【Dive into Deep Learning / 动手学深度学习】第三章 - 第二节:线性回归的从零开始实现


前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
知其然 知其所以然!
本文仅记录自己感兴趣的内容
3.2. 线性回归的从零开始实现
3.2.1. 生成数据集

%matplotlib inline
import random
import torch
from d2l import torch as d2l
- 1
- 2
- 3
- 4
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
# num_examples 数据集的个数
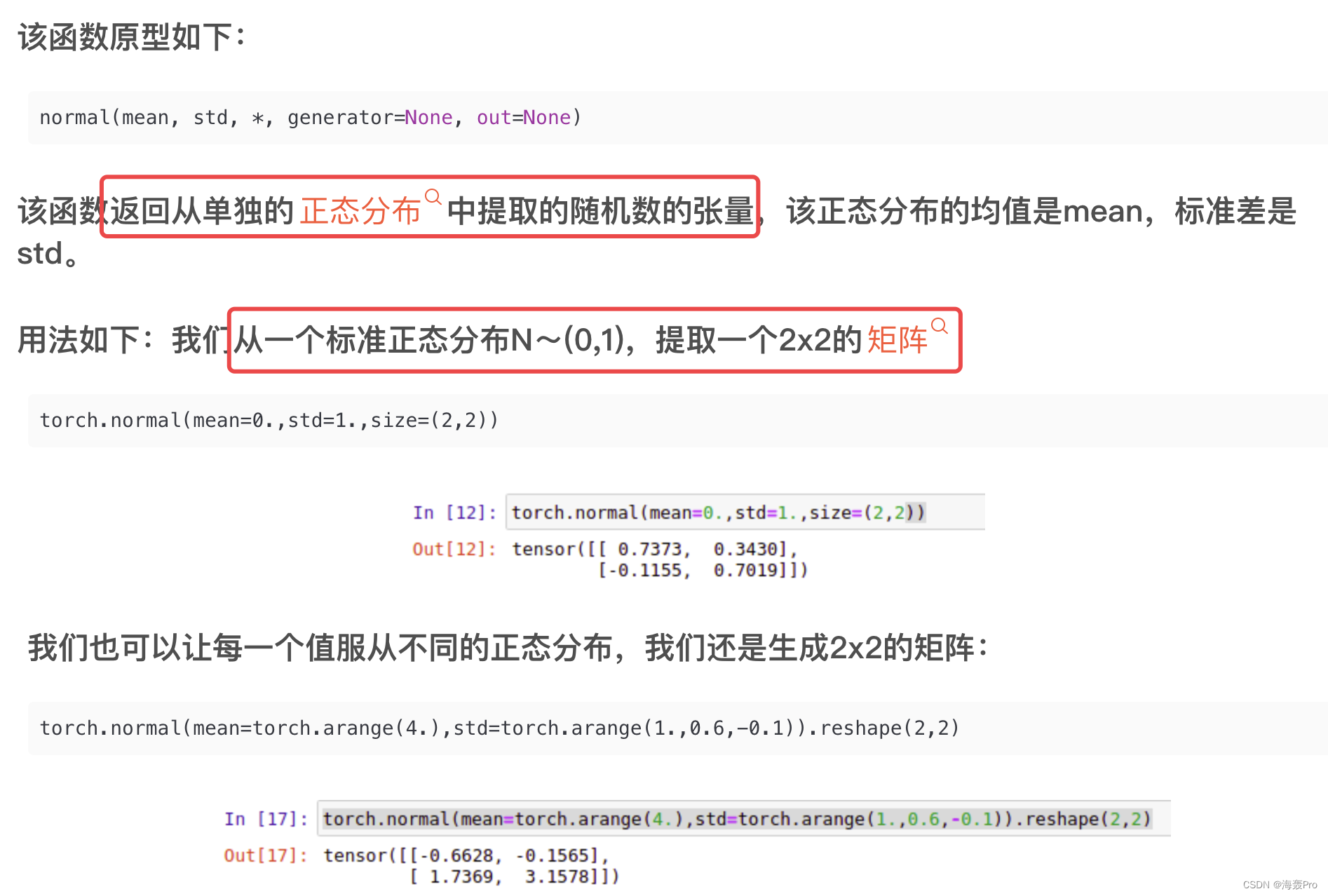
