如何构建、部署运行Flink程序

一、构建Flink程序
构建一个Flink程序有两种方式
方式一:构建 maven 工程,导入流式应用依赖包
<!-- 基础依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- DataStream -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.11.3</version>
<scope>provided</scope>
</dependency>
方式二:基础环境构建直接使用快捷命令【推荐在Mac或者Linux上使用】
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.11.3
* -s 构建 flink 版本
Flink程序一般的开发步骤
构建完成Flink程序之后就可以开发程序了,开发一个Flink程序的一般步骤:
- Obtain an execution environment,(构建流执行环境)
- Load/create the initial data,(加载初始化的数据)
- Specify transformations on this data,(指定此数据的转换)
- Specify where to put the results of your computations,(指定计算结果的放置位置)
- Trigger the program execution(触发程序执行)
二、快速上手Flink程序
批处理案例:
//批处理 (DataSet) 支持离线数据
public class WordCount {
public static void main(String[] args) throws Exception{
//创建执行环境
ExecutionEnvironment env=ExecutionEnvironment.getExecutionEnvironment();
//从文件中读取数据
String inputPath="text.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
//对数据集进行处理
DataSet<Tuple2<String,Integer>> resultSet = inputDataSet.flatMap(new MyflatMapper())
//按照第一个位置对word分组
.groupBy(0)
//将第二个位置上对数据求和
.sum(1);
resultSet.print();
}
//自定义类实现FlatMapFunction
public static class MyflatMapper implements FlatMapFunction<String,Tuple2<String,Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//按空格分词
String[] words=value.split(" ");
//遍历所有ord,包成二元组
for(String word:words){
out.collect(new Tuple2<>(word,1));
}
}
}
}
本地运行结果展示:
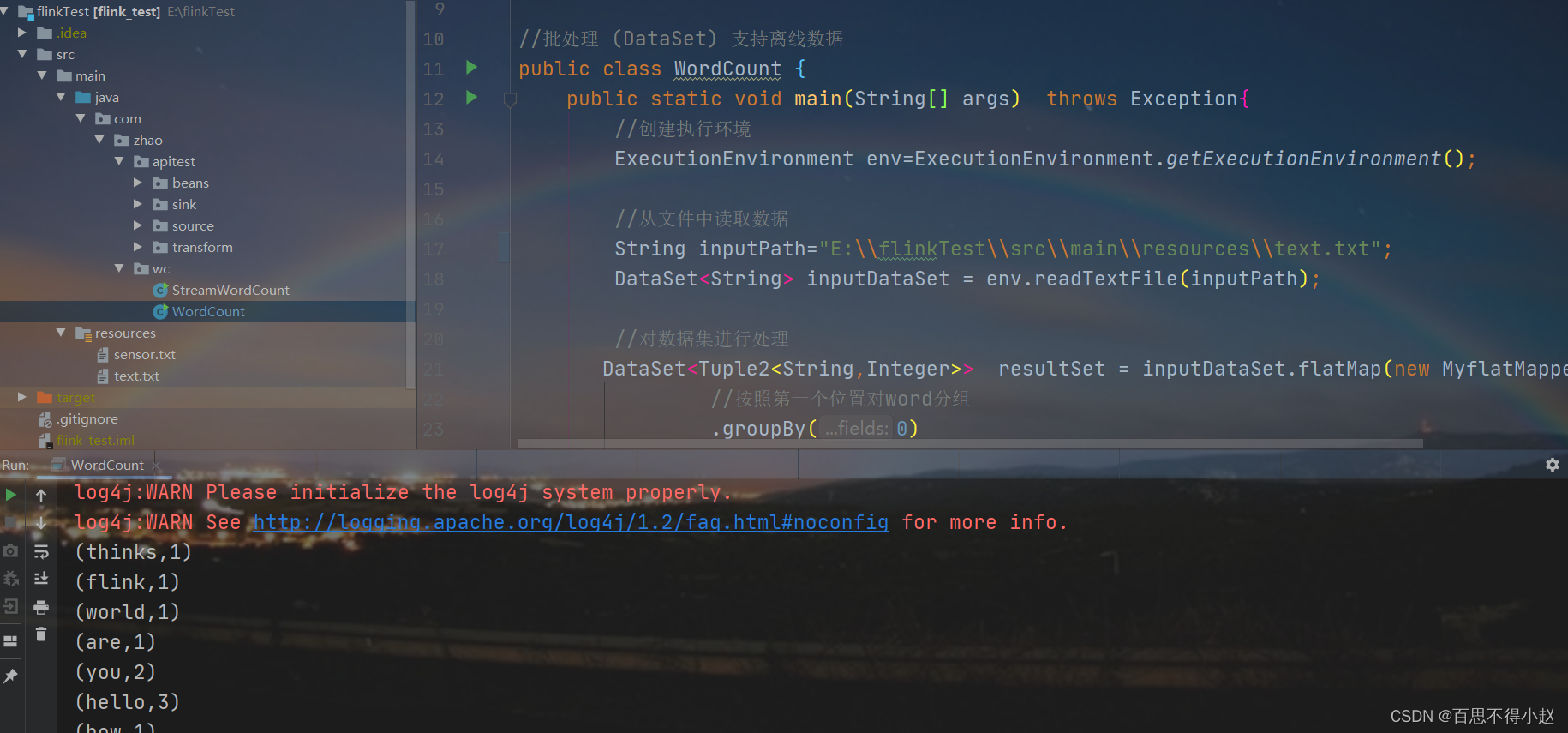
流处理案例:
//流处理 (DataStream)支持实时数据
public class StreamWordCount {
/**
* @author ZhaoPan
* @createTime 2022/3/2
* @description
