openGauss 磁盘引擎之 ustore

ustore属于In-place Update更新模式,中文意思为:原地更新,是openGauss内核新增的一种存储模式。openGauss内核当前使用的行引擎采用的是Append Update(追加更新)模式,该模式在INSERT、DELETE、HOT UPDATE(页面内更新)的场景下有较好的表现。但对于非HOT UPDATE场景,垃圾回收不够高效。
In-place Update存储模式提供“原地更新”能力,主要思路是将最新版本的“有效数据”和历史版本的“垃圾数据”分离存储。将最新版本的“有效数据”存储在数据页面上,而单独开辟一段undo(回滚)空间,用于统一管理历史版本的“垃圾数据”,因此数据空间不会由于频繁更新而膨胀,垃圾回收效率更高。通过NUMA-aware的undo子系统设计,使得undo子系统在多核平台上高效扩展。同时通过对元组和数据页面结构的重新设计,减少存储空间的占用。采用多版本索引技术,解决索引膨胀问题,彻底去除autovacuum(垃圾清理线程)机制,提升存储空间的回收复用效率。
一、整体框架及代码概览
数据库中数据处理的本质是在保证ACID的基础上支持尽量高的并发查询。这种状况下,并发控制、页面多版本控制以及页面存储结构相互耦合在一起,数据库存储引擎需要进行整体设计从而在高并发的状况下保证各个事务处理看到类似串行执行的效果。
在整个技术体系中多版本控制用来提升读写并发能力,按照多版本排列方式可以分为两类。
(1)Oldest to New,即版本按照从最老到最新的方式进行链接,当一个事务访问该元组时,先看到这个元组最老的版本,同时使用对应的可见性判断机制,看是否是自己可见的版本,如果不是则沿着版本链条继续往后看较新的版本是不是自己需要的。
(2)Newest to Old,即版本按照从最新到最老的方式进行连接,当一个事务访问该元组时,先看到这个元组最新的版本,同时使用对应的可见性判断机制,看是否是自己可见的版本,如果不是则沿着版本链条继续往后看较老的版本是不是自己需要的。
在上面的描述中又引出一个设计点,如何组织新老数据,有如下几种方式。
(1) 将新数据和老数据放在同样的页面内,即每个数据页内放置着各个元组的新老数据,在需要进行不可见数据版本回收的时候需要遍历所有的页面。
(2) 将最新数据和老数据分离存储,在实际的数据页面内放置最新版本数据,所有的老版本数据都集中存储,新版本数据通过一个指针指向老版本所在的数据区域,当进行不可见老版本数据回收的时候只要扫描老版本集中存放的位置即可。
当新老数据分别存储的时候又引出第三个设计点,在对同一个页面或者元组反复读取时,是否要还原对应的页面在数据缓冲区中,这个设计点有如下几种方式。
(1) 访问旧元组所在的页面时,还原该页面,并将该页面的旧版本放入数据缓冲区中,节省一定时间内其他线程多次访问该版本页面带来的合成开销。弊端是占用更大的内存空间,同时缓冲区淘汰管理在原始LRU(Least Recently Used,最近最少使用算法)基础上同时要考虑页面版本。这种方式对应PCR(Page Consistency Read,页面一致性读),其本质的设计理念是空间换时间。
(2) 访问元组时,沿着版本链还原该元组,直到找到自己对应的版本。这种方式对于短时间访问冲突不高的场景能够降低内存使用,但如果短时间内高频访问一个页面内的元组,则每次都会遍历版本链造成访问效率低下。这种方式对应RCR(Row Consistency Read,行一致性读)。
按照上面的描述,整个多版本控制设计分为三个维度,如下图、表所示。
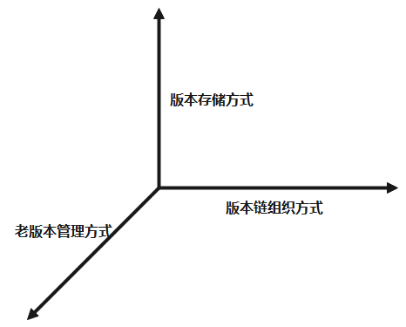
多版本控制设计维度
表 多版本控制设计维度
| 维度 |
备选 |
| 版本存储方式 |
集中存储 分离存储 |
| 版本链组织方式 |
Oldest to New Newest to Old |
| 老版本管理方式 |
1、RCR 2、PCR |
当前openGauss在版本存储方式、版本链组织方式上的设计选择是集中存储 + Oldest to New,在清理数据旧版本时需要遍历所有的页面找到不可见的元组版本然后清除。商用及开源的常见数据库的多版本控制设计三维度选择如表所示。
表 当前数据库多版本控制设计选择
| 数据库 |
架构设计选择 |
||
| 版本存储方式 |
版本链组织方式 |
老版本管理方式 |
|
| 常见数据库 |
分离存储 |
Newest to Old |
PCR |
| 集中存储 |
Oldest to New |
RCR |
|
| 分离存储 |
Oldest to New |
RCR |
|
不同的多版本控制设计都不能做到尽善尽美,都有些不足之处,相关的缺点如下。
(1)多核系统上扩展性较差,不支持多核处理器的NUMA感知;
(2)依赖于Vacuum进行老版本回收,后台线程定期清理;
(3)缺乏对索引多版本,全局索引、闪回等功能的支持;
(4)PCR管理方式,内存管理开销较大。
openGauss的ustore存储模式最大程度结合各种设计的优势,在多版本管理上的架构设计采取的组合如表所示。
表 ustore在多版本管理上的架构设计
| 维度 |
架构设计选择 |
| 版本存储方式 |
分离存储 |
| 版本链组织方式 |
Newest to old |
| 老版本管理方式 |
PbRCR(Page Based RCR,基于页面的行一致性读) |
同时为了事务能够跨存储格式查询,并复用现有备份、恢复、升级等能力,openGauss定义如下的融合引擎架构设计原则。
(1) 一套并发控制系统。
(2) 一套系统表管理系统。
(3) 一套日志管理系统。
(4) 一套锁管理系统。
(5) 一套恢复系统。
ustore架构如图所示。

ustore架构示意图
ustore和astore共用事务管理、并发控制、缓冲区管理、检查点、故障恢复管理与介质管理器管理。ustore主要功能模块如表所示。
表 ustore主要功能模块
| 模块 |
说明 |
代码位置 |
| ustore表存取管理 |
向上对接SQL引擎,提供对ustore表的行级查询、插入、删除、修改等操作接口,向下根据ustore表页间、页内结构,以及ustore表元组结构,完成对ustore表文件的遍历和增删改查操作 |
主要在“src/gausskernel/storage/access/ustore”目录(单表文件管理)下 |
| ustore索引存取管理 |
向上对接SQL引擎,提供对索引表的行级查询、插入、删除等操作接口,向下根据索引表页间、页内结构,以及索引表元组结构,完成对指定索引键的查找和增删操作 |