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
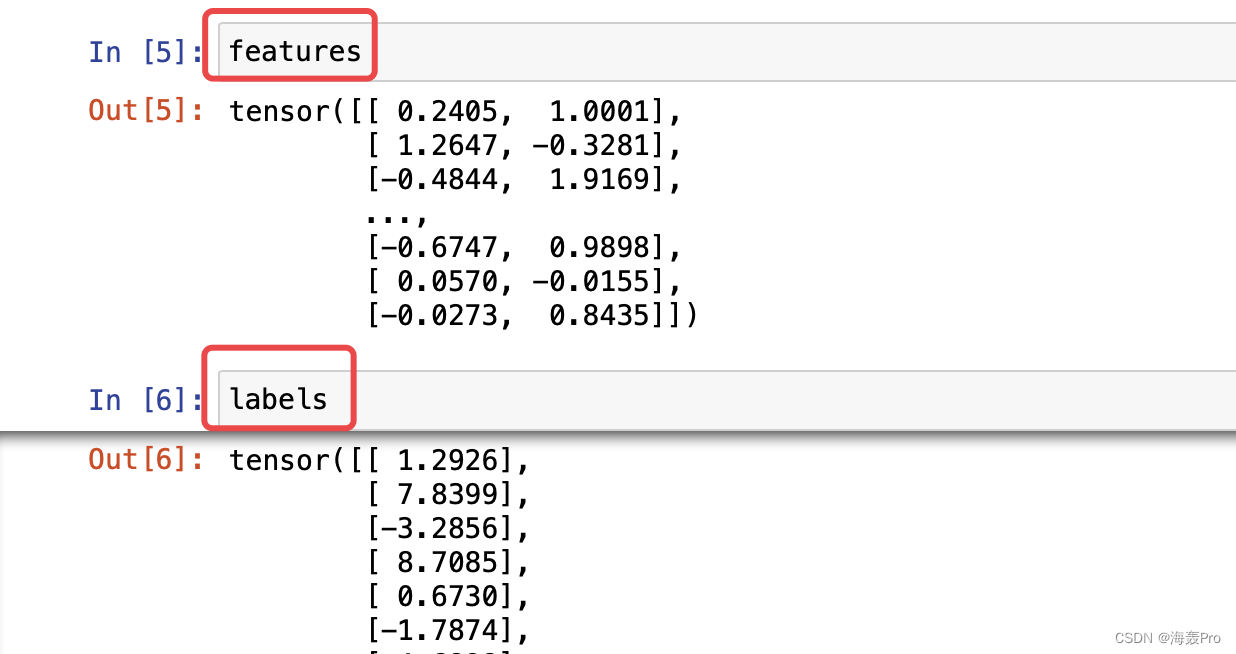
features, labels = synthetic_data(true_w, true_b, 1000)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
print('features:', features[0],'\nlabel:', labels[0])
- 1
d2l.set_figsize()
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1);