*/
public static void main(String[] args) throws Exception {
//创建流处理环境
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度 相当于8个线程
//env.setParallelism(2);
//从文件中读取数据
String inputPath="text.txt";
DataStream<String> inputDataSream = env.readTextFile(inputPath);
//基于数据流进行转换计算
DataStream<Tuple2<String, Integer>> resultStream = inputDataSream.flatMap(new WordCount.MyflatMapper())
.keyBy(0)
.sum(1);
resultStream.print();
//执行任务
env.execute();
}
}
本地运行结果:
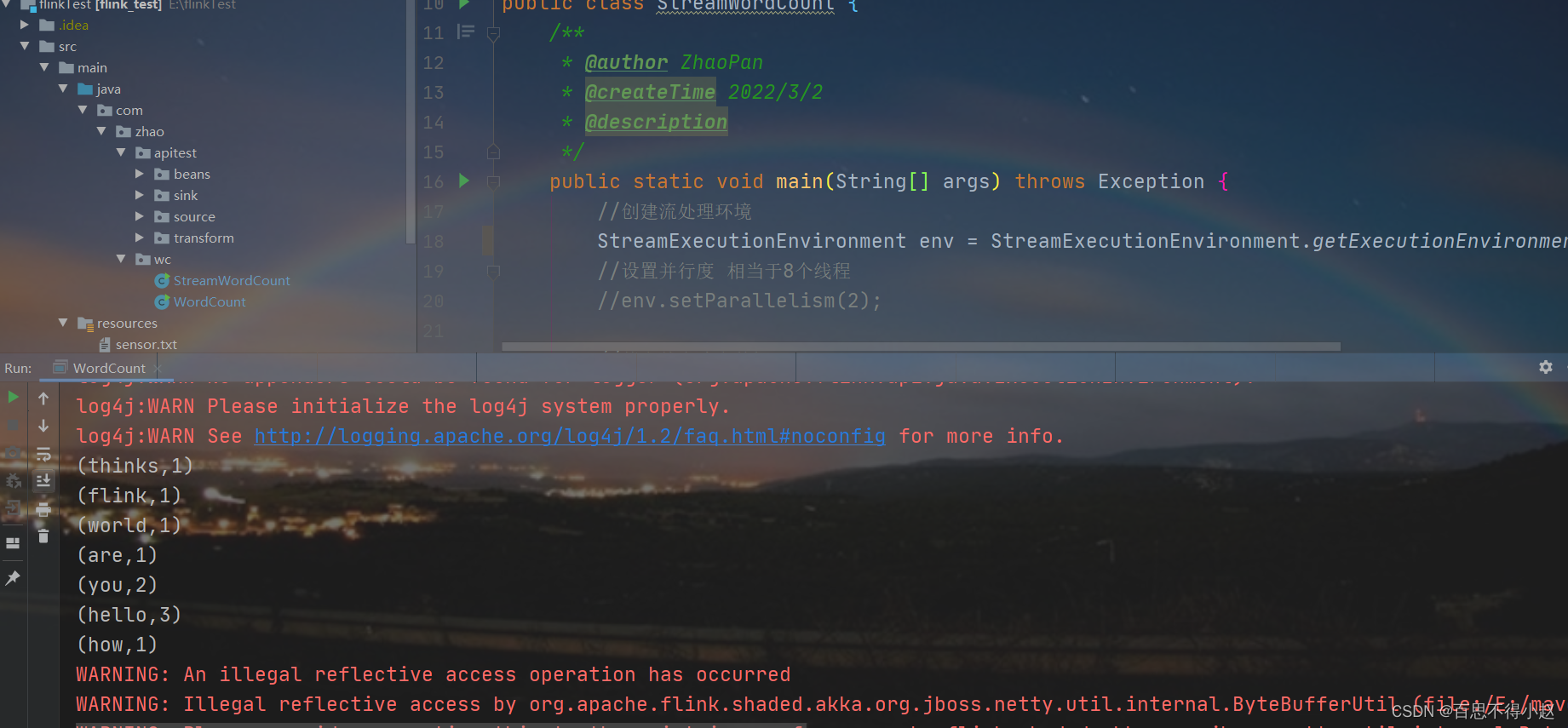
三、运行部署Flink程序
此处介绍两种部署Flink程序的方式:
方式一:Standalone 模式 单机【本地测试推荐】【重点】
1、官网下载 flink 包:https://flink.apache.org/downloads.html#update-policy-for-old-releases
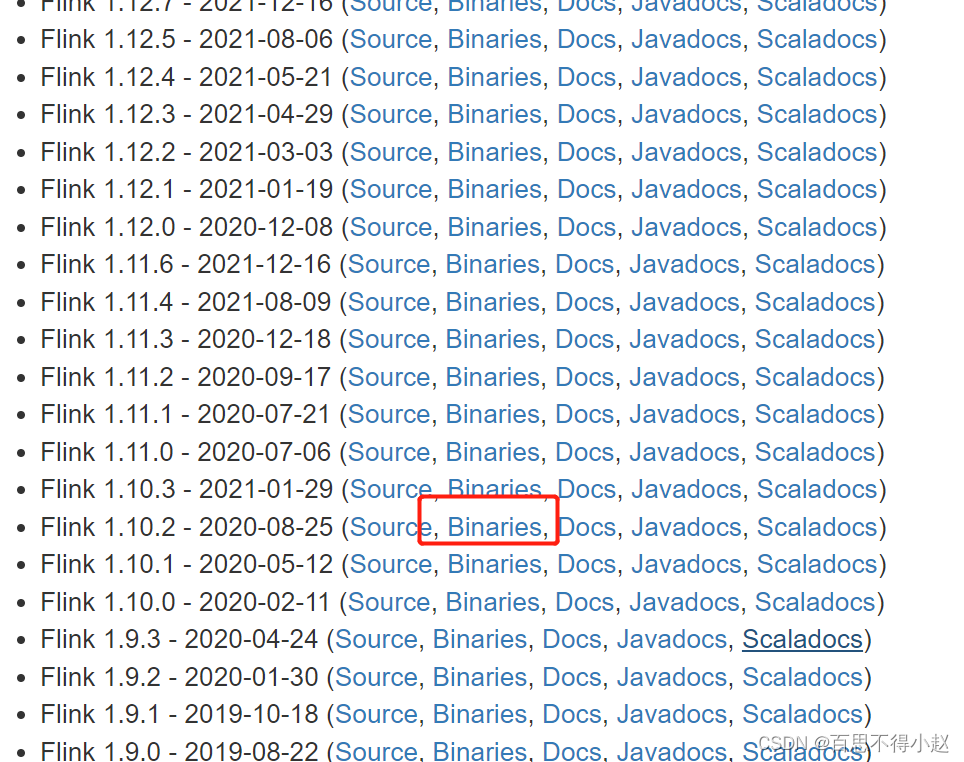
2、解压 flink-1.10.2-bin-scala_2.12 进入到 conf 目录,修改配置

# jobmanager节点可用的内存大小。
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
