Redis基础

1.什么是Redis
基于内存,单线程,多路复用,多数据类型
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
1) 字符串类型 string
2) 哈希类型 hash
3) 列表类型 list
4) 集合类型 set
5) 有序集合类型 sortedset
redis命令:https://www.redis.net.cn/order/
redis文档:http://redisdoc.com/
redis官网:https://redis.io/
不管是同步阻塞还是同步非阻塞,对系统性能的提升都是很小的。而通过复用可以使一个或一组线程(线程池)处理多个TCP连接。所以IO多路复用设计目的其实不是为了快,而是为了解决线程/进程数量过多对服务器开销造成的压力。同一个线程同时处理多个IO请求的目的
2. redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒
• 分布式集群架构中的session分离
不同的数据结构对应不同的业务场景
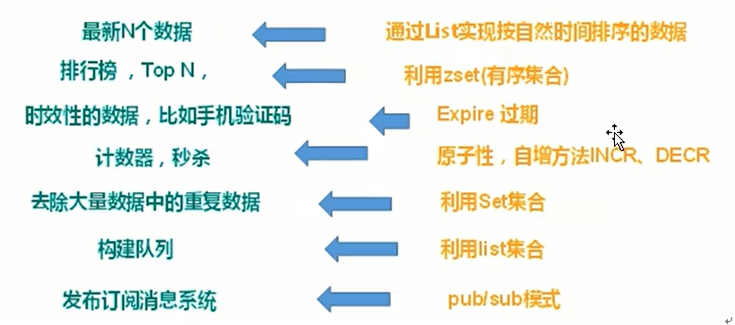
总的场景
热点数据,不易修改的数据,大量数据
3.下载安装
1. 官网:https://redis.io
2. 中文网:http://www.redis.net.cn/
3. 解压直接可以使用:
* redis.windows.conf:配置文件
* redis-cli.exe:redis的客户端
* redis-server.exe:redis服务器端
4.每个数据类型的介绍
字符串类型String
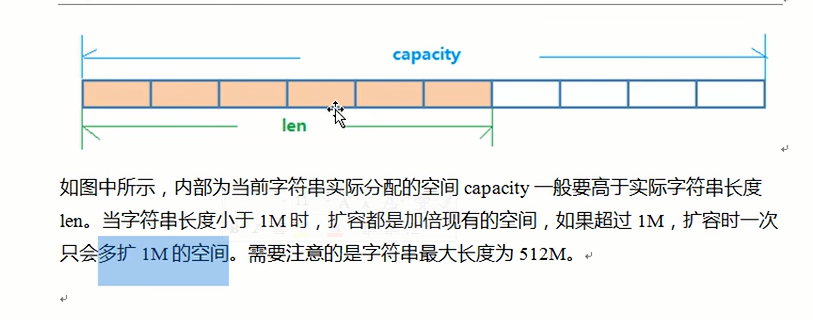
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
哈希类型 hash
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field 和value 的映射表,hash特别适合用于存储对象。
类似Java里边的Map<String,Object>
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable了
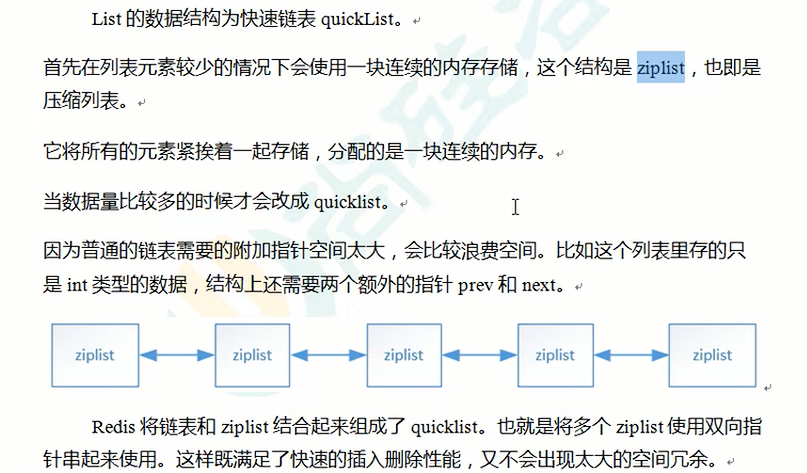
列表类型 list:
可以添加一个元素到列表的头部(左边)或者尾部(右边)
Redis列表是最简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能更高,通过索引下标的操作中间的节点性能会较差。

集合类型 set :
Redis的set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O1。
一个算法,随着数据的增加,执行时间的长短,如果是o(1),数据增加,查找数据的时间不变。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
有序集合类型 sortedset:
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了。
因为元素是有序的,所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
底层原理:
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String,Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
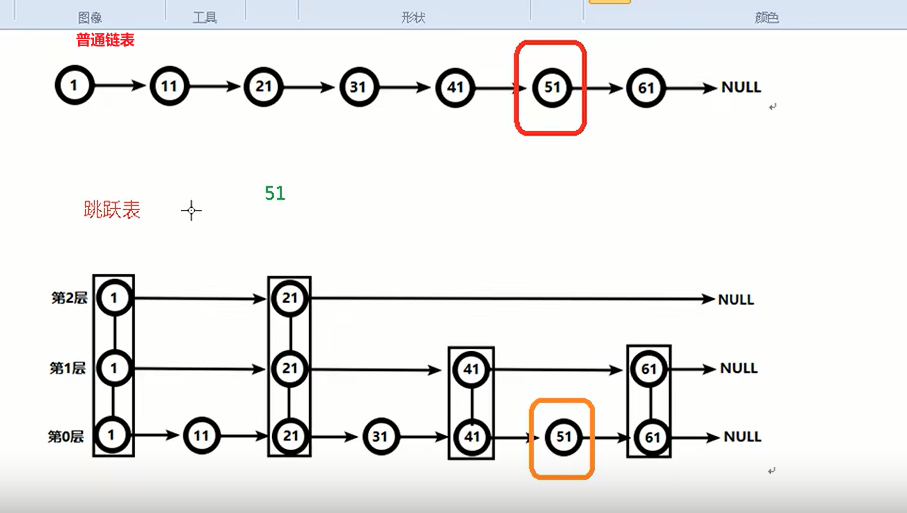
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。有序集合在3.0版本中,最高32层
跳跃表


- 点赞
- 收藏
- 关注作者
评论(0)