你的数据库真的穿“防弹衣”了吗

@TOC
✨博主介绍
🌊 作者主页:苏州程序大白
🌊 作者简介:🏆CSDN人工智能域优质创作者🥇,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
💬如果文章对你有帮助,欢迎关注、点赞、收藏
💅 有任何问题欢迎私信,看到会及时回复
💅关注苏州程序大白,分享粉丝福利
前言
华强来到一家程序员商店买缓存,问程序员:“你这缓存保熟吗?” …

缓存经常被用来减少数据库访问量,以此来提高系统性能,承受更多的并发请求,就像“防弹衣”一样保护着数据库,防止被一颗颗“请求子弹”击中。
但引入缓存,也带来了一些新的问题,比如缓存击穿、缓存穿透、缓存雪崩、缓存数据一致性等问题。今天来聊聊缓存击穿,百度一搜有很多相关的文章,但按照网上的一些教程去解决缓存击穿,真的可以保证这一“防弹衣”不被击穿吗?
看一段示例代码
public ResponseDTO getRoleById(Long id) throws Exception {
String key = "User:Role:" + id;
List<Long> data = (List<Long>) redisUtil.get(key);
if (data == null) {
data = userMapper.selectRoleIdByUserId(id);
Long buffTime = (long) new Random().nextInt(30) * 60;
redisUtil.set(key, data, buffTime);
}
return new ResponseDTO(Status.SUCCESS.code, "", data);
}
这段代码使用redis做了缓存,只要缓存中有数据就不会去查数据库,但如果缓存中没数据,这时又恰好又大量请求来袭,那这些请求就会去访问数据库,如果并发请求量很大,数据库就有可能被打死,这就是缓存击穿。
解决思路也很简单,只让一个请求去查数据库然后更新缓存,其他请求先等着,等查数据库的兄弟更新完缓存我再去查缓存。具体实现也很容易,加个锁不就好了。那一起来看看接下来这几段代码。
解决缓存击穿的方法
public ResponseDTO getRoleById(Long id) throws Exception {
String key = "User:Role:" + id;
List<Long> data = (List<Long>) redisUtil.get(key);
boolean isLock = false;
ReentrantLock lock = new ReentrantLock();
try {
if (data == null) {
if (lock.tryLock()) {
isLock = true;
data = userMapper.selectRoleIdByUserId(id);
Long buffTime = (long) new Random().nextInt(30) * 60;
redisUtil.set(key, data, buffTime);
} else {
Thread.sleep(100); // 此处仅为例子,具体由实际查询情况定,也可以循环查询几次
data = (List<Long>) redisUtil.get(key);
}
}
}
finally {
if (isLock)
lock.unlock();
}
return new ResponseDTO(Status.SUCCESS.code, "", data);
}
这个解决方案完全是一种错误的方案,因为这里的锁,锁了个寂寞。
锁是为了解决多线程问题的,即多个线程争用一把锁,谁抢到了谁用,但在SpringMVC中,一个请求就会建立一个线程,把锁定义在方法中(ReentrantLock lock = … 那行代码),那不就是一个线程一把锁,我和自己抢,然后我锁我自己吗,锁了个寂寞。所以这种方法无法防止缓存击穿。
方法二
把锁拿到外面定义并实例化,这样就能做到所有线程用一把锁。
static ReentrantLock lock = new ReentrantLock();
@Override
public ResponseDTO getRoleById(Long id) throws Exception {
String key = "User:Role:" + id;
List<Long> data = (List<Long>) redisUtil.get(key);
boolean isLock = false;
try {
if (data == null) {
if (lock.tryLock()) {
isLock = true;
data = userMapper.selectRoleIdByUserId(id);
Long buffTime = (long) new Random().nextInt(30) * 60;
// Thread.sleep(90); // 模拟用
redisUtil.set(key, data, buffTime);
} else {
Thread.sleep(100); // 此处仅为例子,具体由实际查询情况定,也可以循环查询几次
data = (List<Long>) redisUtil.get(key);
