C语言【进阶】付费知识【一】

程序=算法+数据结构+程序设计方法+语言工具和坏境
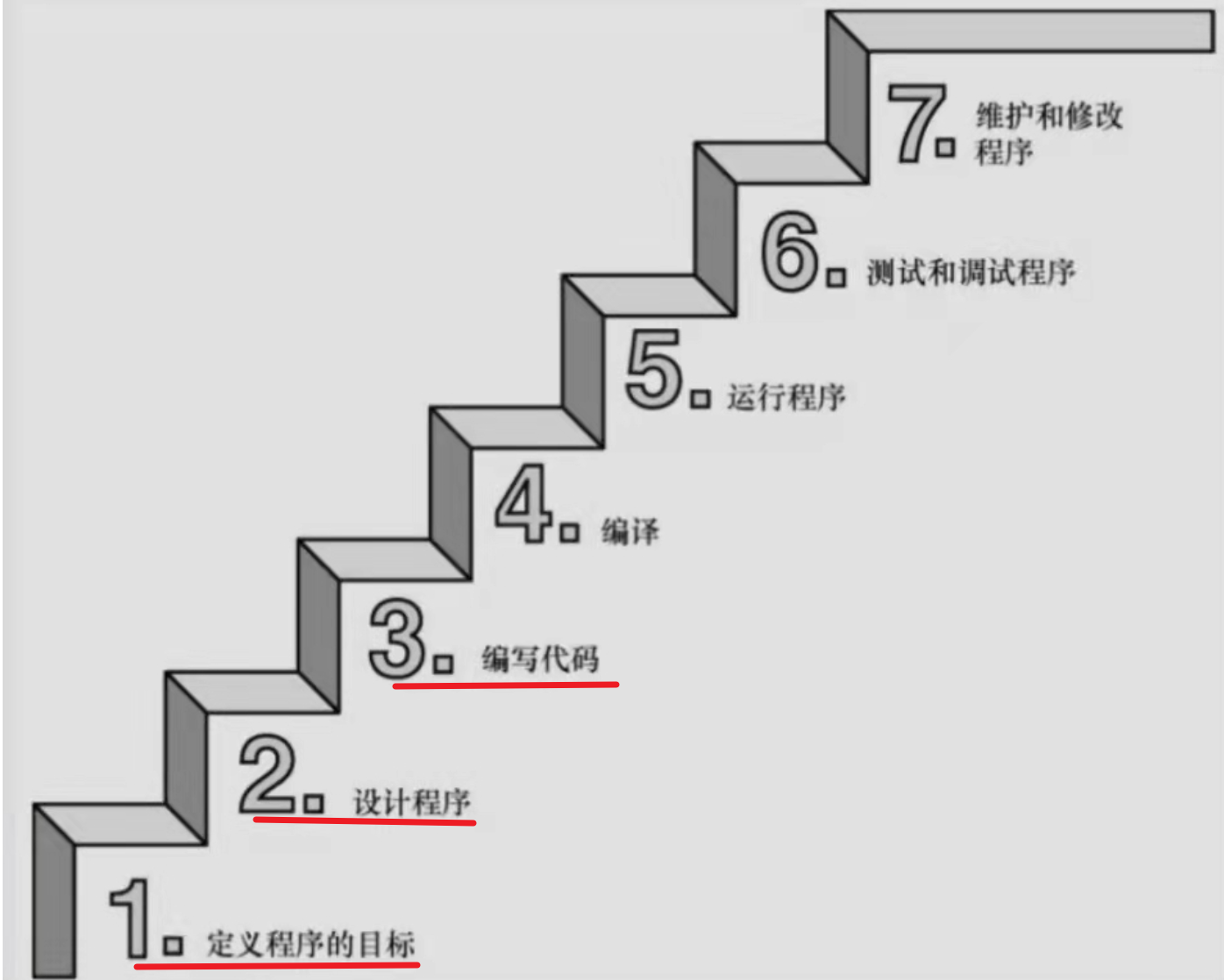
告知:使用C语言的7个步骤
-
第1步:定义程序的目标
在动手写程序之前,要在脑中有清晰的思路。想要程序去做什么首先自己要明确自己想做什么,思考你的程序需要哪些信息,要进行哪些计算和控制,以及程序应该要报告什么信息。在这一步骤中,不涉及具体的计算机语言,应该用一般术语来描述问题。
-
第2步:设计程序
对程序应该完成什么任务有概念性的认识后,就应该考虑如何用程序来完成它。例如,用户界面应该是怎样的?如何组织程序?目标用户是谁?准备花多长时间来完成这个程序?
