机器学习自然语言处理之英文NLTK(代码+原理)


什么是自然语言处理?
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究如何能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
简单地说,自然语言处理( Natural Language Processing,简称 NLP)就是用计算机来处理、理解以及运用人类语言(如中文、英文等),它属于人工智能的一个分支,是计算机科学与语言学的交叉学科。
我们都知道,计算机是无法读懂我们人类的语言的,当我们把我们所谓的“自然语言”传输到计算中,对计算器而言这或许是一系列的无意义的字符格式数据,而我们的自然语言处理技术目的就是将这些无意义数据变为计算机有意义并可以计算的数值型数据。
一般的英文我们使用NLTK模块,中文使用jieba进行操作

透过现象看本质,才是真正的剖析方向
计算机是如何处理数据,计算机又是如何根据数据进行计算的,虽然当下已经有很多的主流编程语言了,我们似乎不需要去了解计算机到底是如何工作的,但是作为一个热爱编程的技术人员,你应该了解!
数据是数值类型的吗?我们进行计算机处理的时候,需要将其转为数值类型,不管是图像还是文本,不管是音频还是各类各样的数据类型,或者说你存在于这个世界,时时刻刻都在产生数据,那么数据到底是什么,在我认为,数据就是将宇宙万物连接起来的一个桥梁,如果世界没有了数据,那可能就像宇宙中的黑洞般的的“寂静”。
前期我们的机器学习的,分类模型,都是将数据进行转换为数值类型,然后带入模型中进行训练,及时存在一些文本数据,我们也可以进行编码处理,那么现在我们面对的时候一堆文字,我们又该如何处理呢?本篇文章,将带你了解当下计算机自然语言处理的步骤和原理,以及我们如何巧妙的将其与机器学习联合在一起,解决我们日常生活中的需要。

常用的自然语言处理技术
1)词条化, 即形态学分割。所谓的词条化简单的说就是把单词分成单个语素,并识别词素的种类。这项任务的难度很大程度上取决于所考虑语言的形态(即单词结构)的复杂性。英语具有相当简单的形态,尤其是屈折形态,因此常常可以简单地将单词的所有可能形式作为单独的单词进行建模。然而,在诸如土耳其语或美泰语这样的高度凝集的语言中,这种方法是不可行的,因为每一个字的词条都有成千上万个可能的词形。
2)词性标注, 即给定一个句子,确定每个单词的词性。在自然语言中有很多词,尤其是普通词,是会存在多种词性的。例如,英语中“ book”可以是名词或动词(“预订”);“ SET”可以是名词、动词或形容词;“ OUT”可以是至少五个不同的词类中的任何一个。有些语言比其他语言有更多的歧义。例如具有屈折形态的语言,如英语,尤其容易产生歧义。汉语的口语是一种音调语言,也十分容易产生歧义现象。这种变形不容易通过正字法中使用的实体来传达意图的含义。
3)词干还原是将不同词形的单词还原成其原型,在处理英文文档时,文档中经常会使用一些单词的不同形态,例如单词“ observe”,可能以“observe”“observers”“observed”“observer”出现,但是他们都是具有相同或相似意义的单词族,因此我们希望将这些不同的词形转换为其原型“observe”。在自然语言处理中,提取这些单词的原型在我们进行文本信息统计的时候是非常有帮助的,因此下文中我们将介绍如何使用 NLTK 模块来实现词干还原:
4)词型归并和词干还原的目的一样,都是将单词的不同词性转换为其原型,但是当词干还原算法简单粗略的去掉“小尾巴”这样的时候,经常会得到一些无意义的结果,例如“ wolves”被还原成“ wolv”,而词形归并指的是利用词汇表以及词形分析方法返回词的原型的过程。既归并变形词的结尾,例如“ ing”或者“es”,然后获得单词的原型,例如对单词“ wolves”进行词形归并,将得到“wolf”输出。
5)句法分析,确定给定句子的句法树(语法分析)。自然语言的语法是模糊的,一个普通的句子可能会有多种不同的解读结果。而目前主流的句法分析技术有两种主要的分析方法即依赖分析和选区分析。依赖句法分析致力于分析句子中的单词之间的关系(标记诸如主语和谓词之间的关系),而选区句法分析则侧重于使用概率来构造解析树。
6)断句,给定一大块文本,找出句子的边界。句子边界通常用句点或其他标点符号来标记,但这些相同的字符特殊情况下也会用于其他目的。

