基于Tensorflow2.x Object Detection API构建自定义物体检测器

这是机器未来的第1篇文章,由机器未来原创
写在前面:
- 博客简介:专注AIoT领域,追逐未来时代的脉搏,记录路途中的技术成长!
- 专栏简介:记录博主从0到1掌握物体检测工作流的过程,具备自定义物体检测器的能力
- 面向人群:具备深度学习理论基础的学生或初级开发者
- 专栏计划:接下来会逐步发布跨入人工智能的系列博文,敬请期待
- Python零基础快速入门系列
- 快速入门Python数据科学系列
- 人工智能开发环境搭建系列
- 机器学习系列
- 物体检测快速入门系列
- 自动驾驶物体检测系列
- …
1. 概述
tensorflow object detection api一个框架,它可以很容易地构建、训练和部署对象检测模型,并且是一个提供了众多基于COCO数据集、Kitti数据集、Open Images数据集、AVA v2.1数据集和iNaturalist物种检测数据集上提供预先训练的对象检测模型集合。
tensorflow object detection api是目前最主流的目标检测框架之一,主流的目标检测模型如图所示:

snipaste20220513_094828
本文描述了基于Tensorflow2.x Object Detection API构建自定义物体检测器的保姆级教程,详细地描述了代码框架结构、数据集的标准方法,标注文件的数据处理、模型流水线的配置、模型的训练、评估、推理全流程。
最终的测试效果如下:标注物体的位置、物体的类型及置信度。

raccoon-28
2. 组织工程文档结构
- • 创建父目录 创建tensorflow文件夹,将下载的object detection api源码models目录拷贝到tensorflow目录下,结构如下:
TensorFlow/
└─ models/
├─ community/
├─ official/
├─ orbit/
├─ research/
└─ ...
- • 创建工作区
cd tensorflow;
mkdir training_demo ;cd training_demo;
创建完毕后的文档组织结构如下:
TensorFlow/
├─ models/
│ ├─ community/
│ ├─ official/
│ ├─ orbit/
│ ├─ research/
│ └─ ...
└─ workspace/
└─ training_demo/
- • 项目目录
mkdir annotations exported-models images/ images/test/ images/train/ models/ pre_trained_models/;
touch README.md
创建完毕后的项目结构如下
training_demo/
├─ annotations/ # annotations存标签映射文件和转换后的TFRecord文件
├─ exported_models/ # 存放训练完毕后导出的模型文件
├─ images/ # 存放原始图像数据文件
│ ├─ test/ # 存放评估图像数据集和标注文件集
│ └─ train/ # 存放训练图像数据集和标注文件集
├─ models/ # 存放训练中的pipline.config、模型数据、tensorboard事件数据
├─ pre_trained_models/ # 存放下载的预训练模型
└─ README.md # 工程说明文档
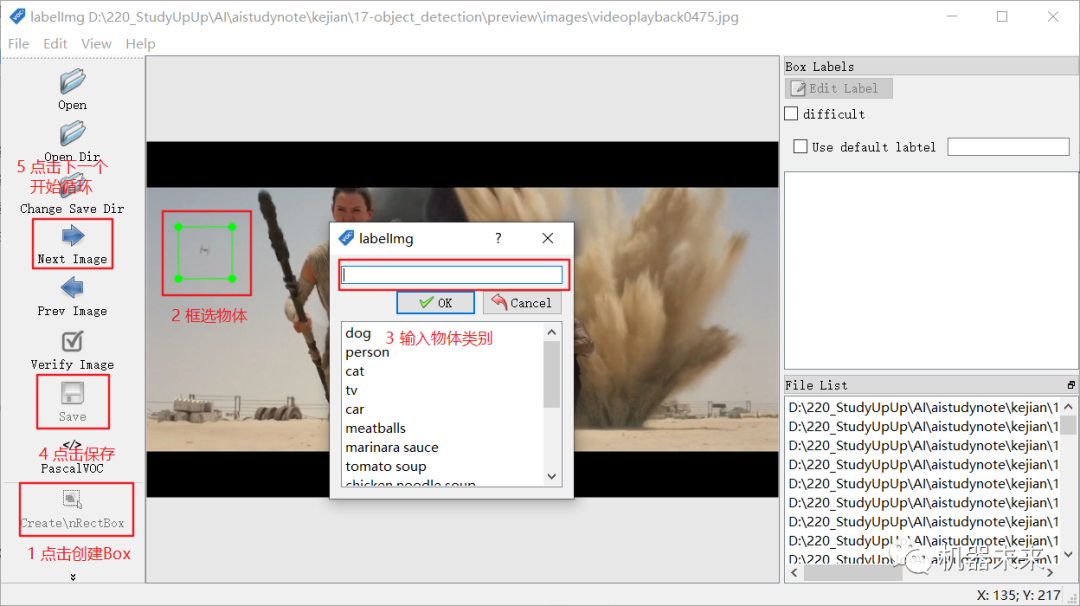
3. 标注数据集
-
• 标注工具labelImg
-
• 项目地址:传送门
-
• 下载地址:windows版本
-
• 标注示例
-
•