# taskmanager节点可用的内存代大小。
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
# 每台机器可用的cpu数量
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
# 默认情况下任务的并行度
parallelism.default: 1
slot 和 parallelism 总结:
1、slot 是静态的概念,是指 taskmanager 具有的并发执行能力
2、parallelism 是动态的概念,是指程序运行实际使用的并发能力
3、设置合适的 parallelism 来提高运算效率(kafka 应用一般和 partition 一一对应或成倍数关系配置)
flink从 1.8.0 版本开始,移除了对 hadoop 版本的依赖,在客户端包中需要提前将 hadoop 依赖添加到 flink 客户端 lib/ 目录下
==注意:此处下载完flink对应的tar包后,还需要下载hadoop的jar包,最后将jar包放入lib目录==

3、启动
进入bin目录 键入
./start-cluster.sh
 4、访问
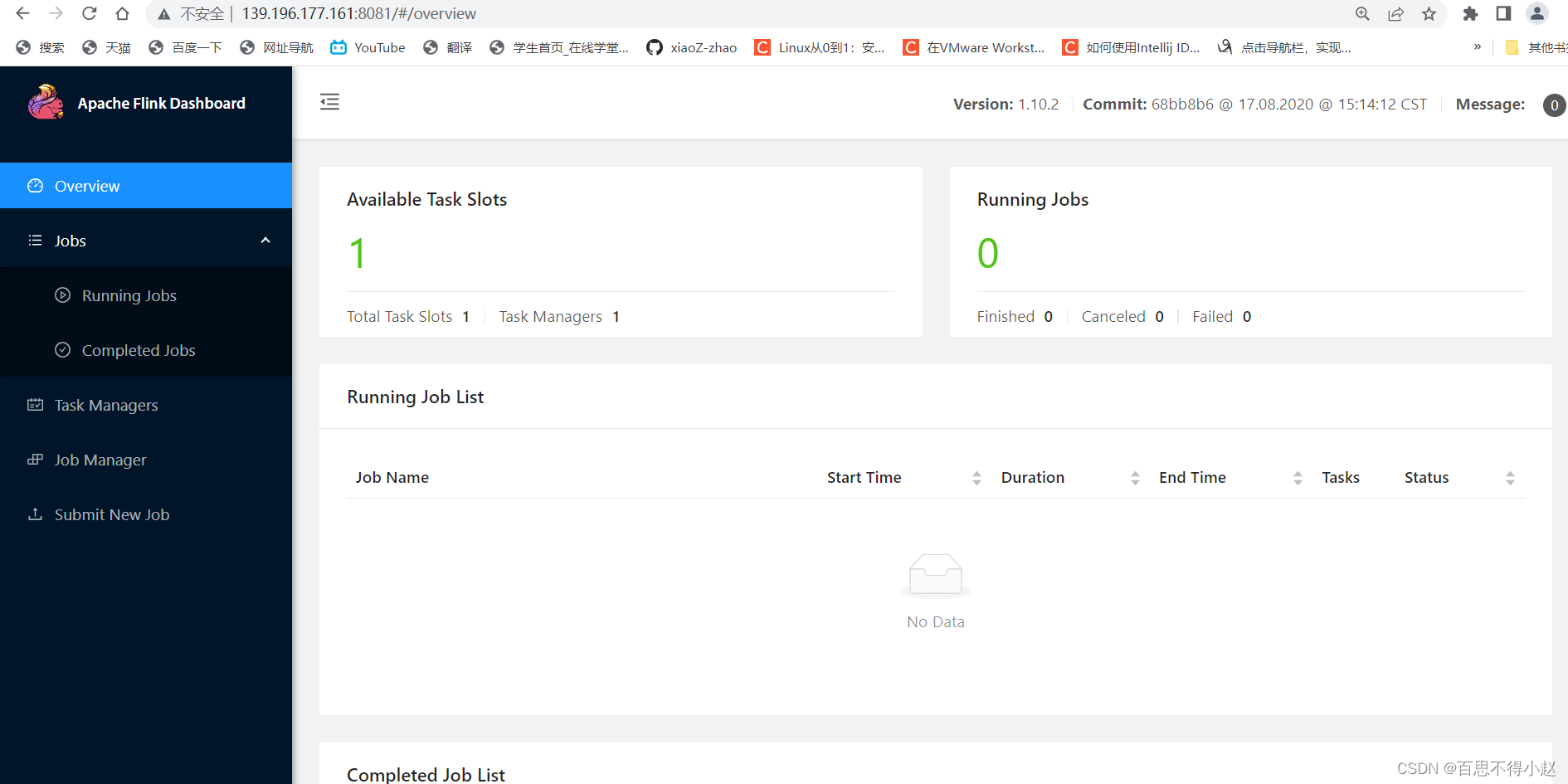
4、访问
==注:我这里是将服务部署在自己的服务器上,访问的时候通过IP+端口访问,本地的话就是localhost:8081==
至此就可以访问到如下前端页面,可以对 flink 集群和任务进行监控管理。
5、提交任务
- 后台命令方式提交:bin/flink run -h
- 打成jar包,前端提交

方式二:Yarn
