【分布式与微服务】dubbo分布式服务框架(高级特性篇)

1.序列化
序列化是将Java对象转化为流的数据,流的数据才能在两台主机上进行传输

![]()
dubbo内部已经对序列化和反序列化封装了,我们只需要让实体类实现Serializable接口即可
1.新建一个模块为dubbo-pojo,创建一个User类(先不实现Serializable接口)
public class User {
private int id;
private String name;
private String password;
public User() {
}
public User(int id, String name, String password) {
this.id = id;
this.name = name;
this.password = password;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}2.在dubbo-interface中关联dubbo-pojo,因为我们在接口模块写一个测试user的接口
<dependencies>
<dependency>
<groupId>com.xue</groupId>
<artifactId>dubbo-pojo</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>在UserService接口中新增一个方法
/**
* 查询用户接口
* @return
*/
public User findUserById(int id);3.在dubbo-service模块中实现此方法,并简单返回一个测试的user对象
@Override
public User findUserById(int id) {
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}4.在dubbo-web模块下的UserController中新增find方法
@RequestMapping("/find")
public User find(int id) {
return userService.findUserById(id);
}然后进行tomcat7:run进行测试
然后测试就发现报错了

![]()
控制台报错信息
java.lang.IllegalStateException: Serialized class com.xue.pojo.User must implement java.io.Serializable需要实现Serializable接口
public class User implements Serializable重新启动

![]()
成功访问!
2.地址缓存
面试题:注册中心挂了,服务是否可以正常访问?
可以,因为dubbo服务消费者在第一次调用时,会将服务提供方地址缓存到本地,以后在调用就不会访问注册中心。
当服务提供者地址发生变化时,注册中心会通知服务消费者
停掉zookeeper服务注册中心

![]()
访问成功!

![]()
3.超时
问题描述:
服务消费者在调用服务提供者的时候发生了阻塞、等待的情形,这个时候,服务消费者会一
直等待下去。在某个峰值时刻,大量的请求都在同时请求服务消费者,会造成线程的大量堆
积,势必会造成雪崩。
dubbo利用超时机制来解决这个问题,设置一个超时时间,在这个时间段内,无法完成服务
访问,则自动断开连接。
使用timeout属性配置超时时间,默认值1000,单位毫秒。
1.在dubbo-service模块中配置超时时间,并模拟超时
@Service(timeout = 3000)
public class UserServiceImpl implements UserService {
@Override
public String demo() {
return "hello,Dubbo";
}
@Override
public User findUserById(int id) {
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
//模拟超时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return users[id-1];
}
}2.访问失败,超时

![]()
注意点:
在服务消费方@Reference也可以配置超时时间,并且会覆盖服务提供方的超时时间,也就是说@Reference配置1s,之前服务提供方配置3s,最后结果是1s之后就发生超时
@Reference(timeout = 1000) //远程注入
private UserService userService;建议在服务提供方配置超时时间,毕竟这个服务是服务提供方编写的,在编写时就应该考虑超时时间的配置问题
4.重试
设置了超时时间,在这个时间段内,无法完成服务访问,则自动断开连接。如果出现网络抖动(网
络突然断掉又重新连接上,网络不稳定),则这一次请求就会失败。
Dubbo提供重试机制来避免类似问题的发生。通过retries属性来设置重试次数,默认为2次。(总
共发了三次)
@Service(timeout = 3000,retries = 2) //当前服务3秒超时,重视2次,一共3次
public class UserServiceImpl implements UserService {
int i = 1;
@Override
public String demo() {
return "hello,Dubbo";
}
@Override
public User findUserById(int id) {
System.out.println("服务被调用"+i++);
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
//模拟超时
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return users[id-1];
}
}进行了超时重试

