hbase-site.xml
- 1
- 内容如下
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
<!-- 此属性可省略,默认值就是2181 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/book/install/zookeeper-3.4.5-cdh5.14.2/zkdatas</value>
</property>
<!-- 此属性可省略,默认值就是/hbase -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
1.2.3 regionservers
- 修改文件
[book@bigdatanode01 conf]$ vim regionservers
- 1
- 指定HBase集群的从节点;原内容清空,添加如下三行
node01
node02
node03
- 1
- 2
- 3
1.2.4 back-masters
- 创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
#创建
[book@bigdatanode01 conf]$ vim backup-masters
- 1
- 2
- 将node02作为备份的HMaster节点,文件内容如下
node02
- 1
1.3 分发安装包
- 将node01上的HBase安装包,拷贝到其他机器上
[book@bigdatanode01 conf]$ cd /book/install
[book@bigdatanode01 install]$ scp -r hbase-1.2.0-cdh5.14.2/ bigdatanode02:$PWD
[book@bigdatanode01 install]$ scp -r hbase-1.2.0-cdh5.14.2/ bigdatanode03:$PWD
- 1
- 2
- 3
1.4 创建软连接
- 注意:三台机器均做如下操作
因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们三台机器都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /book/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/core-site.xml /book/install/hbase-1.2.0-cdh5.14.2/conf/core-site.xml
ln -s /book/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/hdfs-site.xml /book/install/hbase-1.2.0-cdh5.14.2/conf/hdfs-site.xml
- 1
- 2
- 3
- 执行完后,出现如下效果,以bigdatanode01为例

