Flink流处理API大合集:掌握flink流处理API技术,看这一篇就够了

注:本文内容为纯干货,字数较多,建议先点赞收藏慢慢学习研读!
前言
一个Flink应用程序开发的步骤大致为五个步骤:构建执行环境、获取数据源、操作数据源、输出到外部系统、触发程序执行。由这五个模块组成了一个flink任务,接下来围绕着每个模块对应的API进行梳理。
以下所有的代码案例都已收录在本人的Gitee仓库,有需要的同学点击链接直接获取:
Gitee地址:https://gitee.com/xiaoZcode/flink_test

一、构建流执行环境(Environment)
getExecutionEnvironment()
创建一个执行环境,表示当前执行程序的上下文。 如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境。它会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
代码如下:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
createLocalEnvironment()
返回本地执行环境,需要在调用时指定默认的并行度。
代码如下:
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1);
createRemoteEnvironment()
返回集群执行环境,将 Jar 提交到远程服务器。需要在调用时指定 JobManager的 IP 和端口号,并指定要在集群中运行的 Jar 包。
代码如下:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createRemoteEnvironment("jobmanage-hostname", 6123, "YOURPATH//xxx.jar");
二、加载数据源(Source)
案例场景:
工业物联网的背景下,收集传感器的温度值,将收集到不同传感器的温度值进行计算分析操作。
注:以下代码都围绕此场景进行编写,获取更完整源代码请移步文章开头部分。
创建传感器对象:SensorReading
public class SensorReading {
private String id;
private Long timestamp;
private Double temperature;
public SensorReading() {
}
public SensorReading(String id, Long timestamp, Double temperature) {
this.id = id;
this.timestamp = timestamp;
this.temperature = temperature;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getTimestamp() {
return timestamp;
}
public void setTimestamp(Long timestamp) {
this.timestamp = timestamp;
}
public Double getTemperature() {
return temperature;
}
public void setTemperature(Double temperature) {
this.temperature = temperature;
}
@Override
public String toString() {
return "SensorReading{" +
"id='" + id + '\'' +
", timestamp=" + timestamp +
", temperature=" + temperature +
'}';
}
}
从集合读取数据
public class SourceTest1_Collection {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度为 1
env.setParallelism(1);
//从集合中读取数据
DataStream<SensorReading> dataStream = env.fromCollection(Arrays.asList(
new SensorReading("sensor_1", 1547718199L, 35.8),
new SensorReading("sensor_2", 1547718199L, 35.0),
new SensorReading("sensor_3", 1547718199L, 38.8),
new SensorReading("sensor_4", 1547718199L, 39.8)
));
DataStream<Integer> integerDataStream = env.fromElements(1, 2, 3, 4, 5, 789);
//打印输出
dataStream.print("data");
integerDataStream.print("int");
//执行程序
env.execute();
}
}
从文件读取数据
从文件中获取数据源的核心代码部分:
DataStream<String> dataStream = env.readTextFile("xxx ");
public class SourceTest2_File {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> dataStream = env.readTextFile("sensor.txt");
dataStream.print();
env.execute();
}
}
从Kafka读取数据
首先需要引入Kafka的以来到工程中
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
public class SourceTest3_Kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties=new Properties();
properties.setProperty("bootstrap.servers","localhost:9092");
properties.setProperty("group.id","consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset","latest");
DataStream<String> dataStream=env.addSource(new FlinkKafkaConsumer011<String>("sensor",new SimpleStringSchema(),properties));
dataStream.print();
env.execute();
}
}
自定义数据源Source
除了从集合、文件以及Kafka中获取数据外,还给我们提供了一个自定义source的方式,需要传入sourceFunction函数。核心代码如下:
DataStream<SensorReading> dataStream = env.addSource( new MySensor());
public class SourceTest4_UDF {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<SensorReading> dataStream = env.addSource(new MySensorSource());
dataStream.print();
env.execute();
}
// 实现自定义数据源
public static class MySensorSource implements SourceFunction<SensorReading>{
// 定义一个标记位,控制数据产生
private boolean running = true;
@Override
public void run(SourceContext<SensorReading> ctv) throws Exception {
// 随机数
Random random=new Random();
//设置10个初始温度
HashMap<String, Double> sensorTempMap = new HashMap<>();