除此之外,还要决定在程序(还可能是辅助文件)中如何表示数据,以及用什么方法处理数据。学习C语言之初,遇到的问题都很简单,没什么可选的。但是,随着要处理的情况越来越复杂,需要决策和考虑的方面也越来越多。通常,选择一个合适的方式表示信息可以更容易地设计程序和处理数据。
再次强调,应该用一般术语来描述问题,而不是用具体的代码。但是,你的某些决策可能取决于语言的特性。例如,在数据表示方面,C的程序员就比Pascal的程序员有更多选择。
-
第3步:编写代码
设计好程序后,就可以编写代码来实现它。也就是说,把你设计的程序翻译成 C语言。这里是真正需要使用C语言的地方。可以把思路写在纸上,但是最终还是要把代码输入计算机。这个过程的机制取决于编程环境,我们稍后会详细介绍一些常见的环境。一般而言,使用文本编辑器创建源代码文件。该文件中内容就是你翻译的C语言代码。程序清单1.1是一个C源代码的示例。
程序清单1.1 C源代码示例
#include <stdio.h>
int main(void)
{
int dogs;
printf("How many dogs do you have?\n");
scanf("%d", &dogs);
printf("So you have %d dog(s)!\n", dogs);
return 0;
}
在这一步骤中,应该给自己编写的程序添加文字注释。最简单的方式是使用 C的注释工具在源代码中加入对代码的解释。
第4步:编译
接下来的这一步是编译源代码。再次注意,编译的细节取决于编程的环境,前面介绍过,编译器是把源代码转换成可执行代码的程序。可执行代码是用计算机的机器语言表示的代码。这种语言由数字码表示的指令组成。如前所述,不同的计算机使用不同的机器语言方案。C 编译器负责把C代码翻译成特定的机器语言。此外,C编译器还将源代码与C库(库中包含大量的标准函数供用户使用,如printf()和scanf())的代码合并成最终的程序(更精确地说,应该是由一个被称为链接器的程序来链接库函数,但是在大多数系统中,编译器运行链接器)。其结果是,生成一个用户可以运行的可执行文件,其中包含着计算机能理解的代码。
编译器还会检查C语言程序是否有效。如果C编译器发现错误,就不生成可执行文件并报错。理解特定编译器报告的错误或警告信息是程序员要掌握的另一项技能。
第5步:运行程序