![]()
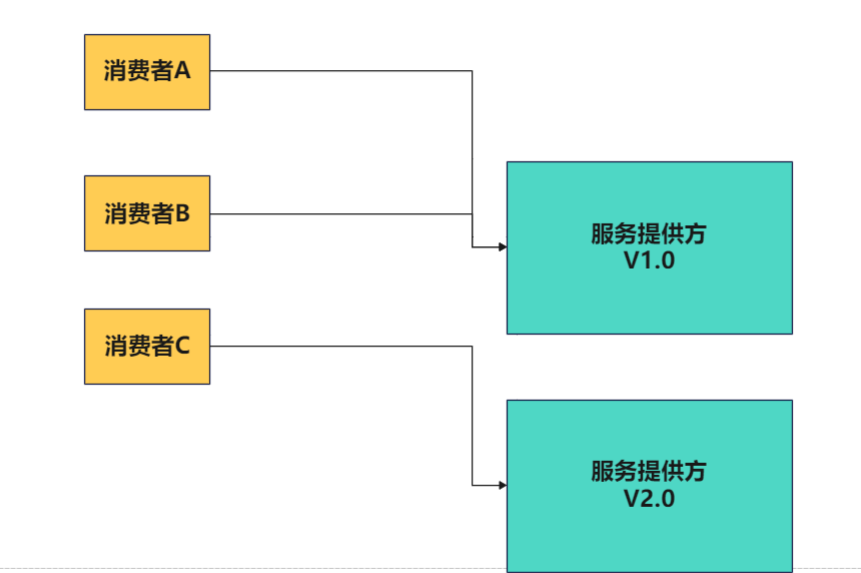
5.多版本
灰度发布: 当出现新功能时,会让一部分用户先使用新功能,用户反馈没问题时,再将所有用户迁
移到新功能。
![]()
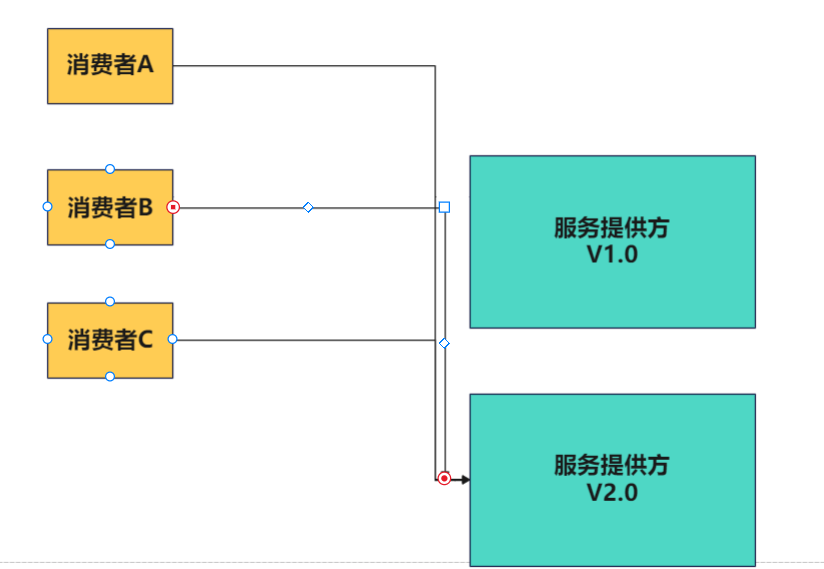
V2.0版本没问题之后再将所有用户迁移到V2.0
![]()
dubbo中使用version属性来设置和调用同一个接口的不同版本
@Service(version = "v1.0")
public class UserServiceImpl implements UserService {
@Override
public String demo() {
return "hello,Dubbo";
}
@Override
public User findUserById(int id) {
System.out.println("v1.0版本");
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}
}1.复制UserServiceImpl类并改为v2.0版本
@Service(version = "v2.0")
public class UserServiceImpl2 implements UserService {
@Override
public String demo() {
return "hello,Dubbo";
}
@Override
public User findUserById(int id) {
System.out.println("v2.0版本");
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}
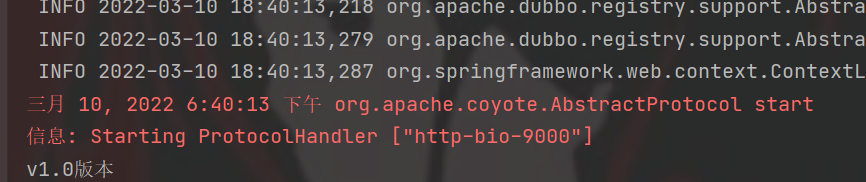
}2.先指定访问v1.0版本,启动
@Reference(version = "v1.0")
private UserService userService;控制台打印v1.0版本
![]()
3.指定访问v2.0版本,重启dubbo-web(不需要重启dubbo-service了)
@Reference(version = "v1.0")
private UserService userService;
![]()
6.负载均衡
负载均衡策略:
1. Random :按权重随机,默认值。按权重设置随机概率。
2. RoundRobin:按权重轮询。
3. LeastActive:最少活跃调用数,相同活跃数的随机。
4. ConsistentHash: 一致性Hash,相同参数的请求总是发到同一提供者。
以默认的Random为例
1.启动 weight = 100 tomcat端口9000 dubbo端口20880 qos端口22222
@Service(weight = 100)
public class UserServiceImpl implements UserService {
@Override
public String demo() {
return "1......";
}
} <debbo:protocol port="20880"/>
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="22222"/>
</dubbo:application>2. 启动weight = 200 tomcat端口9001 dubbo端口20882 qos端口44444 再启动一次tomcat7:run
(注意不是重启上一个而是再启动一个)
@Service(weight = 200)
public class UserServiceImpl implements UserService {
@Override
public String demo() {
return "2......";
}
} <debbo:protocol port="20882"/>
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="44444"/>
</dubbo:application>3. 启动weight = 100 tomcat端口9002 dubbo端口20883 qos端口55555 再启动一次tomcat7:run
@Service(weight = 100)
public class UserServiceImpl implements UserService {
@Override
public String demo() {
return "3......";
}
} <debbo:protocol port="20883"/>
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="55555"/>
</dubbo:application>配置负载均衡的策略random
@Reference(loadbalance = "random" ) 启动dubbo-web模块的tomcat7:run
(我们一个启动了四个tomcat)
访问出现2 说明是第二个服务提供方