抽象框架代码在“src/gausskernel/storage/access/ubtree”目录下 |
| ustore表页面结构 |
包括ustore表元组在页面内的具体组织形式,在页面内插入元组操作、页面整理操作、页面初始化操作等 |
主要代码在“src/gausskernel/storage/access/ustore/knl_upage”目录中 |
| ustore表元组结构 |
包括ustore表元组的结构、填充、解构、修改、字段查询、变形等操作 |
主要代码在“src/gausskernel/storage/access/ustore/knl_utuple.cpp”文件中 |
| Undo记录结构 |
包括undo记录的结构、填充、编码、解码等操作 |
主要代码在“src/gausskernel/storage/access/ustore/undo”目录中 |
| 多版本索引 |
包括 ustore 专用多版本索引 ubtree 的页面结构、查询、修改、可见性检查、垃圾回收等模块 |
主要代码在“src/gausskernel/storage/access/ubtree”目录中 |
二、页面元组结构
1) 元组结构
本节介绍行存储引擎ustore表的页面元组结构。
元组结构的定义如下:
typedef struct UHeapDiskTupleData {
ShortTransactionId xid;
uint16 td_id : 8, locker_td_id : 8;
uint16 flag;
uint16 flag2;
uint8 t_hoff;
uint8 data[FLEXIBLE_ARRAY_MEMBER];
} UHeapDiskTupleData;
该结构体只是元组头部的定义,真正的元组内容跟在该结构体之后,距离元组头部起始处的偏移由t_hoff成员保存。上面元组头部结构体部分成员信息同时也构成了该元组的系统字段(字段序号小于0的那些字段)。对各个结构体成员的含义说明如下。
(1) flag,元组属性掩码。包含是否有空字段标记、是否有外部TOAST标记、是否有变长字段标记、指定的事务槽位是否已被重复使用标记,以及更新、删除、锁等标记。
(2) flag2,元组另一个属性掩码。包含元组中字段个数。
(3) t_hoff,元组数据距离元组头部结构体起始位置的偏移。
(4) data,字段的NULL值bitmap,每个字段对应一个bit位,因此是变长数组。
ustore元组头部比astore元组头部小一半,因此在相同大小的页面上,ustore可以放置更多的元组。
在内存中,上述元组结构体使用时被嵌入在一个更大的元组数据结构体中,除了保存元组内容的disk_tuple成员之外,其他的成员保存了该元组的一些其他系统信息,并构成了该元组剩余的一些系统字段内容,定义如下:
typedef struct UHeapTupleData {
uint32 disk_tuple_size;
uint1 tupTableType = UHEAP_TUPLE;
uint1 tupInfo;
int2 t_bucketId;
ItemPointerData ctid;
Oid table_oid;
TransactionId t_xid_base;
TransactionId t_multi_base;
UHeapDiskTupleData* disk_tuple;
} UHeapTupleData;
该结构体几个主要成员的含义如下。
(1) disk_tuple_size,元组长度。
(2) ctid,元组所在页面号和页面内元组指针下标。
(3) table_oid,该元组属主表的OID。
常用的元组操作接口和说明如表所示。
表 常用的元组操作接口
| 函数名 |
操作含义 |
| UHeapFormTuple |
利用传入的、各个元组字段的值数组,生成一条完整的元组,一般用于插入操作 |
| UHeapDeformTuple |
利用传入的完整元组以及各个字段的类型定义,解构各个字段的值,生成值数组,一般用于更新前的准备工作 |
| UHeapFreetuple |
释放一条元组对应的内存空间 |
| UHeapCopyTuple |
复制一条完整的元组,包括元组头和元组内容 |
| UHeapSlotGetAttr |
获取一条元组中指定的用户或系统字段值 |
| UHeapGetSysAttr |
获取一条元组中指定的系统字段值 |
| UHeapCopyHeapTuple |
从ustore槽位构造一条astore元组 |
| UHeapToHeap |
将一条ustore元组转换为一条astore元组 |
| HeapToUHeap |
将一条astore元组转换为一条ustore元组 |
2) 页面结构
ustore与astore相同,在openGauss中也使用默认的8kB页面。其结构如图所示。
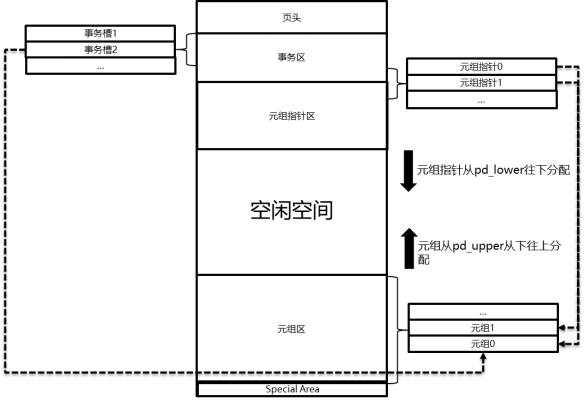
ustore引擎页面结构示意图
在一个页面中,页面头部分对应的UHeapPageHeaderData结构体存储了整个页面的重要元信息。UHeapPageHeaderData之后有一个共享的页内事务目录(Transaction Directory,TD),对应元组指针变长数组。元组指针变长数组的每个数组成员存储了页面中从后往前的、每个元组的起始偏移和元组长度。如图4-12所示,真正的元组内容从页面尾部开始插入,向页面头部扩展;相应地,TD插槽目录与记录每条元组的元组指针从页面头定长成员之后插入,往页面尾部扩展。这样整个页面中间就会形成一个空洞,以供后续插入的元组和元组指针使用。每一个ustore表里的一条具体元组都有一个全局唯一的逻辑地址(和astore表里的元组相同),它由元组所在的页面号和页面内元组指针数组下标组成。
页面头具体结构体定义如下:
typedef struct UHeapPageHeaderData {
PageXLogRecPtr pd_lsn;
uint16 pd_checksum;
uint16 pd_flags;
uint16 pd_lower;
uint16 pd_upper;
uint16 pd_special;
uint16 pd_pagesize_version;
uint16 potential_freespace;
uint16 td_count;
TransactionId pd_prune_xid;
TransactionId pd_xid_base;
TransactionId pd_multi_base;