- 1
- 2
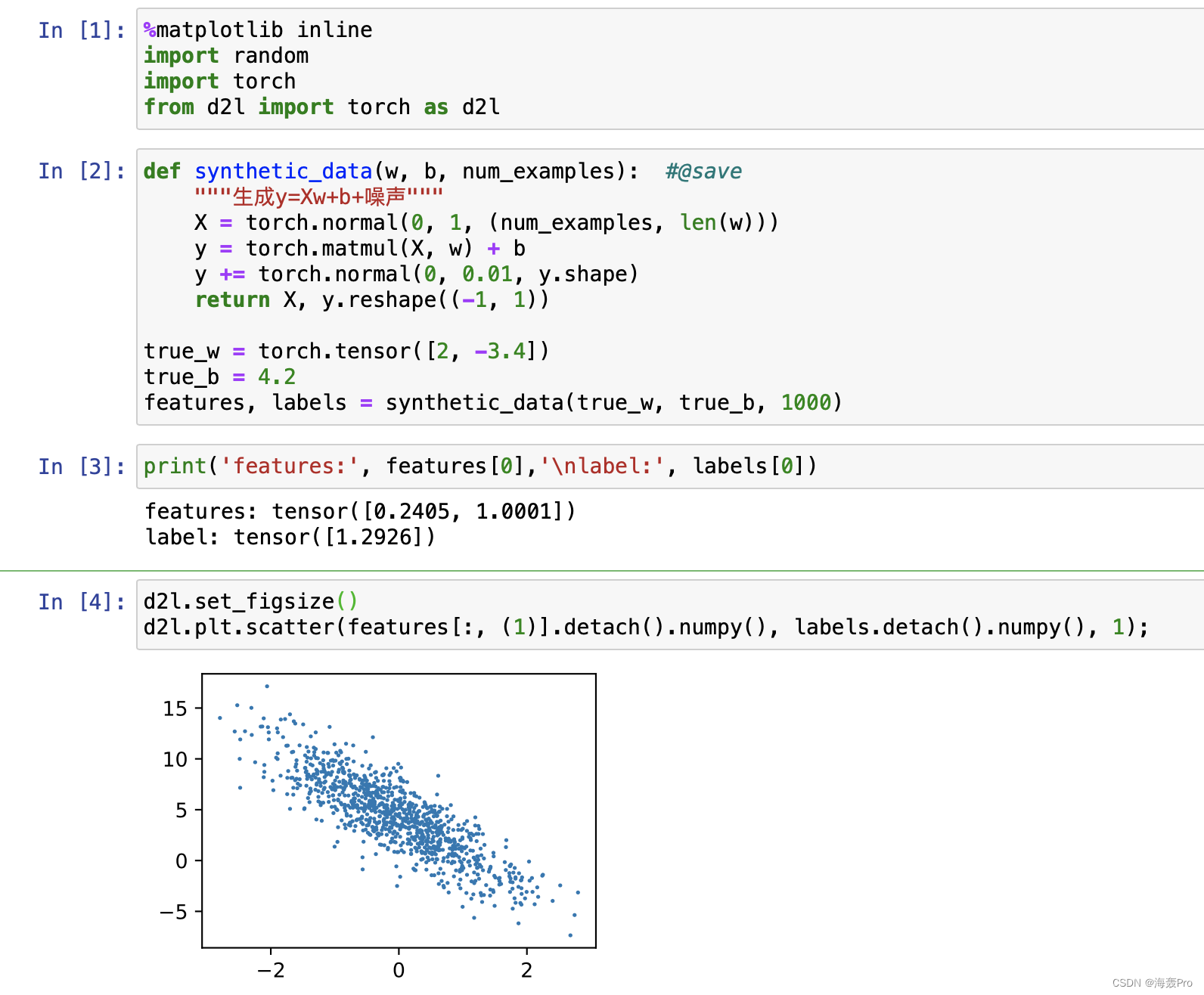
注意:这里横坐标其实只是 X X X中的第1列数据( x x x其实是有两列数据的,并没有用第0列),纵坐标为 Y Y Y
torch.normal()说明
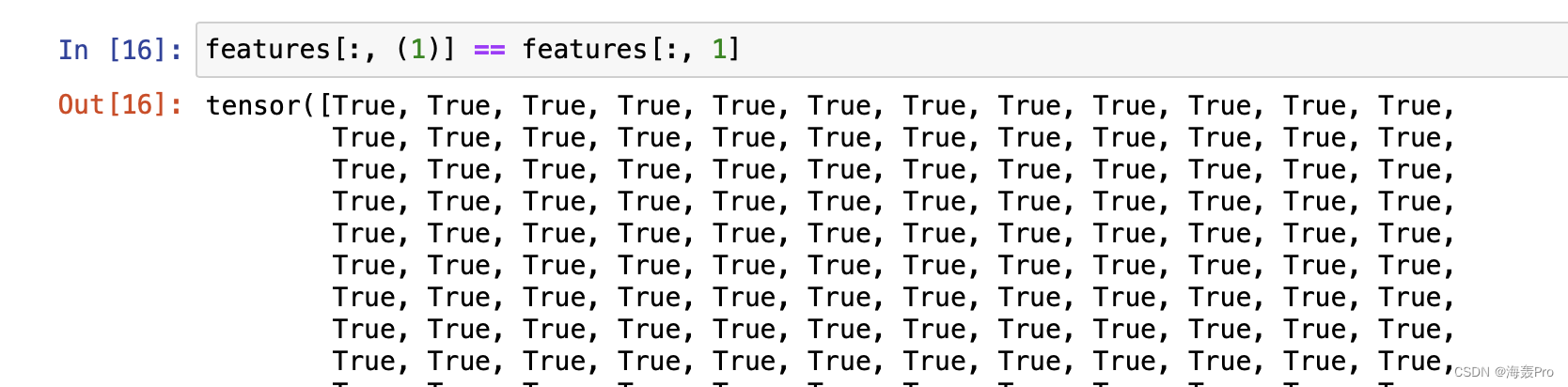
features[:, (1)] 这里表示选取features的全部行、第1列,等效于features[:, 1]
3.2.2. 读取数据集

def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples)) # 打乱索引
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