传统上,可执行文件是可运行的程序。在(常端模式和Linux终端模式)中运行程序要输入可执行文件的文件名,而其他环境可能要运行命令(如,在VAX中的VMS[2])或一些其他机制。例如,在Windows和Macintosh提供的集成开发环境(IDE)中,用户可以在IDE中通过选择菜单中的选项或按下特殊键来编辑和执行C程序。最终生成的程序可通过单击或双击文件名或图标直接在操作系统中运行。
第6步:测试和调试程序
程序能运行是个好迹象,但有时也可能会出现运行错误。接下来,应该检查程序是否按照你所设计的思路运行。你会发现你的程序中有一些错误,计算机行话叫作bug。查找并修复程序错误的过程叫调试。学习的过程中不可避免会犯错,学习编程也是如此。因此,当你把所学的知识应用于编程时,最好为自己会犯错做好心理准备。
第7步:维护和修改代码
创建完程序后,你发现程序有错,或者想扩展程序的用途,这时就要修改程序。例如,用户输入以Zz开头的姓名时程序出现错误、你想到了一个更好的解决方案、想添加一个更好的新特性,或者要修改程序使其能在不同的计算机系统中运行,等等。如果在编写程序时清楚地做了注释并采用了合理的设计方案,这些事情都很简单。
许多初学者经常忽略第1步和第2步(定义程序目标和设计程序),直接跳到第3步(编写代码)。刚开始学习时,编写的程序非常简单,完全可以在脑中构思好整个过程。即使写错了,也很容易发现。但是,随着编写的程序越来越庞大、越来越复杂,动脑不动手可不行,而且程序中隐藏的错误也越来越难找。最终,那些跳过前两个步骤的人往往浪费了更多的时间,因为他们写出的程序难看、缺乏条理、让人难以理解。要编写的程序越大越复杂,事先定义和设计程序环节的工作量就越大。
磨刀不误砍柴工,应该养成先规划再动手编写代码的好习惯,用纸和笔记录下程序的目标和设计框架。这样在编写代码的过程中会更加得心应手、条理清晰。
最简单的C代码
int main(void){
return 0;
}
判断浮点数变量x的值是否为零
if(|x-0.000001|<=0.000001)
printf("零");
else
printf("不是零")
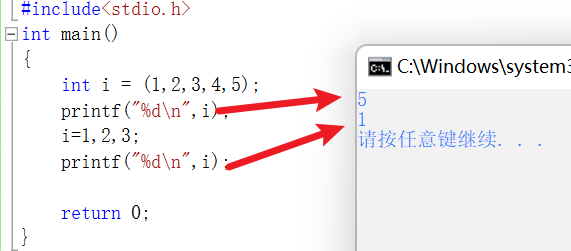
逗号表达式
第一个输出:是因为逗号表达式,只会把逗号的最后一个值赋给i
第二个:i赋值为1,接着执行常量2的运算,计算结果丢弃。最终,i的结果是1而不是2.
求位
百分位:n/00;
十位:n/10%100 或 (n-a*100)/10
个位:n%10
控制行号:if(++n%5==0)//五个为一行
printf("\n");
循环语句
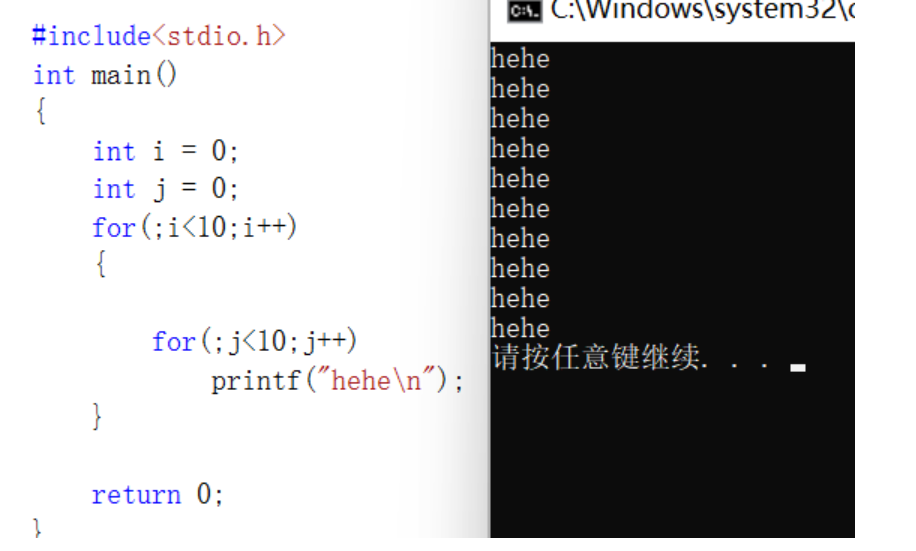
看下面代码,你认为会打印多少句”hehe“?