uint32 reserved;
} UHeapPageHeaderData;
其中各个成员的含义如下。
(1) pd_lsn:该页面最后一次修改操作对应的预写日志位置的下一位,用于检查点推进和保持恢复操作的幂等性。
(2) pd_checksum:页面的CRC校验值。
(3) pd_flags:页面标记位,用于保存各类页面相关的辅助信息,如页面是否有空闲的元组指针、页面是否已满等。
(4) pd_lower:页面中间空洞的起始位置,即当前已使用的元组指针数组的尾部。
(5) pd_upper:页面中间空洞的结束位置,即下一个可以插入元组的起始位置。
(6) pd_special:页面尾部特殊区域的起始位置。该特殊位置位于第一条元组记录和页面结尾之间,用于存储一些变长的页面级元信息,如索引的辅助信息等。
(7) pd_pagesize_version:页面的大小和版本号。
(8) potential_freespace:页面中已被删除和更新的元组的潜在空间。
(9) td_count:共享的页内事务信息描述插槽的数量。
(10) pd_prune_xid:页面清理辅助事务号(64位),通常为该页面内现存最老的删除或更新操作的事务号,用于判断是否要触发页面级空闲空间整理。
(11) pd_xid_base:该页面内所有元组的基准事务号(64位)。该页面所有元组实际生效的64位XID事务号由pd_xid_base(64位)和元组头部的XID成员(32位)相加得到。
(12) pd_multi_base:类似pd_xid_base。当对元组加锁时,会将持锁的事务号写入元组中,该64位事务号由pd_multi_base(64位)和元组头部的XID(32位)相加得到。
页面的主要管理接口如表所示。
表 页面管理接口函数
| 函数名 |
操作含义 |
| UPageInit |
初始化一个新的ustore页面 |
| UPageAddItem |
在页面中插入一条新的元组 |
| UHeapPagePruneOptPage |
页面空闲空间整理 |
为了节省每个元组存储空间,元组头部UHeapDiskTupleData采用32位元组XID的组合设计方式。64位的pd_xid_base和pd_multi_base储存在页面上,元组上储存32位的XID。页面上pd_xid_base和pd_multi_base也需要通过额外的逻辑进行维护:同一个页面中所有元组实际的64位XID,一定要在pd_xid_base和pd_xid_base+232之间,所以如果新写入的事务号和页面上现有任意一个元组的XID事务号差距已经超过232,那么需要尝试对现有元组进行基线移位操作,更新pd_xid_base和pd_multi_base。
3)事务目录
事务目录是一种常用的共享资源。它可以为数据页上的元组(tuple)链接相应的事务表(Transaction Table)及undo子系统中的undo页面。数据库中的每个表可以自定义事务目录的数量,并可以复用那些已完成事务占据的事务目录。
每个数据页默认会有4个事务目录。根据并发需求的不同,事务目录的数量可设置为2到128之间的任意值。在使用CREATE TABLE命令创建表时添加了一个新的选项INIT_TD以声明所需的事务目录数量:
CREATE TABLE t1
(
c1 integer;
c2 boolean;
) WITH (INIT_TD=16);
当需要为新事务目录留位置时,系统会先查找当前页面中是否有空事务目录。若无空事务目录,系统将遍历事务目录列表来寻找可以复用的条目。条目是否可以复用取决于与该条目关联的事务的状态。
通常可以复用那些与已冻结或已中止的事务关联的事务目录。
(1) 对于已经冻结的XID,并复用该事务目录。
对于astore而言,冻结的XID代表着事务在所有的会话中都已经不再活跃。
而在ustore中,仅当一个事务创建的所有的回滚记录都被丢弃后,或者说没有其他的Snapshot需要再观察该事务创建的元组历史版本(tuple version)时,才将该XID视为冻结。ustore中的undo回收进程会维护一个oldestXidInUndo变量,系统将通过比较XID与该变量来确定XID是否含有回滚记录。如果XID < oldestXidInUndo,代表所有该XID产生的回滚记录都已经被丢弃。
(2) 对于已中止的事务,在该事务被回滚后,系统才会复用相应的事务目录条目。
(3) 对于已提交的事务,系统将不会无效化回滚记录地址,这样可以保证undo链的完整性。
当没有事务目录可以复用时,事务目录将会自动扩容以容纳更多的条目。需注意的是,事务目录的后面跟随着元组指针区,在扩展时,首先需要将row pointer array向右挪动来腾出空间。扩展后,新的事务目录条目将会在先前的事务目录条目之后依序添加。设计上,允许事务目录的容量最多扩至页面大小的约25%,即约100个事务目录(在8kB大小的页面中,约20Bytes/事务目录)。目前,系统将以每次增加两个事务目录的方式逐步扩容,最多扩至128个事务目录。ustore暂不支持收缩事务目录空间。
在扩容时,可以增加的总条目数也取决于当前页面中的可用空间。有时,页面中的总剩余空间并不能支持事务目录的扩容。此时若当前操作为INSERT或MULTI-INSERT,事务将会索取一个新的页面来进行操作。若操作为UPDATE或DELETE,事务将等待10毫秒后重试获取事务目录。Lock timeout设置可以控制获取事务目录的最大等待时间。在多由短事务组成的工作负载中,等待是可以接受的。
PG stats会报告事务目录等待等信息,以方便监测系统及描述工作负载。
事务目录申请的过程(UHeapPageReserveTransactionSlot函数)如图所示。
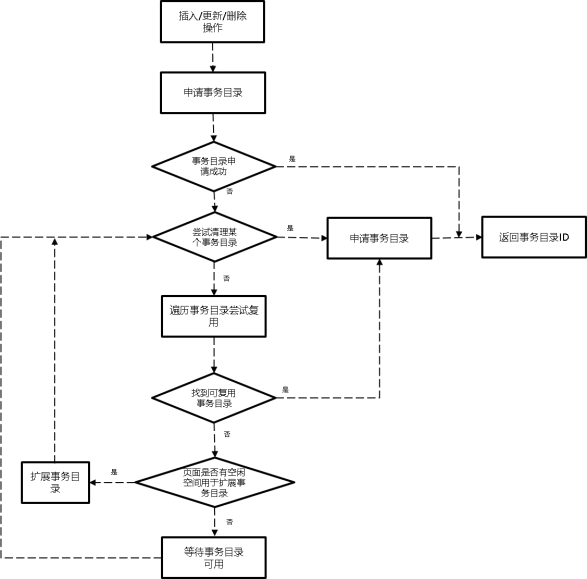
事务目录申请处理流程
如果当前事务需要申请一个新的事务目录,且系统中不存在空的事务目录时,系统会遍历所有事务目录并寻找可复用的事务目录。
(1) 首先系统会遍历事务目录,寻找XID < oldestXidInUndo的事务目录。这些条目将被视为已冻结。
(2) 接着系统会遍历目标页面上的元组。
① 系统把已删除的元组标记为死亡,其余的标记为闲置。
② 如果系统发现元组还在活跃状态,且相应的TD条目存在于步骤(1)给出的冻结列表之中,系统会把该事务目录设置为UHEAPTUP_SLOT_FROZEN(冻结)。
③ 设置为冻结之后,事务目录中的XID及Undo指针会被无效化。
(3) 如果上述的冻结操作并未产生可用的槽位,系统会遍历事务目录并寻找与已提交或已中止事务关联的条目。这些条目在满足一定条件的状况下可被复用。