for (int i = 0; i < 10; i++) {
sensorTempMap.put("sensor_"+(i+1), 60 + random.nextGaussian() * 20); // 正态分布
}
while (running){
for (String sensorId: sensorTempMap.keySet()) {
Double newTemp = sensorTempMap.get(sensorId) + random.nextGaussian();
sensorTempMap.put(sensorId,newTemp);
ctv.collect(new SensorReading(sensorId,System.currentTimeMillis(),newTemp));
}
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running=false;
}
}
}
三、转换算子(Transform)
获取到指定的数据源后,还要对数据源进行分析计算等操作,
基本转换算子:Map、flatMap、Filter

public class TransformTest1_Base {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("sensor.txt");
// 1. map 把String转换成长度生成
DataStream<Integer> mapStream = inputStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return value.length();
}
});
// 2. flatmap 按逗号切分字段
DataStream<String> flatMapStream = inputStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] fields=value.split(",");
for (String field : fields){
out.collect(field);
}
}
});
// 3. filter ,筛选sensor_1 开头对id对应的数据
DataStream<String> filterStream=inputStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("sensor_1");
}
});
// 打印输出
mapStream.print("map");
flatMapStream.print("flatMap");
filterStream.print("filter");
// 执行程序
env.execute();
}
}
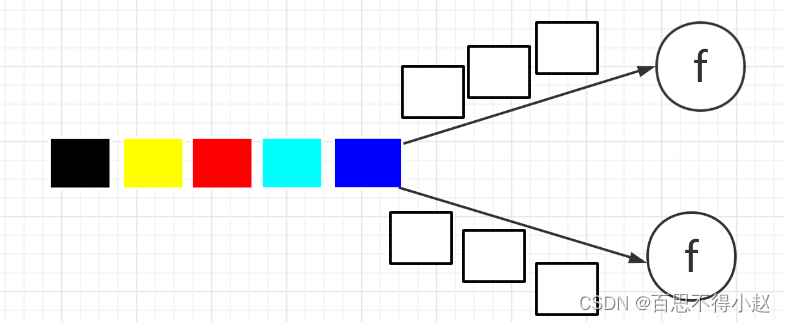
KeyBy、滚动聚合算子【sum()、min()、max()、minBy()、maxBy()】
- KeyBy:DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
- 如上算子可以针对 KeyedStream 的每一个支流做聚合。
public class TransformTest2_RollingAggregation {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
// DataStream<SensorReading> dataStream = inputStream.map(line -> {
// String[] fields = line.split(",");
// return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
// });
// 分组
KeyedStream<SensorReading, Tuple> keyedStream = dataStream.keyBy("id");
// KeyedStream<SensorReading, String> keyedStream1 = dataStream.keyBy(SensorReading::getId);
//滚动聚合,取当前最大的温度值
// DataStream<SensorReading> resultStream = keyedStream.maxBy("temperature");
DataStream<SensorReading> resultStream = keyedStream.maxBy("temperature");
resultStream.print();
env.execute();
}
}
Reduce
KeyedStream → DataStream:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
public class TransformTest3_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
// 分组
KeyedStream<SensorReading, Tuple> keyedStream = dataStream.keyBy("id");
// reduce 聚合,取最大的温度,以及当前最新对时间戳
DataStream<SensorReading> resultStream = keyedStream.reduce(new ReduceFunction<SensorReading>() {
@Override
public SensorReading reduce(SensorReading value1, SensorReading value2) throws Exception {
return new SensorReading(value1.getId(), value2.getTimestamp(), Math.max(value1.getTemperature(), value2.getTemperature()));
}
});
resultStream.print();
env.execute();
}
}
分流【Split 、Select】、合流【Connect 、CoMap、union】
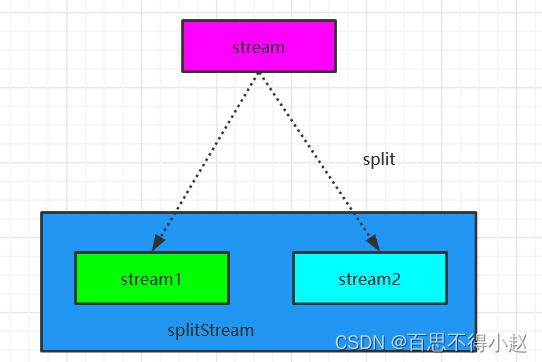
Split
DataStream → SplitStream:根据某些特征把一个 DataStream 拆分成两个或者多个 DataStream。
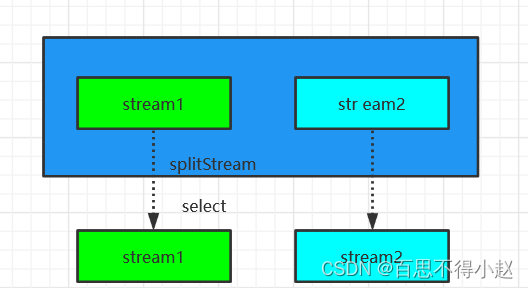
Select
SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个DataStream。
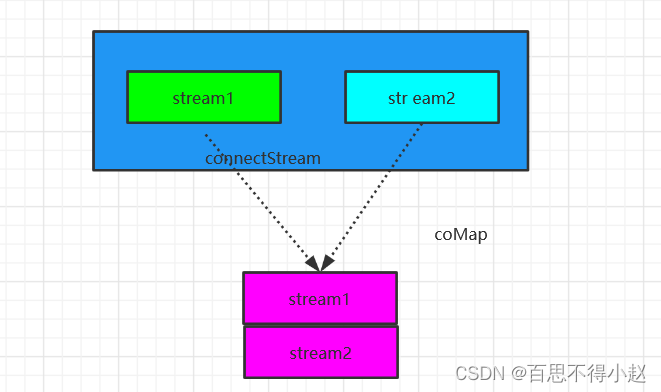
Connect
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。

CoMap、CoFlatMap
ConnectedStreams → DataStream:作用于 ConnectedStreams 上,功能与 map和 flatMap 一样,对 ConnectedStreams 中的每一个 Stream 分别进行 map 和 flatMap处理。
Union
DataStream → DataStream:对两个或者两个以上的 DataStream 进行 union 操作,产生一个包含所有 DataStream 元素的新 DataStream。
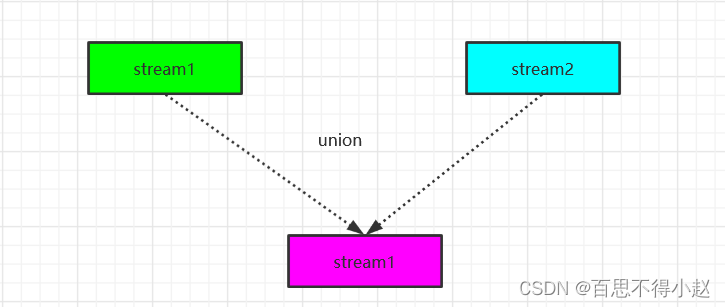
DataStream<SensorReading> unionStream = xxxstream.union(xxx);
==Connect 与 Union 区别:==
- Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap中再去调整成为一样的。
- Connect 只能操作两个流,Union 可以操作多个。
public class TransformTest4_MultipleStreams {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
// 1。分流 按照温度值30度为界进行分流