NLTK简介
Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库。
NLTK是一个开源的项目,包含:Python模块,数据集和教程,用于NLP的研究和开发。
NLTK由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。
NLTK包括图形演示和示例数据。其提供的教程解释了工具包支持的语言处理任务背后的基本概念。
NLTK的功能
搜索文本
单词搜索:
相似词搜索;
相似关键词识别;
词汇分布图;
生成文本;
- 1
- 2
- 3
- 4
- 5
分词
文本是由段落(Paragraph)构成的,段落是由句子(Sentence)构成的,句子是由单词构成的。切词是文本分析的第一步,它把文本段落分解为较小的实体(如单词或句子),每一个实体叫做一个Token,Token是构成句子(sentence )的单词、是段落(paragraph)的句子。NLTK能够实现句子切分和单词切分两种功能。
断句
from nltk.tokenize import sent_tokenize
text="""Hello Mr. Smith, how are you doing today? The weather is great, and
city is awesome.The sky is pinkish-blue. You shouldn't eat cardboard"""
tokenized_text=sent_tokenize(text)
print(tokenized_text)
'''
结果:
['Hello Mr. Smith, how are you doing today?',
'The weather is great, and city is awesome.The sky is pinkish-blue.',
"You shouldn't eat cardboard"]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
单句分词
import nltk
sent = "I am almost dead this time"
token = nltk.word_tokenize(sent)
# 结果:token['I','am','almost','dead','this','time']
- 1
- 2
- 3
- 4
- 5
过滤掉停用词
(1)移除标点符号
import string
"""移除标点符号"""
if __name__ == '__main__':
# 方式一
# s = 'abc.'
text_list = "Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome."
text_list = text_list.translate(str.maketrans(string.punctuation, " " * len(string.punctuation))) # abc
print("s: ", text_list)
# 方式二
english_punctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%']
text_list = [word for word in text_list if word not in english_punctuations]
print("text: ", text_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(2)移除停用词
import nltk
from nltk.corpus import stopwords
# nltk.download('stopwords')
# Downloading package stopwords to
# C:\Users\Administrator\AppData\Roaming\nltk_data\corpora\stopwords.zip.
# Unzipping the stopwords.zip
"""移除停用词"""
stop_words = stopwords.words("english")
if __name__ == '__main__':
text = "Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome."
word_tokens = nltk.tokenize.word_tokenize(text.strip())
filtered_word = [w for w in word_tokens if not w in stop_words]
print("word_tokens: ", word_tokens)
print("filtered_word: ", filtered_word)
'''
word_tokens:['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?',
'The', 'weather', 'is', 'great', ',', 'and', 'city', 'is', 'awesome', '.']
filtered_word:['Hello', 'Mr.', 'Smith', ',', 'today', '?', 'The', 'weather', 'great', ',', 'city', 'awesome', '.']
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
词汇规范化(Lexicon Normalization)
词汇规范化是指把词的各种派生形式转换为词根,在NLTK中存在两种抽取词干的方法porter和wordnet。
1)词形还原(lemmatization)
利用上下文语境和词性来确定相关单词的变化形式,根据词性来获取相关的词根,也叫lemma,结果是真实的单词。
基于字典的映射。nltk中要求手动注明词性,否则可能会有问题。因此一般先要分词、词性标注,再词性还原。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('leaves')
# 输出:'leaf'
- 1
- 2
- 3
- 4
2) 词干提取(stem)
从单词中删除词缀并返回词干,可能不是真正的单词。
# 基于Porter词干提取算法
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
porter_stemmer.stem('maximum')
# 基于Lancaster 词干提取算法
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
lancaster_stemmer.stem()
# 基于Snowball 词干提取算法
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer("english")
snowball_stemmer.stem('maximum')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