(4) 遍历目标页面上的元组。
① 如果系统发现元组关联的事务目录存在于步骤(3)给出的已提交列表中,系统就把该TD条目的flag设为UHEAP_INVALID_XACT_SLOT(无效)。
② 此外,这些事务目录的XID被重设为无效XID。但为了维护undo链的完整,undo指针将被保留。
(5) 如果并未找到与已提交事务关联的事务目录,最后将寻找与已中止事务关联的事务目录。
(6) 遍历与已中止事务关联的事务目录:对于每个事务目录,沿着undo链执行相关的undo操作。
(7) 如果并未找到事务目录,扩展事务目录。
(8) 返回结果。
3. 回滚段设计与MVCC
1) 回滚段
旧版本数据会集中在回滚段的undo目录中,为了减少读写冲突,旧版本数据(回滚记录)采用追加写的方式写入数据目录的undo目录下。这样旧版本数据的读取和写入不会发生冲突,同一个事务的旧版本数据也会连续存放,便于进行回滚操作。为了减少并发写入时的竞争,undo目录空间被划分成多个逻辑区域(UndoZone,回滚段逻辑区域)。线程会在自己的逻辑区域上进行分配,与其他线程完全隔离,从而写入旧数据分配空间时就不会有额外的锁开销。UndoZone还可以按照CPU的NUMA核进行划分,每个线程会从当前的NUMA核上的UndoZone进行分配,进一步提升分配效率。在分配undo空间时会按照事务粒度进行记录,旧版本数据一旦确认没有事务进行访问,就会进行回收。
为了在回滚段的空间寻址,回滚记录使用8字节的指针来进行寻址,如图所示。

回滚记录寻址指针
其中各个字段的含义如下:
(1) zoneId:占用20bit,表示逻辑区域的ID。
(2) blockId:占用31bit,表示块号,默认为8k。
(3) offset:占用13bit,表示块内偏移。
旧版本的数据采用回滚记录的格式存入回滚段中,其中回滚记录的格式如下所示:
Class UndoRecord {
…
UndoRecordHeader whdr_;
UndoRecordBlock wblk_;
UndoRecordTransaction wtxn_;
UndoRecordPayload wpay_;
UndoRecordOldTd wtd_;
UndoRecordPartition wpart_;
UndoRecordTablespace wtspc_;
StringInfoData rawdata_;
}
其中,除了rawdata_代表了旧版本数据,其他成员均为结构体,下面对每个结构体分别进行说明。
whdr_成员由下面的结构组成:
typedef struct {
TransactionId xid;
CommandId cid;
Oid reloid;
Oid relfilenode;
uint8 utype;
uint8 uinfo;
} UndoRecordHeader;
各个字段的含义如下。
(1) xid:生成此回滚记录的事务ID,用于检查事务的可见性。“2)MVCC”小节有介绍。
(2) CID(Command ID,命令ID):生成此回滚记录的命令ID,用于判断可见性。
(3) reloid:relation对象的ID,回滚时需要。
(4) relfilenode:relfilenode对象的ID,回滚时需要。
(5) utype:操作类型,像UNDO_INSERT、UNDO_DELETE、UNDO_UPDATE等。
(6) uinfo:控制字段,用来判断后续的结构是否存在,用来减少回滚记录的占用空间。
wblk_成员由下面的结构组成:
typedef struct {
UndoRecPtr blkprev;
BlockNumber blkno;
OffsetNumber offset;
} UndoRecordBlock;
(1) blkprev:指向同一个block前一条回滚记录,用于回滚和事务可见性。“2)MVCC”小节有介绍。
(2) blkno:block number(块号)。
(3) Offset:修改的tuple在row pointer中的偏移。
wtxn_成员由下面的结构组成。
typedef struct {
UndoRecPtr prevurp;
} UndoRecordTransaction;
prevurp:当一个事务的回滚记录跨越两个UndoZone时,后续的回滚记录使用此指针指向前一条回滚记录。
wpay_成员由下面的结构组成。
typedef struct {
UndoRecordSize payloadlen;
}
payloadlen:rawdata_的长度。
wtd_成员由下面的结构组成。
typedef struct {
TransactionId oldxactid;
} UndoRecordOldTd;
oldxactid:旧版本数据里事务目录的事务ID。
wpart_成员由下面的结构组成。
typedef struct {
Oid partitionoid;
} UndoRecordPartition;
partitionoid:分区表的分区对象OID。
wtspc_成员由下面的结构组成。
typedef struct {
Oid tablespace;
} UndoRecordTablespace;
tablespace:表空间的OID。
回滚段使用事务目录来记录每个事务分配的undo空间,便于事务回滚和回收。事务发生回滚时,会读取事务目录中记录的undo空间的起始位置,再读取undo空间中的回滚记录进行回滚操作,其中回滚记录中的字段如下:
class TransactionSlot {
TransactionId xactId_;
UndoRecPtr startUndoPtr_;/*事务分配的undo空间开始*/
UndoRecPtr endUndoPtr_;/*事务分配的undo空间结束*/
uint8 info_;/*标记:如事务回滚状态*/
Oid dbId_;/*数据库对象ID*/
}
(1) xactId:事务ID。
(2) startUndoPtr:事务分配的undo空间开始位置。
(3) endUndoPtr:事务分配的undo空间结束位置。
(4) info_:标记值,如事务回滚状态。
(5) dbId:数据库对象ID。
回滚段提供分配undo空间和更新事务目录的接口,主要接口如表所示。
表 回滚段主要接口
| 接口名 |
含义 |
| AllocateUndoSpace |
为回滚记录分配undo空间 |
| UpdateTransactionSlot |
更新事务目录 |
以ustore的删除操作为例,undo空间分配流程如下。