- for变种1
#include<stdio.h>
int main()
{
int i = 0;
int j = 0;
for(;i<10;i++)
{
for(;j<10;j++)
printf("hehe\n");
}
return 0;
}
答案是只输出10句;
//j++ =0,1,2,3,4,5,6,7,8,9,10;j=10;
//执行外层for时,i等于1了,进入内循环,j没有被重新初始化,导致j的值还是10;i++等于2时,j依然还是10开始。…不满足内循环直接退出,打印10次hehe
-
for变种2
直接上代码

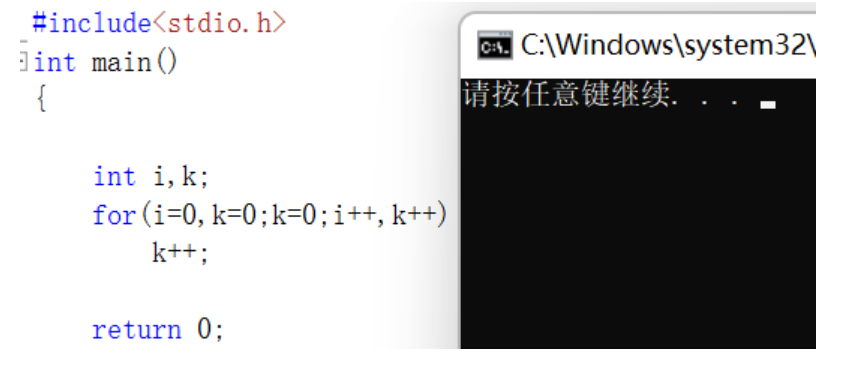
for执行了0次,因为k赋值了0,为假,所以不执行
分支语句
int day = 0;
int n = 1;
scanf("%d",&day);
switch(day)
{
case 1+0://ok
printf("星期一");
case 1.0://error ,只能是整形常量
case n://error
break;//在最后的case语句加一个break,为以后添加case分支而好维护
}
if代码规范
int num = 4;
if(5 == num)//常量和变量比较时,常量因放在变量左边
//if(5 = num);//编译失败,直观错误
printf("hehe");
函数
实际参数(实参)
真实传给函数的参数,叫实参,实参可以是:常量,变量,表达式,函数等。无论实参是何种类型的量,在进行函调用时,它们都必须有确定的值,以便把这些值传递给形参。
形式参数(形参)
形式参数是指函数名后括号中的变量,因为形式参数只有在函数被调用的过程中才实例化(分配内存单元),所以叫形式参数,形式参数当函数调用完成之后就自动销毁,因此形式参数只在函数中有效
时间函数
#include <stdio.h>
#include <time.h>
int main ()
{
time_t rawtime;
struct tm * timeinfo;
time ( &rawtime );
timeinfo = localtime ( &rawtime );
printf ( "当前本地时间为: %s", asctime (timeinfo) );
return 0;
}
函数的调用
#include<stdio.h>
void Swap2(int* pa,int* pb)
{
int tmp = 0;
tmp = *pa;
*pa = *pb;
*pb = tmp;
}
//void Swap1(int x,int y)
//{
//
// int tmp = 0;
// tmp = x;
// x = y;
// y = x;
//}
int main()
{
int a = 10;
int b = 20;
printf("交换前:a = %d b = %d\n",a,b);
//Swap1(a, b);//传值调用
Swap2(&a, &b);//传址调用
printf("交换后:a = %d,b = %d\n",a,b);
return 0;
}
传值调用:
函数的形参和实参分别占有不同的内存块,对形参的修改不会影响实参。
传址调用✅✅
- 传址调用是把函数外部创建变量的内存地址传递给函数参数的一种调用函数的方式。
- 这种传参方式可以让函数和函数外边的变量建立起真正的联系,也就是函数内部可以直接操作函数外部的变量。
传址调用可以节省内存,因为传值的话,我们需要拷贝,参数压栈的系统开销比较大,导致性能下降
函数嵌套
#include<stdio.h>
int main()
{
printf("%d",printf("%d",printf("%d",printf("%d",4))));//打印4111
//因为最后一个printf打印4,倒数第二个printf打印调用printf输出的个数为1(包括空格),依次...详细看printf函数文档
printf("%d",printf("%d",printf("%d",43))//4321
return 0;
}
函数递归(递去归来)
递归的两个必要条件
- 存在限制条件,当满足这个限制条件的时候,递归便不再继续
- 每次递归调用之后越来越接近这个限制
错误使用 递归
#include<stdio.h>
int main()
{
main();//err
return 0;
}
正确使用递归
#include<stdio.h>
void print(int n)//依次打印1 2 3 4