SplitStream<SensorReading> splitStream = dataStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading value) {
return (value.getTemperature() > 30) ? Collections.singletonList("high") : Collections.singletonList("low");
}
});
// 通过条件选择对应流数据
DataStream<SensorReading> highTempStream = splitStream.select("high");
DataStream<SensorReading> lowTempStream = splitStream.select("low");
DataStream<SensorReading> allTempStream = splitStream.select("high","low");
highTempStream.print("high");
lowTempStream.print("low");
allTempStream.print("all");
// 2。合流 connect,先将高温流转换为二元组,与低温流合并后,输出状态信息。
DataStream<Tuple2<String, Double>> warningStream = highTempStream.map(new MapFunction<SensorReading, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), value.getTemperature());
}
});
// 只能是两条流进行合并,但是两条流的数据类型可以不一致
ConnectedStreams<Tuple2<String, Double>, SensorReading> connectStream = warningStream.connect(lowTempStream);
DataStream<Object> resultStream = connectStream.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> value) throws Exception {
return new Tuple3<>(value.f0, value.f1, "high temp warning");
}
@Override
public Object map2(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), "normal");
}
});
resultStream.print();
// 3。union联合多条流 限制就是每条流数据类型必须一致
DataStream<SensorReading> union = highTempStream.union(lowTempStream, allTempStream);
union.print("union stream");
env.execute();
}
}
四、数据输出(Sink)
Flink官方提供了一部分框架的Sink,用户也可以自定义实现Sink。flink将任务进行输出的操作核心代码:stream.addSink(new MySink(xxxx))。
Kafka
引入Kafka依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
public class SinkTest1_Kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("/Volumes/Update/flink/flink_test/src/main/resources/sensor.txt");
// 转换成SensorReading类型
DataStream<String> dataStream=inputStream.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2])).toString();
}
});
//输出到外部系统
dataStream.addSink(new FlinkKafkaProducer011<String>("localhost:9092","sinktest",new SimpleStringSchema()));
env.execute();
}
}
Redis
引入Redis依赖:
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
public class SinkTest2_Redis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("/Volumes/Update/flink/flink_test/src/main/resources/sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
// jedis配置
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("localhost")
.setPort(6379)
.build();
dataStream.addSink(new RedisSink<>(config,new MyRedisMapper()));
env.execute();
}
// 自定义RedisMapper
public static class MyRedisMapper implements RedisMapper<SensorReading>{
//自定义保存数据到Redis的命令,存成hash表Hset
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET,"sensor_temp");
}
@Override
public String getKeyFromData(SensorReading data) {
return data.getId();
}
@Override
public String getValueFromData(SensorReading data) {
return data.getTemperature().toString();
}
}
}
Elasticsearch
引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.12</artifactId>
<version>1.10.1</version>
</dependency>
public class SinkTest3_ES {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env;
env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("/Volumes/Update/flink/flink_test/src/main/resources/sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
// 定义ES的链接配置
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("localhost",9200));
dataStream.addSink(new ElasticsearchSink.Builder<SensorReading>(httpHosts,new MyEsSinkFunction()).build());
env.execute();
}
//实现自定义的ES写入操作
public static class MyEsSinkFunction implements ElasticsearchSinkFunction<SensorReading> {
@Override
public void process(SensorReading element, RuntimeContext ctx, RequestIndexer indexer) {
// 定义写入的数据source
HashMap<String, String> dataSource = new HashMap<>();
dataSource.put("id",element.getId());
dataSource.put("temp",element.getTemperature().toString());