以 Yarn 模式部署 Flink 任务时,要求 Flink 是有 Hadoop 支持的版本,Hadoop环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务。
Flink 提供了两种在 yarn 上运行的模式,分别为 Session-Cluster 和 Per-Job-Cluster模式。
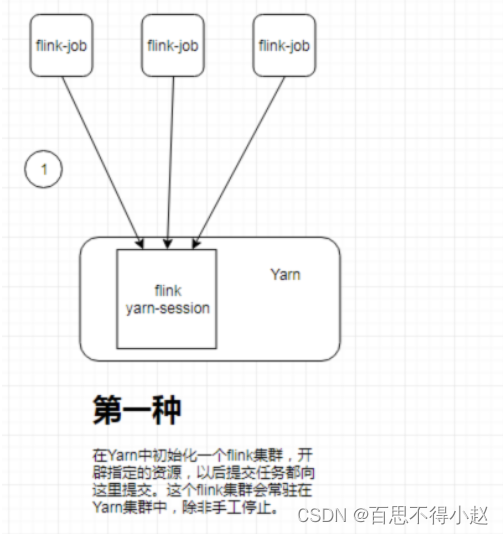
模式一:yarn-session
- 原理:在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn集群中,除非手工停止。当资源不足时,后提交的任务会进入等待,直到有任务结束释放资源
- 适用场景:适合规模小执行时间短的作业
部署运行步骤:
1、启动 yarn-session
bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
参数解读:
-n(--container):TaskManager的数量。
-s(--slots):每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
2、启动任务
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar
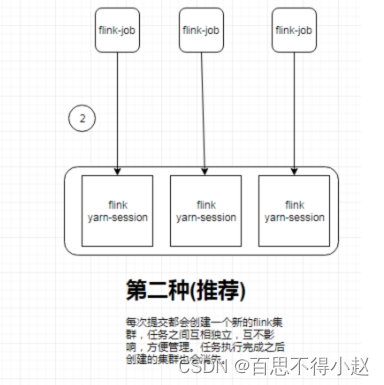
模式二:yarn-cluster【日常使用频次最高方式】
- 原理:提交任务的时候创建新的 Application,用来运行程序,如果没有任务就不用创建
- 适用场景:大型批任务,复杂性高、数据量大流式任务
启动任务
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1

- 点赞
- 收藏
- 关注作者
评论(0)