# 与return不同 yield这里可以理解为多次return(仅为个人理解)
yield features[batch_indices], labels[batch_indices]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
依据batch_size,随机从features、labels中抽取大小为batch_size的集合(利用一个被打乱的索引进行抽取)
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
- 1
- 2
- 3
- 4
得到多组大小为batch_size的数据

若只需要第一组数据,使用一个break
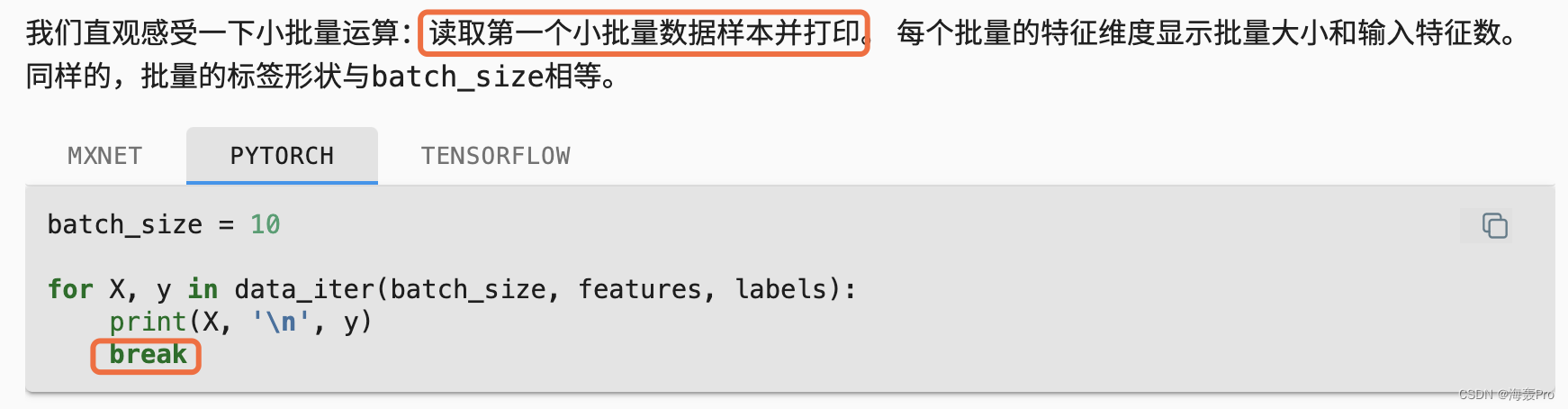
通过使用break和不使用break可以发现在函数data_iter中最后使用return和yield的区别(这里有一点点绕 需要自己理解一下)
举例:return和yield的区别
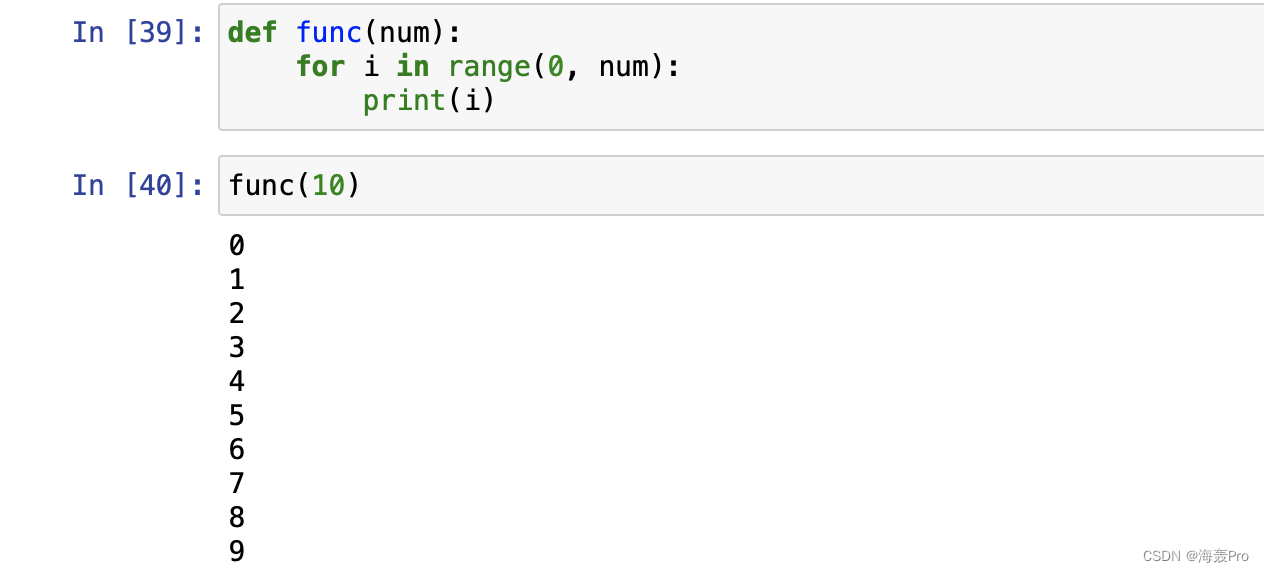
定义函数
def func(num):
for i in range(0, num):
print(i)
- 1
- 2
- 3
调用func(10),结果是打印0-9
如果函数func改为
def func(num):
for i in range(0, num):
print(i)
return
- 1
- 2
- 3
- 4
则结果是
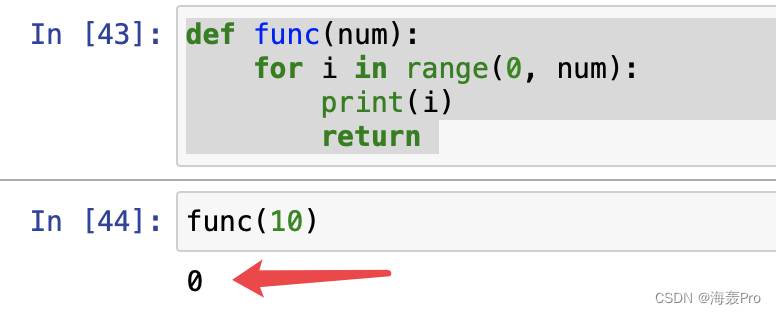
