基于pytorch搭建AlexNet神经网络用于花类识别

🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:卡尔曼滤波系列1——卡尔曼滤波 张氏标定法原理详解
🍊近期目标:拥有5000粉丝
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
@[toc]
基于pytorch搭建AlexNet神经网络用于花类识别
写在前面
最近打算出一个基于pytorch搭建各种经典神经网络的系列。首先先谈谈关于这部分你需要哪些先验知识,如下:
- 对神经网络有一定的了解,当然了,本节针对AlexNet,那么你应对其有较深入的了解,不明白的请看我之前关于此部分的介绍,详情戳此图标☞☞☞
- 对pytorch有一定的了解,同样的,不了解的请移步至我之前的文章,详情戳此图标☞☞☞
完整网络模型训练步骤
读到这里,我就当你对我前面的要求的两点都明白了,一些基础的地方将不再叙述⛳⛳⛳
1、准备数据集
深度学习没有数据一切都是空谈,因此我们的第一步就是要准备数据集。看了我前面使用pytorch自己构建网络模型实战文章的同学应该可以发现,在那篇文章中我们的数据集使用的是CIFAR10,而这个数据集我们不需要额外准备,通过指定pytorch的函数参数就可以实现下载。而本篇文章使用的是花类数据集,一共有五个类别,分别是daisy(雏菊)、dandelion(蒲公英)、roses(玫瑰)、sunflowers(向日葵)和 tulips(郁金香)。我将数据集放在了gitee上,需要自取。
下面来看看这个数据集的结构,入下图所示:
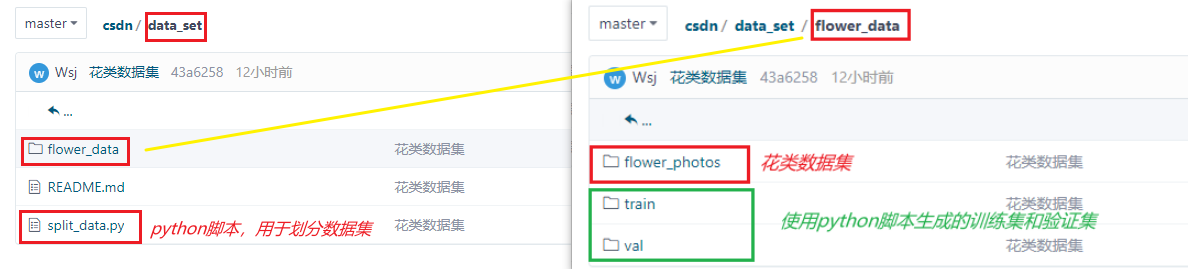
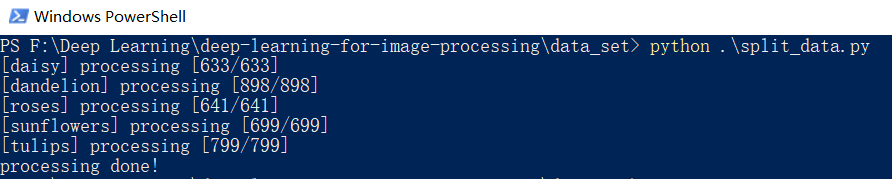
接着我们来说一下此脚本的使用方法:在data_set文件夹内使用shift + 右键 打开 PowerShell ,执行 “split_data.py” 分类脚本会自动将数据集划分成训练集train 和 验证集val。【我给的文件中已经划分好了,这一步可以不进行】
2、加载数据集
书写这篇文章的思路我想的是尽可能的和之前的使用pytorch自己构建网络模型实战文章做一个对比,这样可能会对训练网络的步骤有一个更清晰的认识,因此再阅读此文章前建议先看一下之前的文章。在前文构建网络模型实战中,还记得我们是怎么加载数据集的吗?如下图所示:

这里直接使用DataLoader函数来加载,这是因为pytorch中有CIFAR10这个数据集。而本文中的数据集并不包含在pytorch中,我们需要先使用datasets.ImageFolder()导入数据集,这个函数返回的对象是一个包含数据集所有图像及对应标签构成的二维元组容器,第一个元素为图像的张量表示形式,第二个元素为该图像所对应的标签。
# 对传入的数据进行处理,分为训练集和验证集
# 对这里的ToTensor和Normalize不理解的请看文章:https://blog.csdn.net/qq_47233366/article/details/124225860?spm=1001.2014.3001.5502
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(227), #随机剪裁
transforms.RandomHorizontalFlip(), #随机水平翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((227, 227)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
#下面三行为获取数据的路径
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
#使用ImageFolder导入数据集 【第一个参数root表示数据集路径 ; 第二个参数transform表示对图像数据进行变换】
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
我们可以来看一下train_dataset中第一个元素train_dataset[0]的内容来理解ImageFolder这个函数的输出,如下图所示:

可以看出,train_dataset[0]的第一个元素为tensor的张量,即图像数据,第二个元素为对应标签0,即daisy(雏菊)。得到了ImageFolder函数的返回结果train_dataset,就可以将这个返回结果传入DataLoader中进行加载,如下:
#设置batch_size大小
batch_size = 32
#使用DataLoader加载数据集
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
这里在强调一下加载数据集的含义,其实就类似于打包,比如这里的第二个参数设置的是batch_size=32,则表示把train_dataset中的32个数据打包一起放入Dataloader中。
上文已经对训练集进行了加载,验证集的思路和其一致,如下:
#导入验证集
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
#加载验证集
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
对ImageFolder函数和Dataloader函数的详情见链接:ImageFolder函数和Dataloader函数🍍🍍🍍
3、搭建神经网络✨✨✨
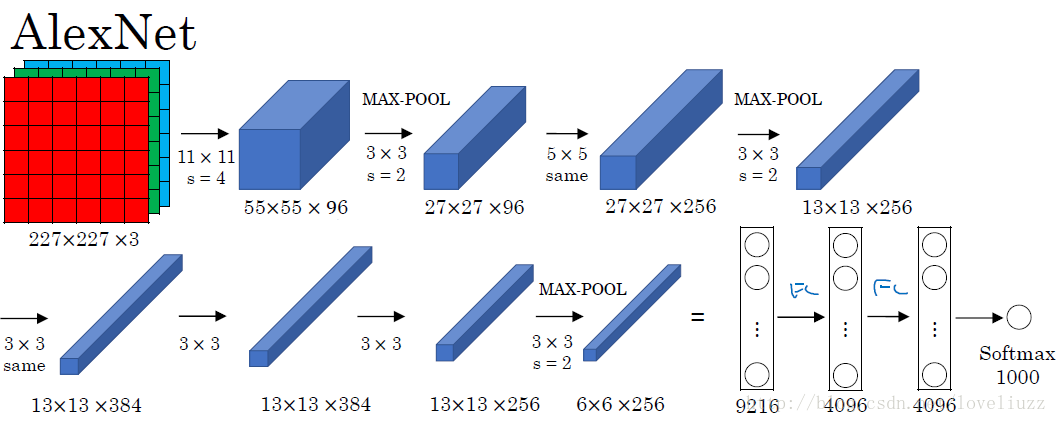
加载好数据后我们就可以搭建神经网络了,本次使用的神经网络结构为AlexNet,不了解的戳此图标☞☞☞了解详细。我们按照下图进行ALexNet网络的构建:
# 搭建网络模型
class AlexNet(nn.Module):
def __init__(self, num_classes=10000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, 11, 4, padding=0),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, padding=0),
nn.Conv2d(96, 256, 5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, padding=0),
nn.Conv2d(256, 384, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, padding=0),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
这部分是不难的,完全是照葫芦画瓢,只是本文在卷积层和全连接层后都加上了Relu激活函数并加上了Dropout函数。
4、创建网络模型
这步只要一行代码,其实就是实列化了一个对象。
# 创建网络模型
net = AlexNet(num_classes=5) #因为我们的数据有五个类别因此需要设置num_classes=5
我们可以打印出来看一看我们自己创建的网络模型,如下图。可以看出和前文的结构是一致的。
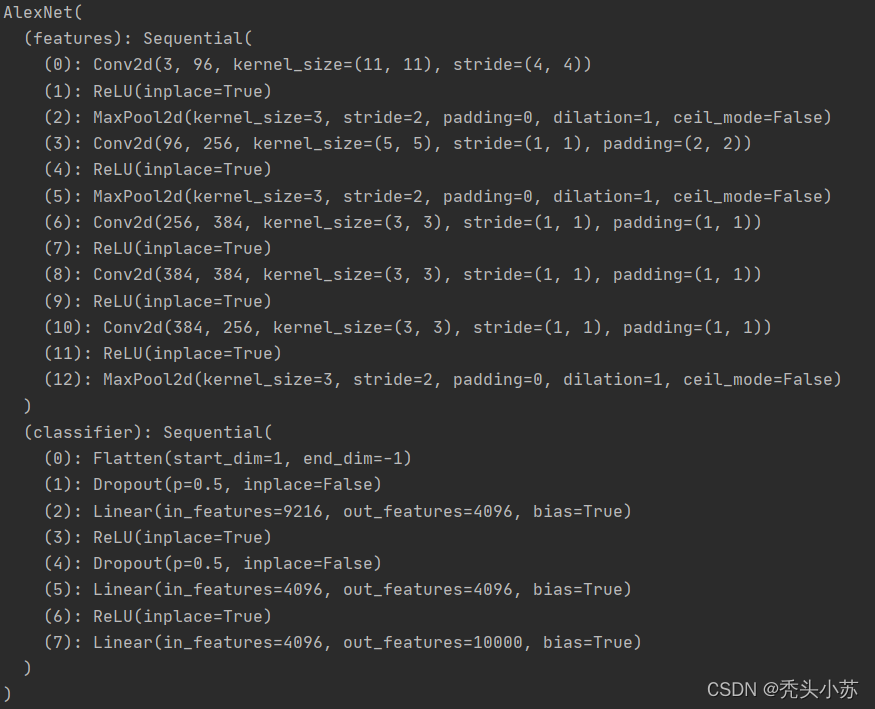
到这里我们已经创建好了自己的模型,这个模型输入是3x227x227的图片【可以认为就是一个3x227x227的张量】,输出是1x10000的向量。每当我们创建好一个模型后,应该检测一下模型的输入输出是否是我们所期待的,若不是则即使调整模型。我们可以用以下代码来检测输出是否符合要求。
net = AlexNet()
input = torch.ones((64, 3, 227, 227)) #64为batch_size,3x32x32表示张量尺寸
output = net(input)
print(output.shape)