(1) UheapDelete作为ustore的删除接口,会调用UHeapPrepareUndoDelete函数准备回滚记录(undo record)。UHeapPrepareUndoDelete函数会填充回滚记录的各个字段(其中旧数据会设置到回滚记录的raw data字段上),再调用PrepareUndoRecord函数分配undo空间。PrepareUndoRecord函数调用“undo::AllocateUndoSpace”函数分配undo空间,再读取对应的回滚记录到缓冲池中。AllocateUndoSpace函数不仅会为回滚记录分配空间(使用“UndoZone::AllocateSpace”函数),如果是事务的第一条回滚记录,还会调用“UndoZone::AllocateSlotSpace”函数为事务目录分配空间。AllocateSpace函数会进行判断,如果回滚记录超过当前undo file的大小,就扩展当前的undo file,AllocateSlotSpace函数的逻辑类似。
(2) UheapDelete函数调用InsertPreparedUndo函数,将准备好的回滚记录追加写到缓冲池中的回滚段页面。
(3) UheapDelete函数调用UpdateTransactionSlot,记录下该事务分配的undo空间起始、事务ID、数据库ID。如果是事务的第一次更新,会从事务目录空间分配新的事务目录再进行更新。
undo空间需要回收回滚记录来保证undo空间不会无限膨胀,一旦事务id小于当前快照中最小的Xmin(oldestXmin),回滚记录中的旧版本数据就不会被访问,此时就可以对回滚记录进行回收。
如前述描述undo空间中的回滚记录按照事务ID递增的顺序存放在UndoZone中,回收的条件如下所示。
(1) 事务已经提交并且小于oldestXmin的undo空间可以回收。
(2) 事务发生回滚但已经完成回滚的undo空间可以回收。

undo回收过程
如上图所示,UndoZone1中回收到小于oldestXmin的已提交事务16068,UndoZone2中回收到16050,UndoZone m回收到16056。而UndoZone n回收到事务16012,而事务16014待回滚但未发生回滚,因此UndoZone n回收事务id上限只到16014。其他zone的上限是oldestXmin,oldestXidInUndo会取所有undozone上的上限最小值,因此oldestXidInUndo等于16014。undo回收主要函数如表所示。
表 undo回收主要函数
| 函数名 |
操作含义 |
| UndoRecycleMain |
回收线程的入口函数,会在每个zone上调用RecycleUndoSpace函数 |
| RecycleUndoSpace |
按照前述条件回收undo空间,记录日志 |
2) MVCC
ustore的可见性检查和astore类似,将快照CSN和元组删除和插入事务的CSN进行比较,判断元组是否可见。ustore和astore使用同一套事务管理机制和快照管理机制。
ustore和astore最大的区别在于astore会在页面上保留旧版本数据,而ustore在将旧版本数据放到回滚段统一存放。在需要获取旧版本数据时,astore可以直接从tuple的头部读取到元组的插入和删除的事务号(XID),来判断元组的可见性。但是ustore需要从回滚段里读取旧版本的事务信息,来判断旧版本是否可见。由于从回滚段中读取旧版本数据存在相对昂贵的开销,ustore通过一系列的优化手段来避免从回滚段中读取旧版本数据。
ustore在获取元组时,会先检查对应的事务目录。事务目录分成有效和无效两种。当事务目录是有效的,ustore直接就会得到元组上最新的事务。
如果事务目录被冻结(FROZEN),意味着元组已经在所有的事务中都会可见。如果事务目录中的事务id小于oldestXidInUndo,意味着元组已经足够旧在所有事务中都可见。同时会把事务目录置成冻结,来加速后续的查询。
如果元组被标记有一个无效事务目录,意味着修改元组的事务已经提交,并且比当前的事务目录中的事务旧。此时ustore会使用事务目录中的事务进行可见性判断。如果可见,意味着修改元组的事务更已经可见,就不需要从undo目录中再读取事务信息。
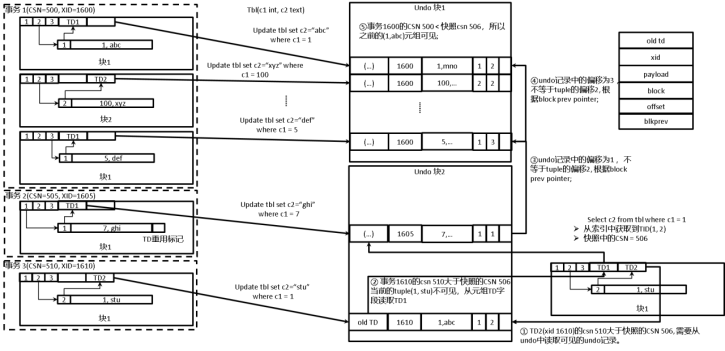
元组查询过程
元组不可见的场景,ustore会从undo目录中读取回滚记录中的旧版本数据查找元组。例子如上图所示。查找tbl表中c1=1的数据项,从索引中读取到数据项位于block 1和offset 2,使用UHeapTupleFetch函数再从block 1中查询到元组,需要判断该元组的可见性。
(1) 从元组的TD读到ITL2,和astore类似,根据CSN的大小,判断TD2中的XID不可见,需要使用GetTupleFromUndo函数读取回滚记录。
(2) GetTupleFromUndo函数调用GetTupleFromUndoRecord函数读取回滚记录,使用InplaceSatisfyUndoRecord函数判断其中的block 1和offset 2是满足要求的元组。但是XID=1610可以判断出当前页面的tuple不可见,ustore继续查询更老的版本。由于旧元组的TD 1和当前的TD 2不一致,使用UHeapUpdateTDInfo从TD 2 undo链条进行切换,根据旧元组的TD 1找到当前的undo指针找到前一次修改。
(3) 再次读取到回滚记录,其中的block 1和offset 1并非要找的元组,ustore继续查询更老的版本,根据blkprev指针读取前一次修改。
(4) 读取到回滚记录,其中的block 1和offset 3并非要找的元组,ustore继续查询更老的版本,根据blkprev指针读取前一次修改。
(5) 读取到回滚记录,其中的block 1和offset 2是要求的元组,ustore判断可见性。根据CSN的大小,事务可见。因此前一次命中的元组可见,即(1, abc)可见,因此查找到元组的c2等于abc。
4. 多版本索引
在openGauss中实现了多版本索引ubtree,是专用于ustore的B-Tree索引变种,相比原有的B-Tree索引有如下差异点。
(1) 支持索引数据的多版本管理及可见性检查,能够自主鉴别旧版本元组并进行回收,同时索引层的可见性检查使得索引扫描(Index Scan)及仅索引扫描(Index Only Scan)性能有所提升。
(2) 在索引插入操作之外,增加了索引删除操作,用于对被删除或修改的元组对应的索引元组进行标记。