from nltk.stem.wordnet import WordNetLemmatizer # from nltk.stem import WordNetLemmatizer
lem = WordNetLemmatizer() # 词形还原
from nltk.stem.porter import PorterStemmer # from nltk.stem import PorterStemmer
stem = PorterStemmer() # 词干提取
word = "flying"
print("Lemmatized Word:",lem.lemmatize(word,"v"))
print("Stemmed Word:",stem.stem(word))
'''
Lemmatized Word: fly
Stemmed Word: fli
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
词性标注
词性(POS)标记的主要目标是识别给定单词的语法组,POS标记查找句子内的关系,并为该单词分配相应的标签。
sent = "Albert Einstein was born in Ulm, Germany in 1879."
tokens = nltk.word_tokenize(sent)
tags = nltk.pos_tag(tokens)
'''
[('Albert', 'NNP'), ('Einstein', 'NNP'), ('was', 'VBD'), ('born', 'VBN'),
('in', 'IN'), ('Ulm', 'NNP'), (',', ','), ('Germany', 'NNP'), ('in', 'IN'), ('1879', 'CD'), ('.', '.')]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取近义词
查看一个单词的同义词集用synsets(); 它有一个参数pos,可以指定查找的词性。WordNet接口是面向语义的英语词典,类似于传统字典。它是NLTK语料库的一部分。
import nltk
nltk.download('wordnet') # Downloading package wordnet to C:\Users\Administrator\AppData\Roaming\nltk_data...Unzipping corpora\wordnet.zip.
from nltk.corpus import wordnet
word = wordnet.synsets('spectacular')
print(word)
# [Synset('spectacular.n.01'), Synset('dramatic.s.02'), Synset('spectacular.s.02'), Synset('outstanding.s.02')]
print(word[0].definition())
print(word[1].definition())
print(word[2].definition())
print(word[3].definition())
'''
a lavishly produced performance
sensational in appearance or thrilling in effect
characteristic of spectacles or drama
having a quality that thrusts itself into attention
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
其他案例
from __future__ import division
import nltk
import matplotlib
from nltk.book import *
from nltk.util import bigrams
# 单词搜索
print('单词搜索')
text1.concordance('boy')
text2.concordance('friends')
# 相似词搜索
print('相似词搜索')
text3.similar('time')
#共同上下文搜索
print('共同上下文搜索')
text2.common_contexts(['monstrous','very'])
# 词汇分布表
print('词汇分布表')
text4.dispersion_plot(['citizens', 'American', 'freedom', 'duties'])
# 词汇计数
print('词汇计数')
print(len(text5))
sorted(set(text5))
print(len(set(text5)))
# 重复词密度
print('重复词密度')
print(len(text8) / len(set(text8)))
# 关键词密度
print('关键词密度')
print(text9.count('girl'))
print(text9.count('girl') * 100 / len(text9))
# 频率分布
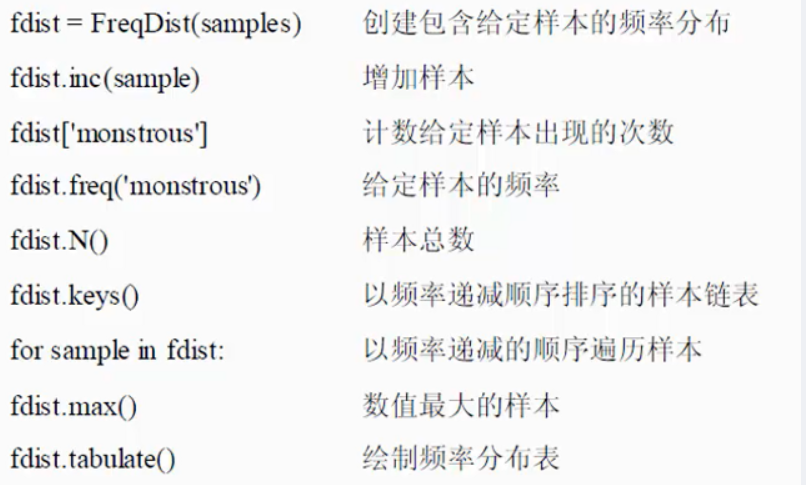
fdist = FreqDist(text1)
vocabulary = fdist.keys()
for i in vocabulary:
print(i)
# 高频前20
fdist.plot(20, cumulative = True)
# 低频词
print('低频词:')
print(fdist.hapaxes())
# 词语搭配
print('词语搭配')
words = list(bigrams(['louder', 'words', 'speak']))
print(words)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
大致上来说,我们在处理英文的时候,充分利用这方面的知识和语法,目前NLTK在这方面的生态都已经比较成熟了,我们可以通过它来解决英文项目。
nltk 怎么样使用中文?这是个大问题。这么个工具目前只能比较好的处理英文和其他的一些拉丁语系,谁让别人的单词与单词之间有个空格隔开呢!中文汉字一个挨一个的,nltk在分词这一关就过不去了,分词没法分,剩下的就都做不了。唯一能做的, 就是对网上现有的中文语料进行处理,这些语料都分好了词,可以使用nltk进行类似与英文的处理。
目前python中文分词的包,我推荐使用结巴分词。 使用结巴分词,之后,就可以对输出文本使用nltk进行相关处理。
也就说NLTK在分词方面并不是支持的,但是我们利用jieba分词之后,我们可以使用NLTK进行深入的研发和研究!
总而言之,在处理自然语言的过程中,我们的基本步骤就是:
1.相关第三包的准备
2.获取语料库及停用词信息
3.分词
4.词频统计
5.去停用词
6.基于TF-IDF理论、词袋模型等的文本向量化处理
7.机器学习、情感分析
8.简单可视化
后期我们会介绍比较详细的自然语言处理!欢迎关注!
每文一语
加油
文章来源: wxw-123.blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:wxw-123.blog.csdn.net/article/details/124881519

- 点赞
- 收藏
- 关注作者
评论(0)