0318-2
-
• 标注后的xml文件统一存放到training_demo/images目录下
-
• 划分训练、评估数据集 首先创建一个公共目录
tensorflow/scripts/preprocessing用于存放脚本,便于将来复用
mkdir tensorflow/scripts
mkdir tensorflow/scripts/preprocessing
创建完成后的目录结构如下:
tensorflow/
├─ models/
│ ├─ community/
│ ├─ official/
│ ├─ orbit/
│ ├─ research/
│ └─ ...
├─ scripts/
│ └─ preprocessing/
└─ workspace/
└─ training_demo/
在tensorflow/scripts/preprocessing目录下添加训练集划分脚本partition_dataset.py,脚本内容如下:
""" usage: partition_dataset.py [-h] [-i IMAGEDIR] [-o OUTPUTDIR] [-r RATIO] [-x]
Partition dataset of images into training and testing sets
optional arguments:
-h, --help show this help message and exit
-i IMAGEDIR, --imageDir IMAGEDIR
Path to the folder where the image dataset is stored. If not specified, the CWD will be used.
-o OUTPUTDIR, --outputDir OUTPUTDIR
Path to the output folder where the train and test dirs should be created. Defaults to the same directory as IMAGEDIR.
-r RATIO, --ratio RATIO
The ratio of the number of test images over the total number of images. The default is 0.1.
-x, --xml Set this flag if you want the xml annotation files to be processed and copied over.
"""
import os
import re
from shutil import copyfile
import argparse
import math
import random
def iterate_dir(source, dest, ratio, copy_xml):
source = source.replace('\\', '/')
dest = dest.replace('\\', '/')
train_dir = os.path.join(dest, 'train')
test_dir = os.path.join(dest, 'test')
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
images = [f for f in os.listdir(source)
if re.search(r'([a-zA-Z0-9\s_\\.\-\(\):])+(?i)(.jpg|.jpeg|.png)$', f)]
num_images = len(images)
num_test_images = math.ceil(ratio*num_images)
for i in range(num_test_images):
idx = random.randint(0, len(images)-1)
filename = images[idx]
copyfile(os.path.join(source, filename),
os.path.join(test_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
copyfile(os.path.join(source, xml_filename),
os.path.join(test_dir,xml_filename))
images.remove(images[idx])
for filename in images:
copyfile(os.path.join(source, filename),
os.path.join(train_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
copyfile(os.path.join(source, xml_filename),
os.path.join(train_dir, xml_filename))
def main():
# Initiate argument parser
parser = argparse.ArgumentParser(description="Partition dataset of images into training and testing sets",
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument(
'-i', '--imageDir',
help='Path to the folder where the image dataset is stored. If not specified, the CWD will be used.',
type=str,
default=os.getcwd()
)
parser.add_argument(
'-o', '--outputDir',
help='Path to the output folder where the train and test dirs should be created. '
'Defaults to the same directory as IMAGEDIR.',
type=str,
default=None
)
parser.add_argument(
'-r', '--ratio',
help='The ratio of the number of test images over the total number of images. The default is 0.1.',
default=0.1,
type=float)
parser.add_argument(
'-x', '--xml',
help='Set this flag if you want the xml annotation files to be processed and copied over.',
action='store_true'
)
args = parser.parse_args()
if args.outputDir is None:
args.outputDir = args.imageDir
# Now we are ready to start the iteration
iterate_dir(args.imageDir, args.outputDir, args.ratio, args.xml)
if __name__ == '__main__':
main()
执行脚本:
python partition_dataset.py -x -i [PATH_TO_IMAGES_FOLDER] -r [test_dataset ratio]
示例:
python partition_dataset.py -x -i ../../training_demo/images/ -r 0.1
# -x 表明输入文件格式是xml文件
# -i 指定图像文件所在目录
# -r 指定训练集、评估集切分比例,0.1代表评估集占比10%
4. 创建标签分类映射文件
在training_demo/annotations目录下创建label_map.pbtxt,内容为标签分类及ID, 示例如下:
item {
id: 1
name: 'cat'
}
item {
id: 2
name: 'dog'
}
示例表明数据集一共有2个类别,分别为cat和dog,分配的分类ID分别为1和2
5. 将标注数据xml文件转换为record格式文件
- • 脚本内容如下:
""" Sample TensorFlow XML-to-TFRecord converter
usage: generate_tfrecord.py [-h] [-x XML_DIR] [-l LABELS_PATH] [-o OUTPUT_PATH] [-i IMAGE_DIR] [-c CSV_PATH]
optional arguments:
-h, --help show this help message and exit
-x XML_DIR, --xml_dir XML_DIR
Path to the folder where the input .xml files are stored.
-l LABELS_PATH, --labels_path LABELS_PATH
Path to the labels (.pbtxt) file.
-o OUTPUT_PATH, --output_path OUTPUT_PATH
Path of output TFRecord (.record) file.
-i IMAGE_DIR, --image_dir IMAGE_DIR
Path to the folder where the input image files are stored. Defaults to the same directory as XML_DIR.
-c CSV_PATH, --csv_path CSV_PATH
Path of output .csv file. If none provided, then no file will be written.
"""
import os
import glob
import pandas as pd