{
if(n>9)
print(n/10);
printf("%d ",n%10);
}
int main()
{
int num = 0;
scanf("%d",&num);//1234
print(num);
}
回调函数
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//void qsort(void *base, //base中存放的是待排序数据中的第一个对象的地址
// size_t num, //排序数据元素的个数
// size_t size,//排序数据中一个元素的大小,单位是字节
// int (*cmp)(const void*,const void*)//是用来比较待排序数据中的2个元素的(一个)函数
// );
int cmp_int(const void* e1,const void* e2)
{
return *(int *)e1-*(int *)e2;//因为参数类型是void,我们用(*int)强制类型转换
/*返回值 意义
<0 所指向的元素在所指向的元素之前p1p2
0 指向的元素等效于 指向的元素p1p2
>0 指向的元素位于 指向的元素之后p1p2
*/
}
void print(int arr[],int sz)
{
int i= 0;
for(i=0;i<sz;i++)
{
printf("%d ",arr[i]);
}
printf("\n");
}
void test1()
{
//整形数据的排序
int arr[]={9,8,7,6,5,4,3,2,1,0};
int sz=sizeof(arr)/sizeof(arr[0]);
//排序
qsort(arr,sz,sizeof(arr[0]),cmp_int);
//打印
print(arr,sz);
}
struct Stu
{
char name[20];
int age;
};
int sort_by_age(const void* e1,const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;//转换结构体类型指针,e1指向age成员
}
void test2()
{
//排序结构体数据
struct Stu s[3]={ {"zhangsang",30},{"lisi",34},{"wangwu",20}};
int sz=sizeof(s)/sizeof(s[0]);
//按照年龄来排序
qsort(s,sz,sizeof(s[0]),sort_by_age);
}
int sort_by_name(const void* e1,const void* e2)
{
return strcmp(((struct Stu*)e1)->name ,((struct Stu*)e2)->name);
}
void test3()
{
//排序结构体数据
struct Stu s[3]={ {"zhangsang",30},{"lisi",34},{"wangwu",20}};
int sz=sizeof(s)/sizeof(s[0]);
//按照名字来排序
qsort(s,sz,sizeof(s[0]),sort_by_name);
}
int main()
{
//test1();
//test2();
test3();
return 0;
}
[^函数调用返回出错都是1或NULL,0值表示程序没有错误]:
数组
- 数组的长度单位是常量表达式表示
- 数组在内存中连续存放的,
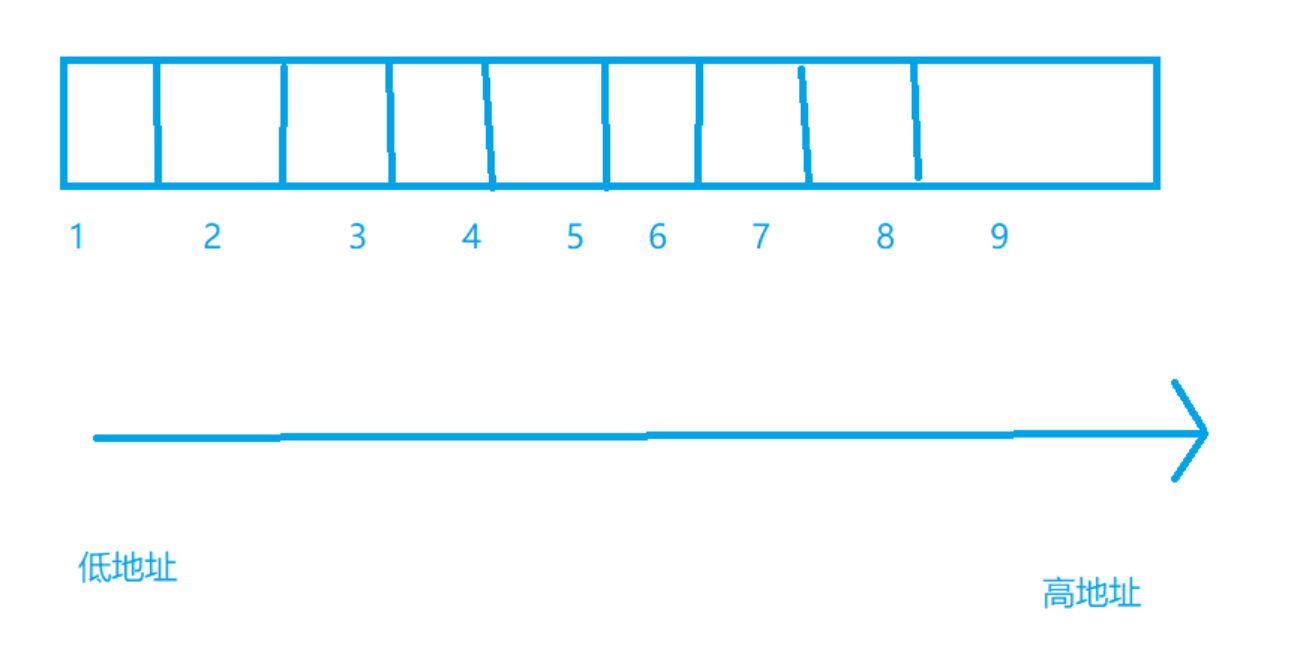
int n =10;
int arr[n]={1,2,3,4,4,};//error
下标
如果下标是从那些已知正确的值计算得来,那么就无需检查它的值。如果一个用作下标的值是根据某种方法从用户输入的数据产生而来的,那么在使用它之前必须进行检查,确保它们位于有效的范围之内。
指针
指针,间接访问和变量
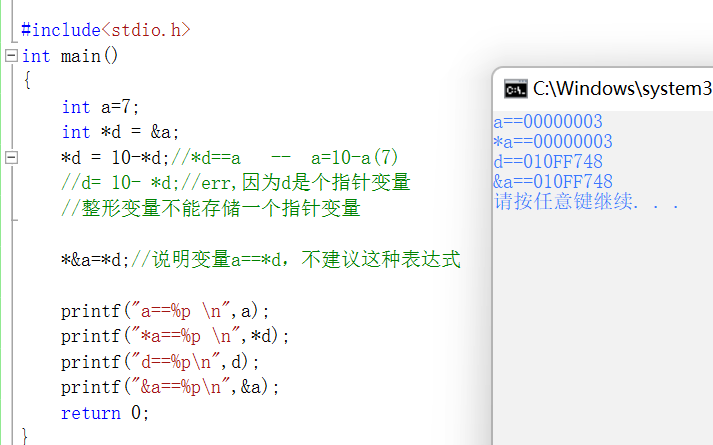
#include<stdio.h>
int main()
{
int a=7;
int *d = &a;
*d = 10-*d;//*d==a -- a=10-a(7)
//d= 10- *d;//err,因为d是个指针变量
//整形变量不能存储一个指针变量
*&a=*d;//说明变量a==*d,不建议这种表达式
printf("a==%p \n",a);