(3) 索引按照key + TID的顺序排列,索引列相同的元组按照对应元组的TID作为第二关键字进行排序。
(4) 添加新的可选页面分裂策略“insertpt”。
ubtree实现了索引访问接口所要求的全部接口,如表所示:
表 ubtree访问接口函数
| 接口名称 |
对应函数 |
接口含义 |
| aminsert |
ubtinsert |
插入一个索引元组 |
| ambeginscan |
ubtbeginscan |
开始一次索引扫描 |
| amgettuple |
ubtgettuple |
获取一个索引元组 |
| amgetbitmap |
ubtgetbitmap |
通过索引扫描获取所有元组 |
| amrescan |
ubtrescan |
重新开始一次索引扫描 |
| amendscan |
ubtendscan |
结束索引扫描 |
| ammarkpos |
ubtmarkpos |
标记一个扫描位置 |
| amrestpos |
ubtrestpos |
恢复到一个扫描位置 |
| ammerge |
ubtmerge |
合并多个索引 |
| ambuild |
ubtbuild |
建立一个索引 |
| ambuildempty |
ubtbuildempty |
建立一个空索引 |
| ambulkdelete |
ubtbulkdelete |
批量删除索引元组 |
| amvacuumcleanup |
ubtvacuumcleanup |
索引后置清理 |
| amcanreturn |
ubtcanreturn |
是否支持 Index Only Scan |
| amcostestimate |
ubtcostestimate |
索引扫描代价估计 |
| amoptions |
ubtoptions |
索引选项 |
此外,还实现了新增的的索引删除函数UBTreeDelete。
1) 索引页面组织
多版本索引层次结构与B-Tree索引基本相同,非叶子节点与B-Tree索引保持一致,仅页尾的Special字段有所不同。ubtree中的Special字段UBTPageOpaqueDataInternal如下所示:
typedef struct UBTPageOpaqueDataInternal {
……
/* 以上部分与BTPageOpaqueDataInternal一致 */
TransactionId last_delete_xid; /* 记录页面上最后一次删除事务的 XID */
TransactionId xid_base; /* 页面上的 xid-base */
int16 activeTupleCount; /* 页面上活跃元组计数 */
} UBTPageOpaqueDataInternal;
typedef UBTPageOpaqueDataInternal* UBTPageOpaqueInternal;
其中last_delete_xid与activeTupleCount用于索引的自治式回收,会在ustore中的“6. 空间管理和回收”一节详细讲解。
通过xid_base字段,页面上的XID可以仅储存基于该xid_base的一个32位偏移(Offset),节省XID存储的空间开销。实际的XID为页面上的xid_base加上存储的XID(也就是偏移)得到。
多版本中的叶子页面的结构如图所示。
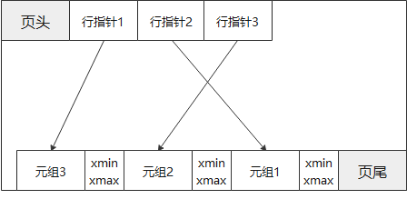
ubtree 叶子页面结构示意图
与astore堆页面中维护版本信息的方法类似,ubtree的叶子节点中每个索引元组尾部都附加了对应的xmin和xmax。由于索引只是用于加速搜索的结构,本身不与历史版本概念强相关,仅通过xmin和xmax来标识这个索引元组是从什么时候开始有效的,又是什么时候被删除的,而不像astore中堆元组一样会有指向旧版本元组的指针。
新插入的索引元组尾部用于存放xmin和xmax 空间在ubtinsert函数执行的过程中预留出来。预留的空间及xmin在索引元组插入时通过UBTreePageAddTuple函数中写入页面,而xmax在索引元组删除时通过UBTreeDeleteOnPage函数中写入页面。
在UBTreePagePruneOpt函数中,索引元组通过其xmin和xmax信息来判断该元组是否已经无效(Dead),进而进行独立的页面清理。该函数会尝试清除所有无效的元组,并进行相应的碎片整理。
索引扫描时会调用UBTreeFirst函数定位到第一个满足扫描条件的索引元组,然后调用UBTreeReadPage获取当前页面中符合索引扫描条件,且能够通过可见性检查的元组。可见性检查通过UBTreeVisibilityCheckXid函数及UBTreeVisibilityCheckCid函数处理,其基本逻辑与astore类似,通过xmin与xmax及当前的快照进行可见性判断。
在ubtree中,索引元组除了按照索引列有序排列之外,对于索引列相同的元组,还将其对应堆元组的TID作为第二关键字进行排序。其具体实现大致都集中在ubtbuild函数及ubtinsert函数调用的过程中,这中间对索引列相同的元组会按照TID来进行额外的比较。实现还借助了BTScanInsert结构体,该结构体定义如下:
typedef struct BTScanInsertData {
bool heapkeyspace; /* 标志索引是否额外按 TID 排序 */
bool anynullkeys; /* 标志待查找的索引元组是否有为 NULL的列 */
bool nextkey; /* 标志是否希望寻找第一个大于扫描条件的元组 */
bool pivotsearch; /* 标志是否希望查找 Pivot 元组 */
ItemPointer scantid; /* 用于作为排序依据的 TID */
int keysz; /* scankeys 数组的大小 */
ScanKeyData scankeys[INDEX_MAX_KEYS];
} BTScanInsertData;
在索引元组将TID作为第二关键字排序之后,用于划分搜索空间的非叶子节点元组及叶子节点的Hikey元组(统称Pivot元组)也需要携带对应的TID信息。这会使得Pivot元组占用空间增加,非叶子的扇出(fan out)降低。为了避免这一特性导致的扇出降低,若不需要比较TID即可区分两个叶子页面,则对应的Pivot原则中就不需要储存TID信息。类似地,Pivot元组中也可以去掉一些不需要进行比较的索引列,这一逻辑在UBTreeTruncate函数中进行处理。原则是当比较前几列就可以区分两个叶子页面时,Pivot元组中就不需要储存后续的列。