import io
import xml.etree.ElementTree as ET
import argparse
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import tensorflow.compat.v1 as tf
from PIL import Image
from object_detection.utils import dataset_util, label_map_util
from collections import namedtuple
# Initiate argument parser
parser = argparse.ArgumentParser(
description="Sample TensorFlow XML-to-TFRecord converter")
parser.add_argument("-x",
"--xml_dir",
help="Path to the folder where the input .xml files are stored.",
type=str)
parser.add_argument("-l",
"--labels_path",
help="Path to the labels (.pbtxt) file.", type=str)
parser.add_argument("-o",
"--output_path",
help="Path of output TFRecord (.record) file.", type=str)
parser.add_argument("-i",
"--image_dir",
help="Path to the folder where the input image files are stored. "
"Defaults to the same directory as XML_DIR.",
type=str, default=None)
parser.add_argument("-c",
"--csv_path",
help="Path of output .csv file. If none provided, then no file will be "
"written.",
type=str, default=None)
args = parser.parse_args()
if args.image_dir is None:
args.image_dir = args.xml_dir
label_map = label_map_util.load_labelmap(args.labels_path)
label_map_dict = label_map_util.get_label_map_dict(label_map)
def xml_to_csv(path):
"""Iterates through all .xml files (generated by labelImg) in a given directory and combines
them in a single Pandas dataframe.
Parameters:
----------
path : str
The path containing the .xml files
Returns
-------
Pandas DataFrame
The produced dataframe
"""
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
filename = root.find('filename').text
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text)
for member in root.findall('object'):
bndbox = member.find('bndbox')
value = (filename,
width,
height,
member.find('name').text,
int(bndbox.find('xmin').text),
int(bndbox.find('ymin').text),
int(bndbox.find('xmax').text),
int(bndbox.find('ymax').text),
)
xml_list.append(value)
column_name = ['filename', 'width', 'height',
'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def class_text_to_int(row_label):
return label_map_dict[row_label]
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(args.output_path)
path = os.path.join(args.image_dir)
examples = xml_to_csv(args.xml_dir)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
print('Successfully created the TFRecord file: {}'.format(args.output_path))
if args.csv_path is not None:
examples.to_csv(args.csv_path, index=None)
print('Successfully created the CSV file: {}'.format(args.csv_path))
if __name__ == '__main__':
tf.app.run()
- • 注意事项 在使用脚本之前,请确认已经安装了pandas,使用脚本确认是否安装,如下命令显示版本号即为安装:
root@cc58e655b170# python -c "import pandas as pd;print(pd.__version__)"
1.4.1
未安装时,可以按照当前环境安装
conda install pandas # Anaconda
# or
pip install pandas # pip
- • 脚本调用格式
# Create train data:
python generate_tfrecord.py -x [PATH_TO_IMAGES_FOLDER]/train -l [PATH_TO_ANNOTATIONS_FOLDER]/label_map.pbtxt -o [PATH_TO_ANNOTATIONS_FOLDER]/train.record
# Create test data:
python generate_tfrecord.py -x [PATH_TO_IMAGES_FOLDER]/test -l [PATH_TO_ANNOTATIONS_FOLDER]/label_map.pbtxt -o [PATH_TO_ANNOTATIONS_FOLDER]/test.record
- • 使用脚本转换train、test数据集
# For example
root@cc58e655b170:/home/zhou/tensorflow/workspace/scripts/preprocessing# python generate_tfrecord.py -x ../../training_demo/images/train/ -l ../../training_demo/annotations/label_map.pbtxt -o ../../training_demo/annotations/train.record
Successfully created the TFRecord file: ../../training_demo/annotations/train.record
root@cc58e655b170:/home/zhou/tensorflow/workspace/scripts/preprocessing# python generate_tfrecord.py -x ../../training_demo/images/test/ -l ../../training_demo/annotations/label_map.pbtxt -o ../../training_demo/annotations/test.record
Successfully created the TFRecord file: ../../training_demo/annotations/test.record
脚本执行完毕后,在training_demo/annotations目录下会生成train.record和test.record文件
root@cc58e655b170:/home/zhou/tensorflow/workspace/scripts/preprocessing# ls ../../training_demo/annotations/
label_map.pbtxt test.record train.record
参考资料:
-
• 异常:ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
-
• 异常:在使用tensorboard时报错tensorboard: error: invalid choice: ‘Recognizer\logs’ (choose from ‘serve’, ‘dev’)
源代码及数据集免费获取方式:点赞、关注,公众号后台发送519获取下载链接
推荐阅读:
- 物体检测快速入门系列(1)-Windows部署GPU深度学习开发环境
- 物体检测快速入门系列(2)-Windows部署Docker GPU深度学习开发环境
- 物体检测快速入门系列(3)-TensorFlow 2.x Object Detection API快速安装手册
- 物体检测快速入门系列(4)-基于Tensorflow2.x Object Detection API构建自定义物体检测器


- 点赞
- 收藏
- 关注作者
评论(0)