执行print(0)后遇到return就终止程序了
如果使用yield
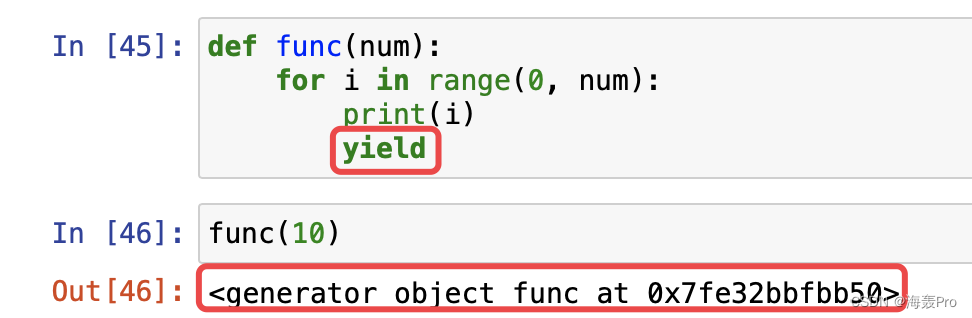
再打印出func(10)中的结果
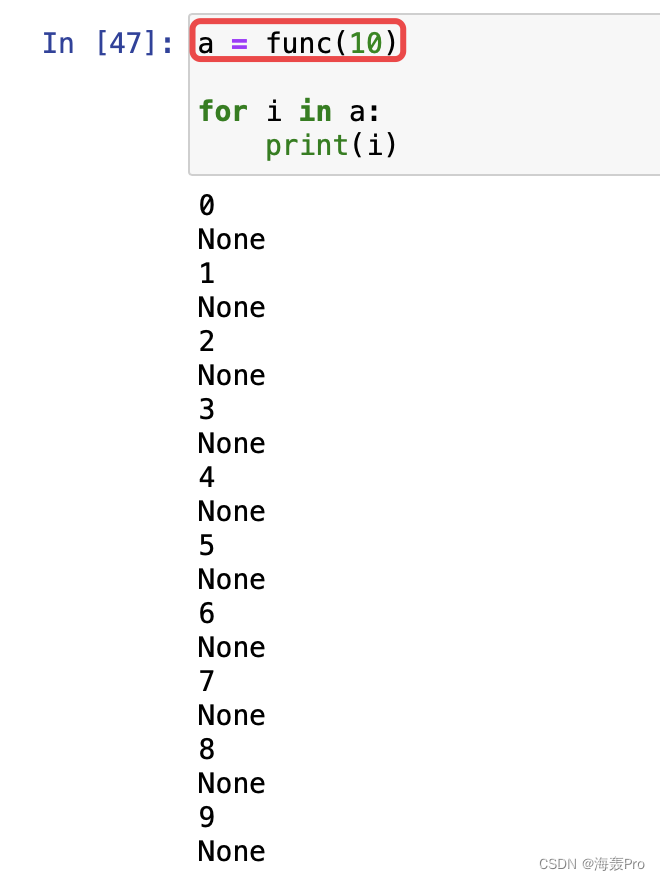
None 是yield后面返回的值
0-9是print打印出来的值
3.2.3. 初始化模型参数
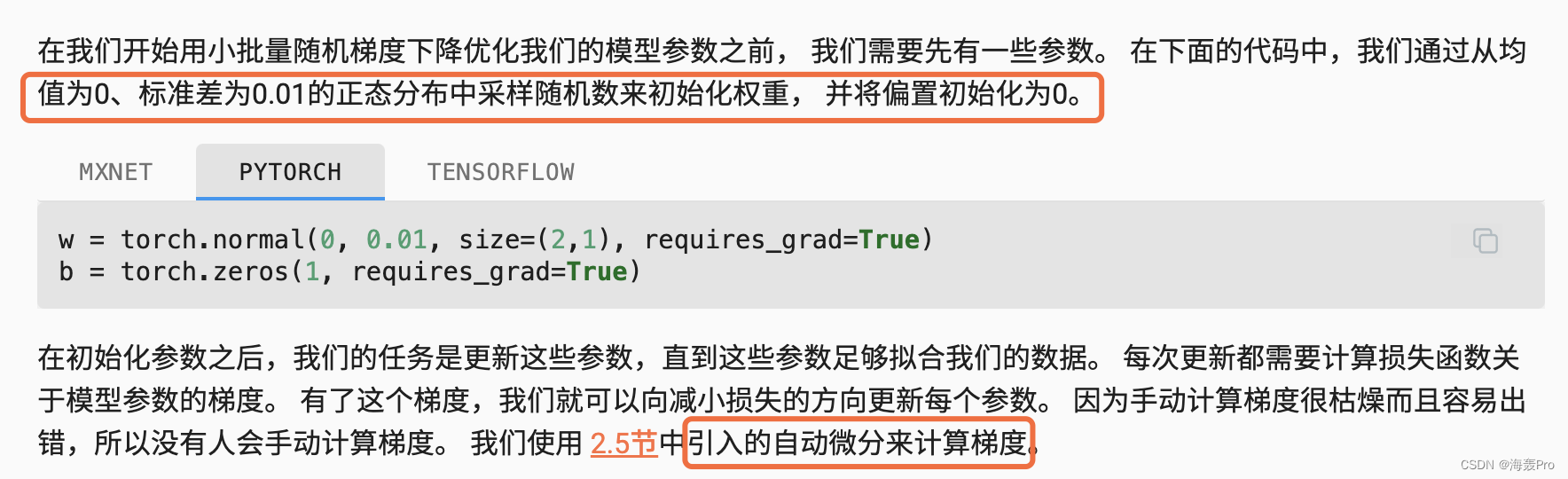
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
- 1
- 2
初始化参数w、b,设置requires_grad=True
3.2.4. 定义模型