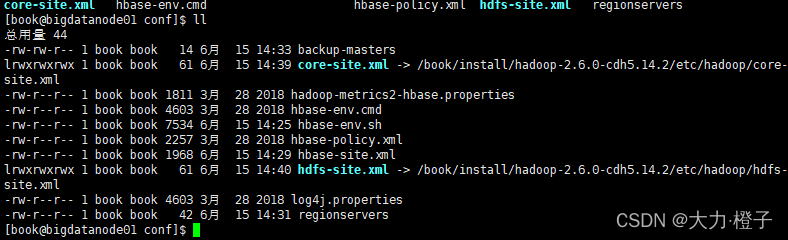
1.5 添加HBase环境变量
- 注意:三台机器均执行以下命令,添加环境变量
sudo vim /etc/profile
- 1
- 文件末尾添加如下内容
# hbase
export HBASE_HOME=/book/install/hbase-1.2.0-cdh5.14.2
export PATH=$PATH:$HBASE_HOME/bin
- 1
- 2
- 3
- 重新编译/etc/profile,让环境变量生效
source /etc/profile
- 1
1.6 HBase的启动与停止
- 需要提前启动HDFS及ZooKeeper集群
- 第一台机器bigdatanode01(HBase主节点)执行以下命令,启动HBase集群
[book@bigdatanode01 ~]$ /book/install/hbase-1.2.0-cdh5.14.2/bin/start-hbase.sh
- 1
-
启动完后,jps查看HBase相关进程
bigdatanode01、bigdatanode02上有进程HMaster、HRegionServer
bigdatanode03上有进程HRegionServer -
警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告
-
可以注释掉所有机器的hbase-env.sh当中的
“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 来解决这个问题。
不过警告不影响我们正常运行,可以不用解决 -
我们也可以执行以下命令,单节点启动相关进程
#HMaster节点上启动HMaster命令
hbase-daemon.sh start master
#启动HRegionServer命令
hbase-daemon.sh start regionserver
- 1
- 2
- 3
- 4
- 5
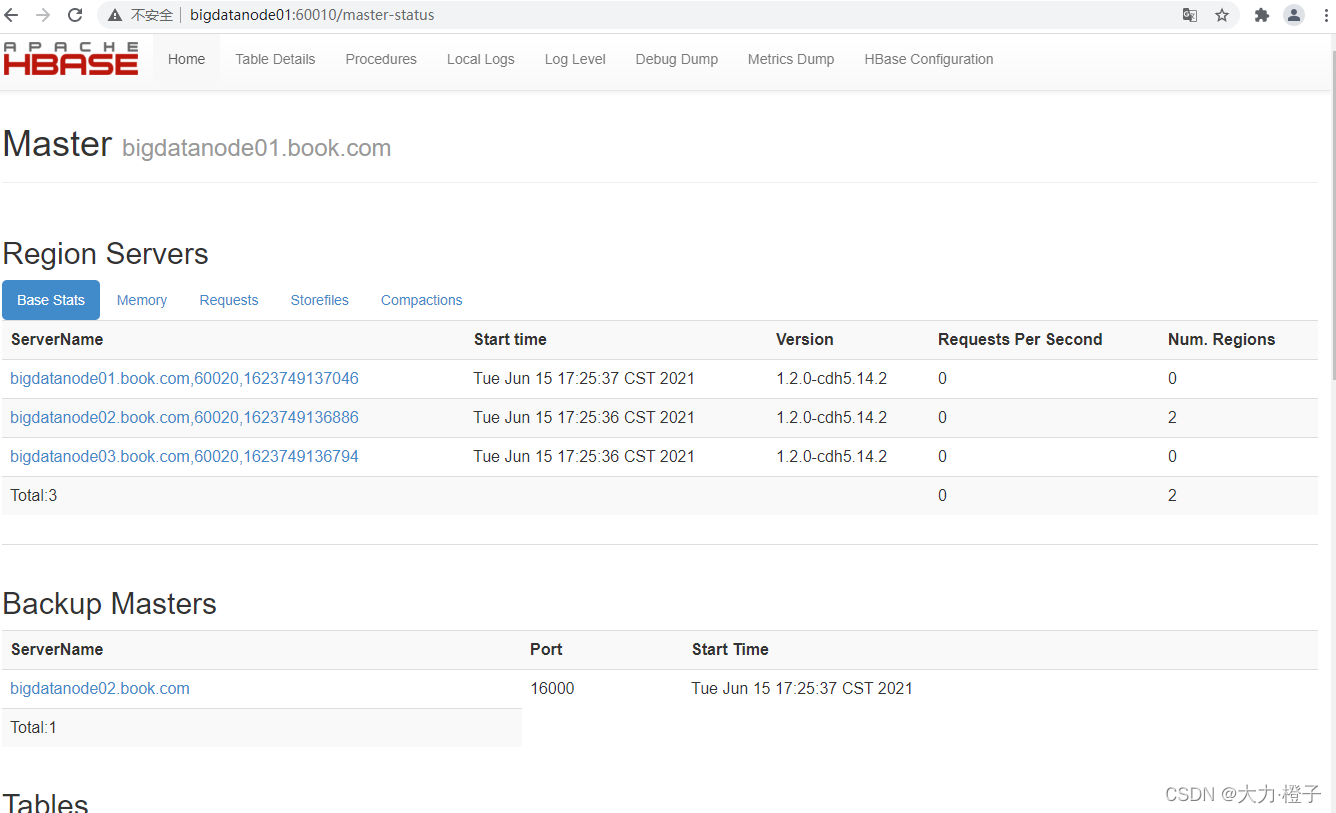
1.7 访问WEB页面
- 浏览器页面访问
http://bigdatanode01:60010
1.8 停止HBase集群
虚拟机停止HBase集群的正确顺序
- bigdatanode01上运行,关闭hbase集群
[book@bigdatanode01 ~]$ stop-hbase.sh
- 1
- 2
- 3
- 关闭ZooKeeper集群
- 关闭Hadoop集群
- 关闭虚拟机
- 关闭电脑
文章来源: blog.csdn.net,作者:橙子园,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/Chenftli/article/details/121947456

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)