2) 索引操作
对于原有的B-Tree索引而言,主要有四类操作:索引创建、索引扫描、索引插入以及索引删除。下面将依次进行介绍。
(1) 索引创建。
索引创建操作由索引上的ubtbuild函数及ustore上的IndexBuildUHeapScan函数配合完成。IndexBuildUHeapScan函数负责扫描对应的ustore表,并取出每个元组的最新版本(遵循SnapshotNow的语义)以及其对应的xmin和xmax。若发现某个元组存在被就地更新的旧版本,则会将该索引标记为HotChainBroken。被标记为HotChainBroken的索引,会复用astore原有的逻辑,禁止隔离级别为可重复读(Read Repeatable)的老事务访问。ubtbuild函数会接收IndexBuildUHeapScan传过来的元组,将其按照索引列及TID排序后依次插入到索引页面中,并构建相应的元页面及上层页面。整个创建流程需要将所有页面都记录到XLOG中,并强制将存储管理中的内容刷到永久存储介质后才算成功结束。
(2) 索引扫描。
索引扫描与B-Tree索引基本一致,但是需要对索引元组进行可见性检查。没有通过可见性检查的索引元组不会被返回,通过可见性检查的元组仍需要在ustor 堆表上进行可见性检查,并找到正确的可见版本。在IndexOnlyScan场景中,通过可见性检查的元组即可直接返回,不需要再访问堆表。
不过索引进行可见性检查时,由于索引元组只存放了xmin和xmax而没有CID(对应“4.2.3 astore”节堆表元组中的t_cid字段)信息,如果发现了当前事务修改过的索引元组则不能正确地通过CID来判断其可见性。此时会将该元组视为可见,但会标记xs_recheck_itup,告知ustore的数据页面需要在取到对应的数据元组后,再次构建对应的索引元组并与返回的索引元组进行比较,来确认该索引元组是不是真正可见。相关逻辑在 UBTreeVisibilityCheckXid、UBTreeVisibilityCheckCid以及RecheckIndexTuple函数中进行处理。
(3) 索引插入。
索引元组需要存储对应的xmin和xmax版本信息,但其所占用的空间并不表现在IndexTupleSize中,而是对外部透明。索引插入的接口函数为ubtinsert,为了正确插入带有版本信息的元组,需要在执行插入前增加IndexTupleSize以预留用于储存版本信息的空间。真正将元组插入到页面的时候,会将版本信息所占用的空间大小从IndexTupleSize中去除。
在索引插入的过程中若页面空间不足,会首先调用UBTreePagePruneOpt函数尝试对已经无效的元组进行清理。若清理失败或清理成功后空间仍然不足,会进行索引页面分裂。索引页面分裂会在UBTreeInsertOnPage函数中进行。ubtree中存在两种分裂策略:default以及insertpt。其中default策略会将原页面上的内容均匀地分配到两个页面上,而insertpt会根据新插入元组的插入规律、插入位置及TID等信息选择合适的分裂点。
在ubtree需要申请新的页面时,并不会像原有的B-Tree索引一样调用_bt_getbuf通过FSM来查找可用页面。ubtree带有自治式的空间管理机制,通过UBtreeGetNewPage函数获取新页面。该自治式空间管理机制将在空间管理和回收部分介绍。
(4) 索引删除。
索引删除操作用于在堆元组被删除的同时,将对应的索引元组也标上对应的xmax。索引删除的流程与插入类似,通过二分查找定位到待删除元组的位置,并将xmax写入到对应的位置。需要注意的是,要删除的元组是索引列以及TID都匹配,且还未被写入xmax的那个元组,这部分逻辑在UBTreeFindDeleteLoc函数中处理。在最后会调用UBTreeDeleteOnPage函数为对应的索引元组写上xmax,更新页面上的last_delete_xid以及activeTupleCount,并在检测到activeTupleCount为0时将该页面放入潜在空页队列(Potential Empty Page Queue)中。关于潜在空页队列会在空间管理和回收部分介绍。
5. 存取管理
openGauss中的ustore表访存接口如表4-24所示。由于openGauss中ustore表只有一种页面和元组结构,因此在上述接口中,直接实现了底层的页面和元组操作流程。
表 ustore表访存接口
| 函数名称 |
接口含义 |
| heap_open |
打开一个ustore表,得到表的相关元信息 |
| heap_close |
关闭一个ustore表,释放该表的加锁或引用 |
| UHeapRescan |
重新开始ustore表(顺序)扫描操作 |
| UHeapGetNext |
(顺序)获取下一条元组 |
| UHeapGetTupleFromPage |
UHeapGetNext内部实现,单页校验模式 |
| UHeapScanGetTuple |
UHeapGetNext内部实现,单条校验模式 |
| UHeapGetPage |
(顺序)获取并扫描下一个ustore表页面 |
| UHeapInsert |
在ustore表中插入一条元组 |
| UHeapMultiInsert |
在ustore表中批量插入多条元组 |
| UHeapDelete |
在ustore表中删除一条元组 |
| UHeapUpdate |
在ustore表中更新一条元组 |
| UHeapLockTuple |
在ustore表中对一条元组加锁 |
6. 空间管理和回收
不同于astore的空间管理和回收机制,ustore实现了自治式的空间管理机制。ustore里堆以及索引的空间分配和回收都在业务运行的过程中平稳地进行,不依赖中量级的VACUUM及AUTOVACUUM清理机制。
1) 自治式堆页面空间管理
ustore中堆页面的自治式空间管理,建立在与astore类似的轻量级堆页面清理机制的基础上。在执行DML及DQL操作的过程中,ustore都会进行堆数据页面清理,以取代VACUUM清理机制。UHeapPagePruneOptPage函数是页面清理的入口函数,会清理已经提交的被删除元组。
对于astore而言,复用数据元组的行指针前必须保证对应的索引元组已经被清理。这是为了防止通过索引元组访问已经被复用的行指针,导致取到错误的数据。在astore中需要通过VACUUM操作将这样的无效索引元组统一清除掉后才能复用行指针,这使得堆页面和索引页面的清理逻辑耦合在一起,也会导致间断性的大量I/O。在ustore中能高效地单独进行数据和索引页面的清理,因为带有版本信息的ubtree能够独立检测并过滤掉无效的索引元组,不会通过无效索引元组访问对应的数据表。