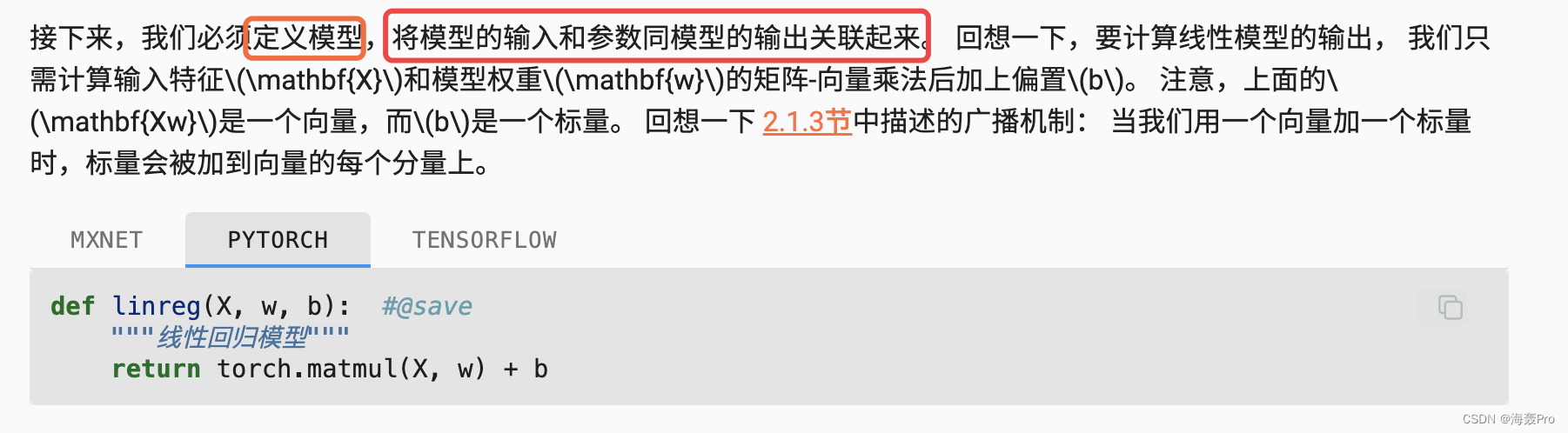
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b
- 1
- 2
- 3
3.2.5. 定义损失函数

def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
- 1
- 2
- 3
注:需要将真实值y的形状转换为和预测值y_hat的形状一样,便于计算(这里不注意有时容易错)
3.2.6. 定义优化算法
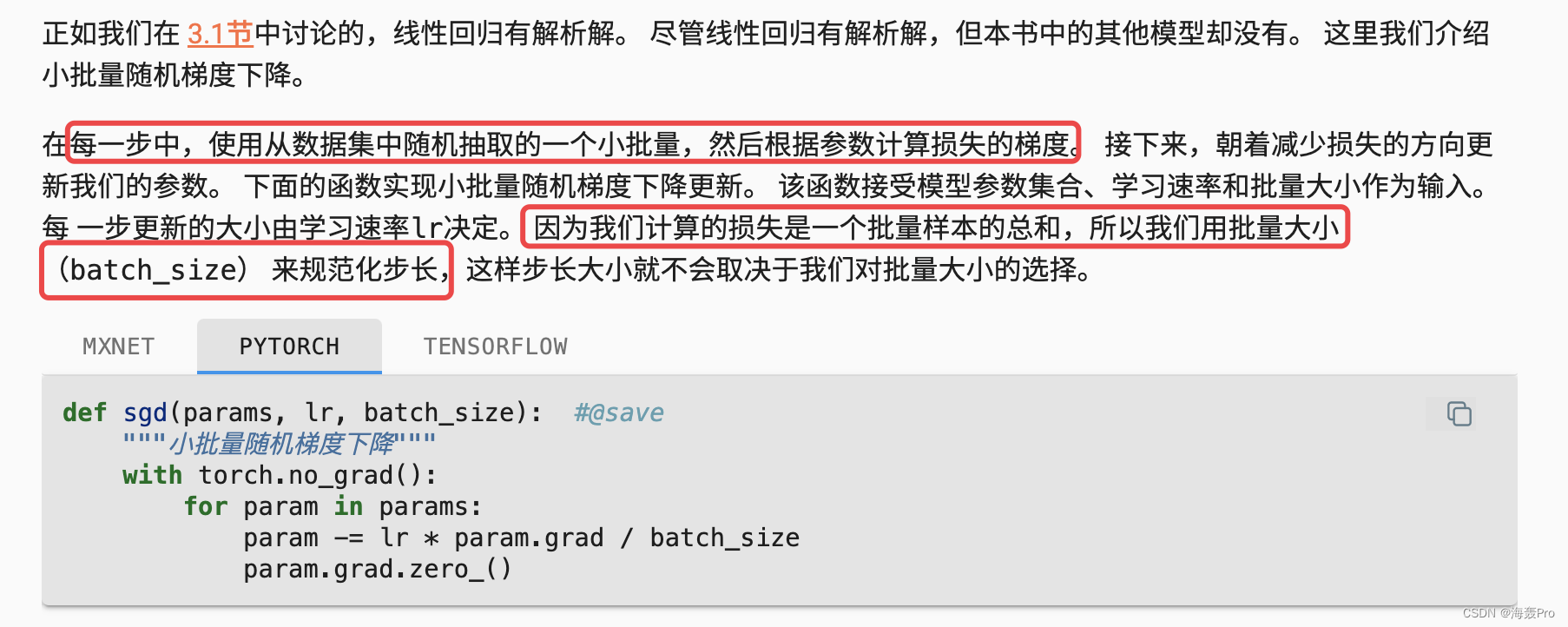
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
- 1
- 2
- 3
- 4
