【大数据】一文了解hive中开发、使用udf

我们在使用hive时难免会碰到hive的函数解决不了的操作,这时我们就可以开发UDF函数去解决复杂的问题。
首先我们老生长谈一下udf函数分类:
UDF : User-Defined Function (用户自定义函数)一进一出
UDAF : User-Defined Aggregation Function(用户自定义聚合函数) 多进一出
UDTF : User-Defined Table-Generating Function(用户自定义表生成函数)一进多出
这里我们示例使用java来开发UDF函数,并上传到hdfs上,注册函数使用。
1、maven项目的pom.xml当中添加如下依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.0-cdh5.14.2</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
这里我使用的是cdh5.14.2的包,这里面会包括hadoop.io的数据类型的包,下面写的类型也是使用Text,尽量使用hadoop提供的数据类型,性能要比使用java的数据类型优,其次对于hive的array数据类型,java承接时需要使用ArrayList来使用。
2、开发一个udf函数并测试:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import java.util.ArrayList;
public class ArrayIntegrationUDF extends UDF {
public ArrayList<Text> evaluate(ArrayList<Text> one, ArrayList<Text> two) {
ArrayList<Text> lis = new ArrayList<>();
int oneSize = one.size();
int twoSize = two.size();
// 如果one没有,则直接返回空数组,
//one有一个,one有多个
if (oneSize==1) {
if (twoSize==0) {
lis.add(one.get(0));
} else {
for (Text str : two) {
lis.add(new Text(one.get(0) + ";" + str));
}
}
} else if (oneSize>1) {
if (twoSize==0) {
lis.addAll(one);
} else {
if (oneSize == twoSize) {
for (int i = 0; i < oneSize; i++) {
lis.add(new Text(one.get(i) + ";" + two.get(i)));
}
} else if (oneSize > twoSize) {
for (int i = 0; i < oneSize; i++) {
if (i < twoSize) {
lis.add(new Text(one.get(i) + ";" + two.get(i)));
} else {
lis.add(one.get(i));
}
}
} else {
for (int i = 0; i < twoSize; i++) {
if (i < oneSize) {
lis.add(new Text(one.get(i) + ";" + two.get(i)));
} else {
lis.add(new Text(one.get(oneSize-1) + ";" + two.get(i)));
}
}
}
}
}
return lis;
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
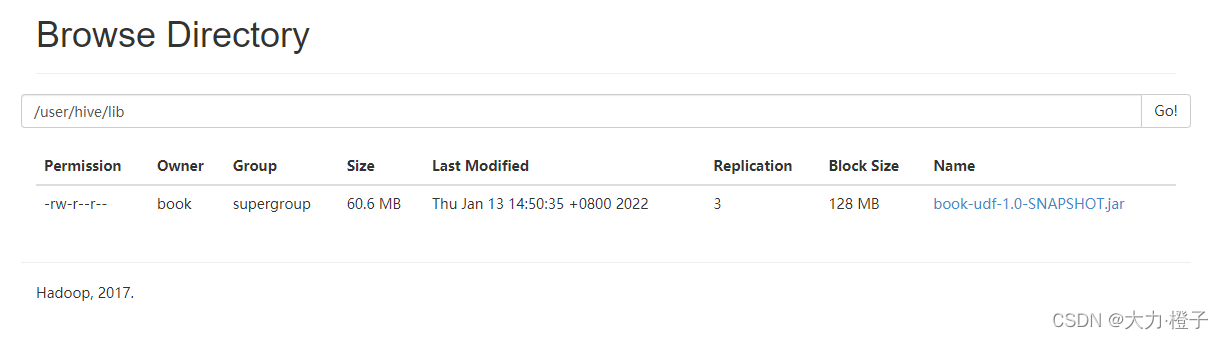
3、打包、将打的jar包上传到hdfs上
hdfs上创建目录:hadoop fs -mkdir /user/hive/lib
上传jar包:hadoop fs -put /book/jar/book-udf-1.0-SNAPSHOT.jar /user/hive/lib

4、注册UDF函数
临时 : 只在当前hive窗口有效,窗口关闭,函数即被移除
永久 : 当前hive窗口关闭,重新打开也可以使用
临时
1.临时注册只要在客户端添加jar的即可,客户端可以是hiveshell、beeline、hue
hive> add jar /home/hadoop/lib/book-udf-1.0-SNAPSHOT.jar;
hue中ui界面可以上传jar包
2.创建临时方法语法: CREATE TEMPORARY FUNCTION 函数名 AS “自定义UDF函数类名”;
hive> CREATE TEMPORARY FUNCTION integration_array AS "com.medbook.assistant.ArrayIntegrationUDF";
删除临时函数
hive> drop temporary function add_prefix;
OK Time taken: 0.003 seconds
- 1
- 2
永久
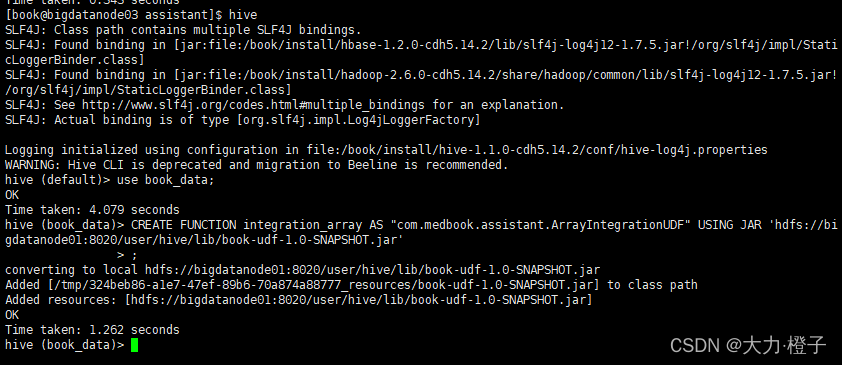
hiveShell中执行
格式:
CREATE FUNCTION 函数名 AS “自定义UDF函数类名” USING JAR “jar包所在hdfs路径”;
CREATE FUNCTION integration_array AS "com.medbook.assistant.ArrayIntegrationUDF" USING JAR 'hdfs://bigdatanode01:8020/user/hive/lib/book-udf-1.0-SNAPSHOT.jar';
- 1
删除永久函数:
drop function 注册的函数名;
文章来源: blog.csdn.net,作者:橙子园,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/Chenftli/article/details/122475494

- 点赞
- 收藏
- 关注作者
评论(0)