![]()
不断刷新出现3 说明是第三个服务提供方

![]()
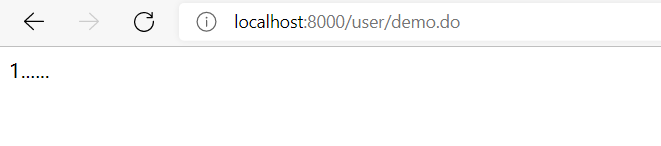
不断刷新出现1 说明是第一个服务提供方
![]()
7.集群容错
集群容错策略:
1. Failover Cluster:失败重试。(默认值)当出现失败,重试其它服务器,默认重试2次,使用
retries配置。一般用于读操作
2. Failfast Cluster : 快速失败,只发起一次调用,失败立即报错。通常用于写操作。
3. Failsafe Cluster : 失败安全,出现异常时,直接忽略。返回一个空结果。
4. FailbackCluster : 失败自动恢复,后台记录失败请求,定时重发。
5. Forking Cluster : 并行调用多个服务器,只要一个成功即返回。Broadcast Cluster :广播调用
所 有提供者,逐个调用,任意一台报错则报错。
以Failover Cluster策略为例
1.启动 tomcat端口9000 dubbo端口20880 qos端口22222
@Service()
public class UserServiceImpl implements UserService {
@Override
public User findUserById(int id) {
System.out.println(1);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}
} <debbo:protocol port="20880"/>
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="22222"/>
</dubbo:application>2. tomcat端口9001 dubbo端口20881 qos端口44444 再启动一次tomcat7:run
@Service()
public class UserServiceImpl implements UserService {
@Override
public User findUserById(int id) {
System.out.println(2);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}
} <debbo:protocol port="20881"/>
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="44444"/>
</dubbo:application>3. tomcat端口9002 dubbo端口20882 qos端口55555 再启动一次tomcat7:run
@Service()
public class UserServiceImpl implements UserService {
@Override
public User findUserById(int id) {
System.out.println(3);
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}
} <debbo:protocol port="20882"/>
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="55555"/>
</dubbo:application>访问成功!

![]()
但是dubbo-web模块的tomcat日志信息出现超时错误,
三个服务提供方的日志信息

![]()

![]()
![]()
发现三个都访问了,但是1和2都会超时(我们通过进程睡眠模拟了超时),消费方会访问1超时,
然后根据Failover Cluster集群容错策略,重试访问2也超时了,再重试一次访问3成功!
8.服务降级
mock=force:return null 表示消费方对该服务的方法调用都直接返回null值,不发起远程调用。用
来屏蔽不重要服务不可用时对调用方的影响。
1.配置服务提供方
@Service()
public class UserServiceImpl implements UserService {
@Override
public User findUserById(int id) {
System.out.println(3);
User[]users = {new User(1,"雪月清","123")
,new User(2,"张三","456")
,new User(3,"李四","156")};
return users[id-1];
}
}2.配置服务消费方
@Reference(mock = "force:return null")3.分别启动服务提供方和服务消费方

![]()
成为了空白页面,服务被屏蔽了
mock=fail:return null 表示消费方对该服务的方法调用在失败后,再返回null值,不抛异常。用来
容忍不重要服务不稳定时对调用方的影响。
修改服务消费方的配置其余不变重新启动
@Reference(mock = "fail:return null")
![]()
(服务提供方我们模拟了超时)失败后重试了三次,但是页面看不到任何信息

![]()

- 点赞
- 收藏
- 关注作者
评论(0)