}
}
}
finally {
if (isLock)
lock.unlock();
}
return new ResponseDTO(Status.SUCCESS.code, "", data);
}
这样看着可行,但又有了新问题,如果有两个并发请求,请求A和请求B,A和B请求参数不同,即想要得到的数据也不同,并且此时缓存中也没有A、B想要的数据,于是去查数据库,假设此时A拿到了锁,正在查数据库,刚好B这时到达,因为A拿到了锁还没有释放,导致B加锁失败,于是B睡眠然后等着查缓存。这时候A查完了数据,也更完了缓存,返回了正确的数据,过了一会,B睡醒了,但缓存中依然没有B想要的数据,于是返回了null。
下面来复现一下这种情况,为了模拟这种并发情况,我们在查数据库时也Thread.sleep()一下,模拟锁还没释放,又有其他非同参的请求到达。
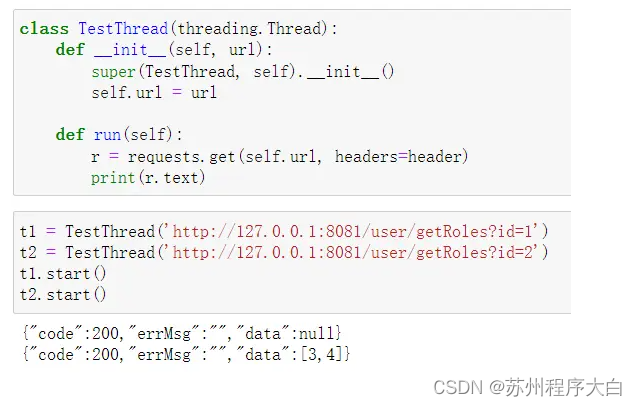
那使用ReentrantLock是不是无法解决缓存击穿呢,倒也不是,可以维护一个ConcurrentHashMap,以方法名和请求参数为key,如果key存在数据且无法用已经存在的锁成功加锁,说明已经有其他相同请求线程在读数据库,然后就可以睡眠,稍后去读缓存,如果没有数据,则新建一把锁,加锁后读数据库、刷缓存。
方法三
用synchronized关键字加锁。
public ResponseDTO getRoleById(Long id) throws Exception {
String key = "User:Role:" + id;
List<Long> data = (List<Long>) redisUtil.get(key);
if(data == null) {
synchronized (this) {
data = (List<Long>) redisUtil.get(key);
if(data != null) {
return new ResponseDTO(Status.SUCCESS.code, "", data);
}
data = userMapper.selectRoleIdByUserId(id);
Long buffTime = (long) new Random().nextInt(30) * 60;
redisUtil.set(key, data, buffTime);
}
}
return new ResponseDTO(Status.SUCCESS.code, "", data);
}
这种方法可以解决缓存击穿问题,但会影响系统性能。比如此时缓存中无数据,然后有1000个请求同时到来,然后这1000个线程开始争夺锁,一个加锁成功,去查了数据库,更新缓存,剩下999个在等待锁释放再抢锁,然后此时即使缓存有数据,这999个也是挨个加锁、读缓存,变成了一种串行执行,而不是并行读缓存。只有接下来到达的其他请求,才是并行去读取缓存。
方法四
使用分布式锁。(个人认为这才是最佳解决方案)
public ResponseDTO getRoleById(Long id) throws Exception {
String key = "User:Role:" + id;
List<Long> data = (List<Long>) redisUtil.get(key);
if(data == null) {
// 加锁,并设置过期时间为 30s,即超过30s自动解锁
if(redisUtil.setNx("getRoleById:" + id, 30L)) {
data = userMapper.selectRoleIdByUserId(id);
Long buffTime = (long) new Random().nextInt(30) * 60;
redisUtil.set(key, data, buffTime);
redisUtil.remove("getRoleById:"+id); // 解锁
} else {
// 轮询五次,每次间隔 100 ms 此处为例子,具体策略有具体情况定
int count = 0;
while(data == null && count < 5) {
Thread.sleep(100);
data = (List<Long>) redisUtil.get(key);
count++;
}
}
}
return new ResponseDTO(Status.SUCCESS.code, "", data);
}
这种类似于ReentrantLock + ConcurrentHashMap解决方案,不同类请求加不同锁,同类请求加锁失败就等待读缓存。既保证了缓存无数据时到达的请求可以并发访问更新后的缓存,又保证了不同参数的请求能读到正确数据。
如果是单机部署,可以使用synchronized或者ReentrantLock + ConcurrentHashMap解决,但用synchronized会导致部分请求串行,性能较低。
如果要分布式部署,使用单机锁也可以,毕竟部署几十台几百台,这点并发量数据库还是扛得住的,但显然使用分布式锁更合适。
如果目前是单机部署,但考虑到未来可能会分布式部署,用redis做了缓存,那就用分布式锁吧,毕竟欠下的技术债,总归是要还的。
💫点击直接资料领取💫


- 点赞
- 收藏
- 关注作者
评论(0)