printf("*a==%p \n",*d);
printf("d==%p\n",d);
printf("&a==%p\n",&a);
return 0;
}
函数指针
void test(int **p2)
{
**p2=20;
}
int test_p(int x,int y)
{
return x+y;
}
#include<stdio.h>
int main()
{
int a =10;
int * pa=&a;//pa是一级指针
int **ppa=&pa;//ppa是二级指针
//二级指针传参
test(ppa);
test(&pa);//传一级指针的地址
int* arr[10]={0};
test(arr);
printf("%d ",a);
//pf函数指针变量
int (*pf)(int ,int )=&test_p;
return 0;
}
int Add(int x,int y)
{
return x+y;
}
#include<stdio.h>
int main()
{
//int (*pf)(int,int )=&Add;
int (*pf)(int,int )=Add;//Add == pf
//int ret=(Add)(3,5);//3
//int ret=(*pf)(3,5)//1 ;*是摆设,可以int ret=(*****pf)(3,5)结果依然正确
//int ret=*pf(3,5)//err;优先级 pf会先和(3,5)结合,任何*对函数的返回值8解引用肯定会错
int ret = pf(3,5);//2
printf("%d ",ret);//
return 0;
}
函数指针数组
int add(int x,int y)
{
return x+y;
}
int sub(int x,int y)
{
return x-y;
}
#include<stdio.h>
int main()
{
int (*pf1)(int ,int)=add;
int (*pf2)(int ,int)=sub;
int (*pfarr[2])(int ,int )={add,sub};//pfarr就是函数指针数组,{}里可以是pf1,pf2,*注意是花括号
//add函数和sub函数的形参因为一样,内存存放也是一样,而数组前提就是内存类型一样;
//所以可以同数组存放到函数指针,故叫做函数指针数组。
return 0;
}
函数指针数组的使用
#include<stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("**************************\n");
}
int main()
{
int input = 0;
//计算器-计算整型变量的加、减、乘、除
//a&b a^b a|b a>>b a<<b a>b
do {
menu();
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出程序\n");
break;
default:
printf("选择错误,重新选择!\n");
break;
}
} while (input);
return 0;
}
优化后的代码:
#include<stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("**************************\n");
}
int main()
{
int input = 0;
//计算器-计算整型变量的加、减、乘、除
//a&b a^b a|b a>>b a<<b a>b
do {
menu();
//pfArr就是函数指针数组
//转移表 - 《C和指针》
int (*pfArr[5])(int, int) = { NULL, Add, Sub, Mul, Div };
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:>");
scanf("%d", &input);//2
if (input >= 1 && input <= 4)
{
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = (pfArr[input])(x, y);
printf("ret = %d\n", ret);
}
else if(input == 0)
{
printf("退出程序\n");
break;
}
else