- 5
- 6
注:记住需要将得到的param.grad 除以 batch_size
3.2.7. 训练

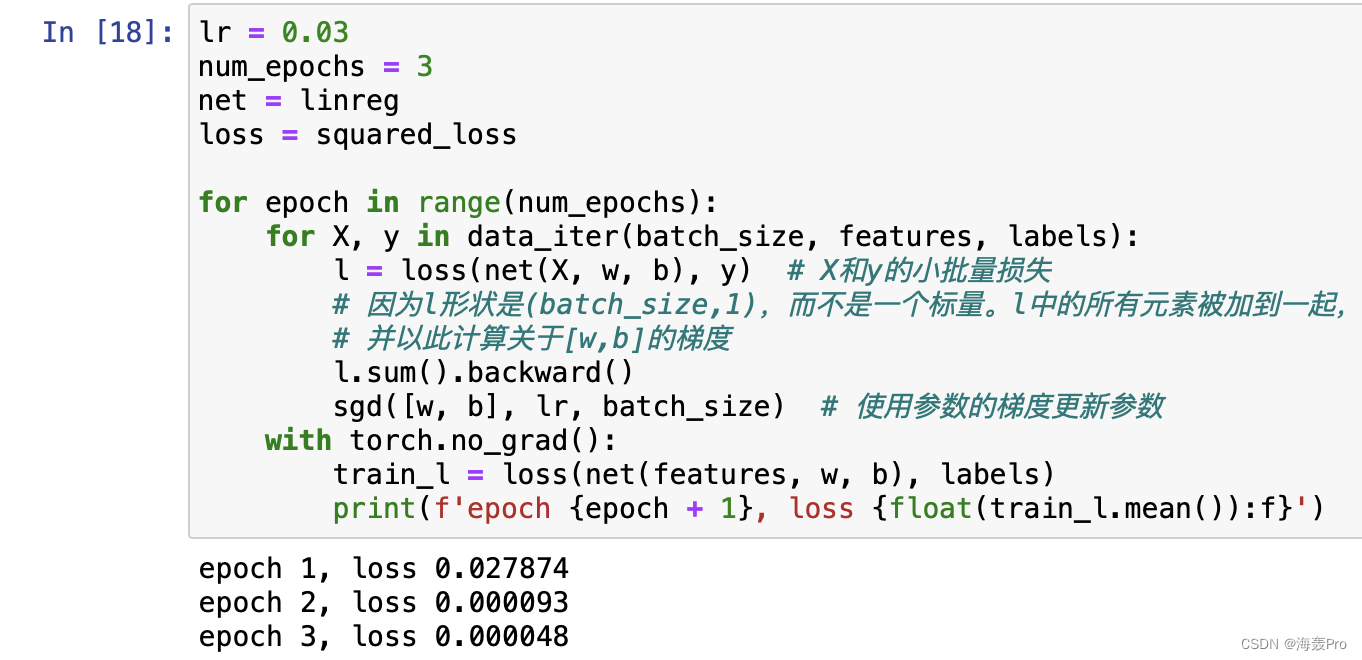
打印模型求解的参数
print(f'w = : {w}, b = {b}')
- 1

结语
学习资料:http://zh.d2l.ai/
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

文章来源: haihong.blog.csdn.net,作者:海轰Pro,版权归原作者所有,如需转载,请联系作者。
原文链接:haihong.blog.csdn.net/article/details/124529161

- 点赞
- 收藏
- 关注作者
评论(0)