dataSource.put("ts",element.getTimestamp().toString());
// 创建请求作为向ES发起的写入命令
IndexRequest indexRequest = Requests.indexRequest()
.index("sensor")
.type("readingdata")
.source(dataSource);
// 用indexer发送请求
indexer.add(indexRequest);
}
}
}
自定义Sink(JDBC)
引入依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
public class SinkTest4_JDBC {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
dataStream.addSink(new MyJDBCSink());
env.execute();
}
// 实现自定义SinkFunction
public static class MyJDBCSink extends RichSinkFunction<SensorReading> {
//声明连接和预编译
Connection connection=null;
PreparedStatement insert=null;
PreparedStatement update=null;
@Override
public void open(Configuration parameters) throws Exception {
connection= DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","123456");
insert=connection.prepareStatement("insert into sensor_temp (id,temp) values (?,?)");
update=connection.prepareStatement("update sensor_temp set temp = ? where id = ? ");
}
// 每来一条数据,调用链接,执行sql
@Override
public void invoke(SensorReading value, Context context) throws Exception {
// 直接执行更新
update.setDouble(1,value.getTemperature());
update.setString(2,value.getId());
update.execute();
if (update.getUpdateCount() == 0){
insert.setString(1,value.getId());
insert.setDouble(2,value.getTemperature());
insert.execute();
}
}
// 关闭连接流
@Override
public void close() throws Exception {
connection.close();
insert.close();
update.close();
}
}
}
五、数据类型、UDF 函数、富函数
Flink支持的数据类型
- Flink 支持所有的 Java 和 Scala 基础数据类型,Int, Double, Long, String等
DataStream<Integer> numberStream = env.fromElements(1, 2, 3, 4);
- Java 和 Scala 元组(Tuples)
DataStream<Tuple2<String, Integer>> personStream = env.fromElements(
new Tuple2("Adam", 17),
new Tuple2("Sarah", 23) );
personStream.filter(p -> p.f1 > 18);
- Flink 对 Java 和 Scala 中的一些特殊目的的类型也都是支持的,比如 Java 的
ArrayList,HashMap,Enum 等等
UDF 函数
Flink 暴露了所有 udf 函数的接口(实现方式为接口或者抽象类)。例如MapFunction, FilterFunction, ProcessFunction 等等。
富函数(Rich Functions)
“富函数”是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都有其 Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。RichMapFunction、RichFlatMapFunction、RichFilterFunction
==Rich Function 有一个生命周期的概念。典型的生命周期方法有:==
- open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter 被调用之前open()会被调用。
- close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函 数执行的并行度,任务的名字,以及state 状态。
public class TransformTest5_RichFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
//从文件读取数据
DataStream<String> inputStream = env.readTextFile("sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream=inputStream.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String s) throws Exception {
String[] fields=s.split(",");
return new SensorReading(fields[0],new Long(fields[1]),new Double(fields[2]));
}
});
DataStream<Tuple2<String,Integer>> resultStream=dataStream.map(new MyMapper());
resultStream.print();
env.execute();
}
public static class MyMapper0 implements MapFunction<SensorReading,Tuple2<String,Integer>>{
@Override
public Tuple2<String, Integer> map(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(),value.getId().length());
}
}
// 继承富函数
public static class MyMapper extends RichMapFunction<SensorReading,Tuple2<String,Integer>>{
@Override
public Tuple2<String, Integer> map(SensorReading value) throws Exception {
// getRuntimeContext().getState()
return new Tuple2<String,Integer>(value.getId(),getRuntimeContext().getIndexOfThisSubtask());
}
@Override
public void open(Configuration parameters) throws Exception {
// 初始化工作,一般是定义状态,或者创建数据库链接
System.out.println("open");
// super.open(parameters);
}
@Override
public void close() throws Exception {
// 关闭链接,收尾状态
System.out.println("close");
// super.close();
}
}
}

- 点赞
- 收藏
- 关注作者
评论(0)