{
printf("选择错误\n");
}
} while (input);
return 0;
}
回调函数_qsort函数的使用
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//void qsort(void *base, //base中存放的是待排序数据中的第一个对象的地址
// size_t num, //排序数据元素的个数
// size_t size,//排序数据中一个元素的大小,单位是字节
// int (*cmp)(const void*,const void*)//是用来比较待排序数据中的2个元素的(一个)函数
// );
int cmp_int(const void* e1,const void* e2)
{
return *(int *)e1-*(int *)e2;//因为参数类型是void,我们用(*int)强制类型转换
/*返回值 意义
<0 所指向的元素在所指向的元素之前p1p2
0 指向的元素等效于 指向的元素p1p2
>0 指向的元素位于 指向的元素之后p1p2
*/
}
void print(int arr[],int sz)
{
int i= 0;
for(i=0;i<sz;i++)
{
printf("%d ",arr[i]);
}
printf("\n");
}
void test1()
{
//整形数据的排序
int arr[]={9,8,7,6,5,4,3,2,1,0};
int sz=sizeof(arr)/sizeof(arr[0]);
//排序
qsort(arr,sz,sizeof(arr[0]),cmp_int);
//打印
print(arr,sz);
}
struct Stu
{
char name[20];
int age;
};
int sort_by_age(const void* e1,const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;//转换结构体类型指针,e1指向age成员
}
void test2()
{
//排序结构体数据
struct Stu s[3]={ {"zhangsang",30},{"lisi",34},{"wangwu",20}};
int sz=sizeof(s)/sizeof(s[0]);
//按照年龄来排序
qsort(s,sz,sizeof(s[0]),sort_by_age);
}
int sort_by_name(const void* e1,const void* e2)
{
return strcmp(((struct Stu*)e1)->name ,((struct Stu*)e2)->name);
}
void test3()
{
//排序结构体数据
struct Stu s[3]={ {"zhangsang",30},{"lisi",34},{"wangwu",20}};
int sz=sizeof(s)/sizeof(s[0]);
//按照名字来排序
qsort(s,sz,sizeof(s[0]),sort_by_name);
}
int main()
{
//test1();
//test2();
test3();
return 0;
}
模仿qsort函数的通用算法
void Swap(char*buf1,char*buf2,int width)
{
int i = 0;
for(i=0;i<width;i++)
{
char tmp = *buf1;
*buf1=*buf2;
*buf2=tmp;
buf1++;
buf2++;
}
}
//模仿qsort实现一个冒泡排序的通用算法
void bubbble_sort(void *base,
int sz,
int width,
int (*cmp)(const void*e1,const void*e2)
)
{
int i =0;
for(i=0;i<sz-1;i++){
int j = 0;
for(j=0;j<sz-1-i;j++)
{
if(cmp((char*)base+j*width,(char *)base+(j+1)*width)>0)//(兼并)适合int类型和字符类型,如果是用int的话,那我用字符排序那字节+几就是跳过4个字节,单一
{
Swap((char*)base+j*width,(char*)base+(j+1)*width,width);
}
}
}
}

- 点赞
- 收藏
- 关注作者
评论(0)