堆页面的空间管理机制复用openGauss中的FSM来管理UHeap中的可用空间。在UHeapPagePruneOptPage函数成功对页面进行清理后,会将其空闲空间刷新到对应的FSM页面中。为了避免每次页面清理都需要更新整个树状结构的FSM,从而带来额外的开销,引入了一个更新整个FSM的概率计算。考虑当前清理后的可用空间占预留可用空间(Reserved Free Space)阈值的百分比,计算得出清理一个页面后调用FreeSpaceMapVacuum函数的概率。也就是说,页面清理获得的可用空间越大,更新整个FSM的概率也就越大。
当数据元组被删除时,会在页面上记录对应的潜在空闲空间(Potential Free Space),该值用于估计页面上的空闲空间。在运行过程中,有多个场景会调用UHeapPagePruneOpt对页面尝试进行清理。DML语句执行过程中,INSERT、UPDATE以及DELETE操作都会拿到页面的写锁。如果发现空间不足,或者检测到潜在空闲空间到达某个阈值,会尝试对页面进行清理。DQL查询语句执行的过程中若检测到页面上潜在空闲空间到达阈值,也同样会尝试申请页面的写锁;如果拿到了页面的写锁,会尝试对页面进行清理。
存在可清理的元组,但一直不被访问的页面不能通过这一机制正确地清理。为了解决这一问题,引入了基于概率的清理方案。在RelationGetBufferForUTuple函数寻找新的可用空间时,若通过FSM发现没有足够的可用空间,在对物理文件进行扩展前,会“随机”选取一些页面进行清理。该机制并非完全随机选取,在多次尝试后选取的页面会覆盖到整个关系的全部页面。为了性能考虑,该过程中默认最多选取10个页面进行清理,该数量可以通过GUC参数max_search_length_for_prune进行设置。具体的页面选取数量通过DeadTupleRatio以及PruneSuccessRatio计算得出。其中DeadTupleRatio表示该表中无效元组的大致比例,该变量以统计信息的方式进行收集,在进行DML的过程中会进行更新;PruneSuccessRatio大致表示近几次尝试清理的成功率。
2) 自治式索引页面空间管理
索引页面的空间管理不依靠FSM数据结构,而是依靠特有的URQ(UBtree Recycle Queue)结构,简称为回收队列。索引回收队列单独储存在ubtree索引对应的.urq文件中,没有原有B-Tree索引的.fsm文件。索引回收队列相关代码在“ubtrecycle.cpp”文件中。涉及到的主要函数接口见表。
表 索引回收队列主要接口
| 函数名称 |
接口含义 |
| UBTreeTryRecycleEmptyPage |
尝试从潜在空页队列回收一个页面 |
| UBTreeGetAvailablePage |
获取有效页面(潜在空页或空闲页面) |
| UBTreeRecordUsedPage |
记录被成功使用的页面 |
| UBTreeRecordEmptyPage |
记录潜在的空页 |
| UBTreeGetNewPage |
获取新的可用页面 |
索引中的回收队列分为两部分,一部分是潜在空页队列(Potential Empty Page Queue),一部分是可用页面队列(Available Page Queue)。两个队列都是跨页面的循环队列,其中每个元素都会储存blkno以及XID。其中blkno表示该元素对应索引页面的block number;XID表示该页面在哪个时刻能够被回收或复用。这些元素在循环队列单个页内按照XID的顺序进行排序,以便于快速找到XID 小(最可能被回收或复用)的页面。其结构如图所示。
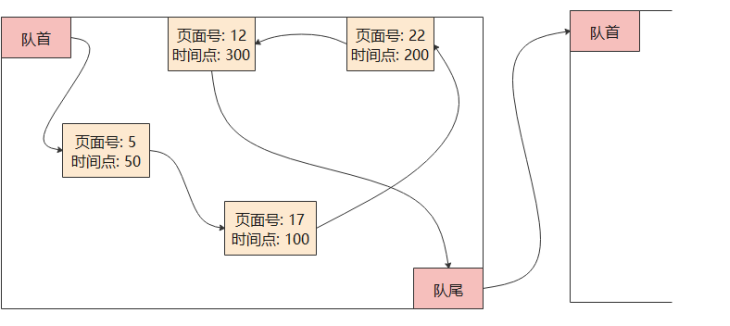
ubtree回收队列结构示意图
对于潜在空页队列而言,里面存放页内元组已经被全部删除但还没有全部无效的页面,其中的XID就标志页面中最后一个元组无效的可能时机。在系统整体的oldestXmin超过该XID后,该页面就有可能被从索引上删除,但也可能因为新插入元组或删除元组的事务中止而导致页面不能被删除。潜在空页队列中的页面在成功被删除后会被放入可用页面队列,并记录删除时最新事务的XID。
对于可用页面队列而言,里面存放已经被删除,可以或即将可以被复用的页面。其中XID就表示该页面可以被复用的时机。这样的页面复用时延是来自B-Tree索引页面删除时可能的并发访问导致的,可以参考nbtree文件夹下README 关于页面删除的部分。
在ubtree进行索引删除时,会更新页面上的last_delete_xid字段以及activeTupleCount字段。若更新后activeTupleCount变为0,会将该页面放入潜在空页队列,并将此时的last_delete_xid作为对应的可回收时间点。
在业务运行的过程中,索引会通过UBTreeTryRecycleEmptyPage函数不断尝试对潜在空页队列中的页面进行回收。在索引申请新的页面时,会通过UBTreeGetNewPage函数与可用页面队列交互,查找当前可用的空闲页面。当可用页面队列中没有可用页面时,一般会通过扩展索引物理文件的方式来获得新的页面。但也存在物理文件批量扩展,或扩展后还未来得及使用就出错退出的情况。此时在回收队列的元信息页面中保存了已正确追踪的页面数量,若该数量少于整个索引表的页面数量,会尝试去使用这一部分未追踪的页面,并更新已追踪的页面数量。
3) 中量级和重量级手动页面清理
与astore相同,ustore也提供VACUUM语句来让用户主动执行对某个ustore表及其上的索引进行中量级清理。其对外表现与astore一致,可参考astore的空间管理和回收内容。
在ustore中,中量级清理同样通过lazy_vacuum_rel函数进入,但不会调用lazy_scan_heap,而是调用LazyScanUHeap函数来进行数据页面的清理。在进行索引清理时,会调用lazy_vacuum_index接口及LazyVacuumHeap函数来清理索引文件和堆表文件,索引清理时会调用ubtbulkdelete函数。
重量级的VACUUM FULL也与astore一致,会清理无效数据并对数据空间和索引空间重新进行组织。重量级清理的对外接口是cluster_rel函数,本质上是重新对数据进行聚簇,清理过程中会阻塞对该表的所有操作。

- 点赞
- 收藏
- 关注作者
评论(0)