可以看出输出是符合要求的,64是输入的batch_size,相当于输入64张图片。
5、设置损失函数、优化器等参数
# 用于GPU训练
net.to(device)
# 设置损失函数
loss_function = nn.CrossEntropyLoss()
# 设置优化器
optimizer = optim.Adam(net.parameters(), lr=0.0002)
# 设置epoch
epochs = 10
# 设置模型保持地址
save_path = './AlexNet.pth'
# 设置此参数,用于后期只保存最优的模型
best_acc = 0.0
6、开始训练网络✨✨✨
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train() # 开始训练,此网络有dropout,必须加
running_loss = 0.0
#tqdm用于显示训练进度
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
7、开始测试网络✨✨✨
# validate
net.eval() # 开始测试,验证过程中关闭 Dropout
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad(): #这句表示测试不需要进行反向传播,即不需要梯度变化
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
8、保存模型
# 保存当前的最优模型
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
9、模型训练结果
本次训练我是在GPU上训练,训练的结果如下图所示:

可以看出,在验证集上的准确率达到了0.701🥝🥝🥝
使用训练模型进行物体识别✨✨✨
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((227, 227)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "./tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = AlexNet(num_classes=5).to(device)
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
# 这里我因为是在GPU上训练的模型,然后拿到自己电脑上运行的(cpu),因此要加上map_location='cpu'
model.load_state_dict(torch.load(weights_path, map_location='cpu'))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu() # 将输出压缩,即压缩掉 batch 这个维度
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
print(print_res)
plt.show()
if __name__ == '__main__':
main()
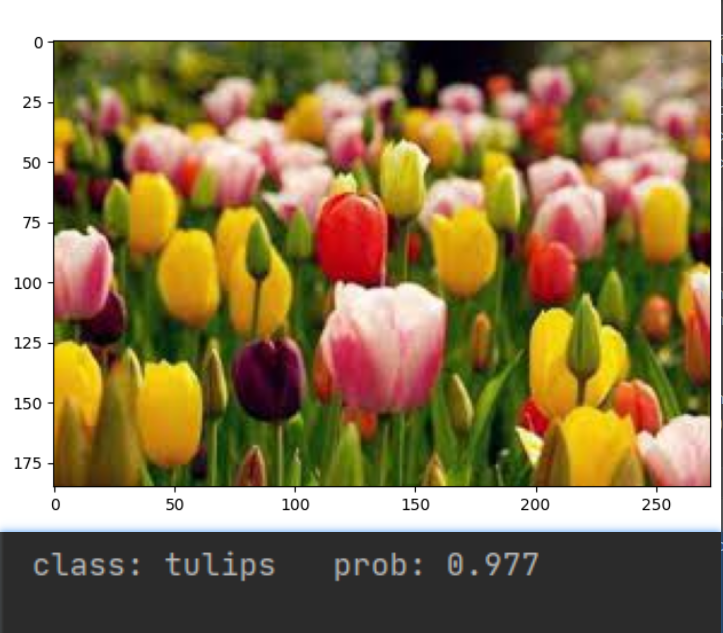
运行结果如下:可以看出检测到此图片是郁金香的概率为0.977🥗🥗🥗
小结
似乎也没什么好小结的,总之希望大家都能够有所收获叭🍚🍚🍚需要注意的是我们不可能对上述代码的每一个函数都无比熟悉,不明白的可以自己去查查资料,使用pycharm的调试功能或许也能够让你获益匪浅🌻🌻🌻
这部分谈谈一个使用GPU训练的小技巧,即让服务器后台进行训练,不必一直处于链接状态,方法如下:
screen -S xxxxxx为建立的窗口名称,可修改pyt hon xxx.py执行训练文件Ctrl + A + D退出screen窗口screen -ls查看有哪些窗口screen -r + 窗口编号进入某个窗口screen -X -S 窗口编号 quit杀死某个窗口
参考视频:https://www.bilibili.com/video/BV1W7411T7qc?spm_id_from=333.851.header_right.history_list.click🌸🌸🌸
这是一个宝藏UP主霹雳吧啦Wz,大家快去看🍏🍏🍏
如若文章对你有所帮助,那就🛴🛴🛴
咻咻咻咻~~duang~~点个赞呗

- 点赞
- 收藏
- 关注作者
评论(0)