【愚公系列】2022年05月 .NET架构班 067-分布式中间件 Elasticsearch分词器

一、ElasticSearch-分词器
1.什么是分词器
分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引。
2.ElasticSearch分词器类型
Elasticsearch 中内置了一些分词器,这些分词器只能对英文进行分词处理,无法将中文的词识别出来。所以ElasticSearch需要自定义中文分词器。
2.1 ElasticSearch之内置分词器
| 属性 | 说明 |
|---|---|
| standard | 标准分词器,是Elasticsearch中默认的分词器,可以拆分英文单词,大写字母统一转换成小写。 |
| simple | 按非字母的字符分词,例如:数字、标点符号、特殊字符等,会去掉非字母的词,大写字母统一转换成小写。 |
| whitespace | 简单按照空格进行分词,相当于按照空格split了一下,大写字母不会转换成小写。 |
| stop | 会去掉无意义的词,例如:the、a、an 等,大写字母统一转换成小写。 |
| keyword | 不拆分,整个文本当作一个词。 |
2.2 ElasticSearch之IK分词器
Elasticsearch中内置的分词器不能对中文进行分词,因此我们需要再安装一个能够支持中文的分词器,IK分词器就是个不错的选择。
IK分词器下载网址:https://github.com/medcl/elasticsearch-analysis-ik
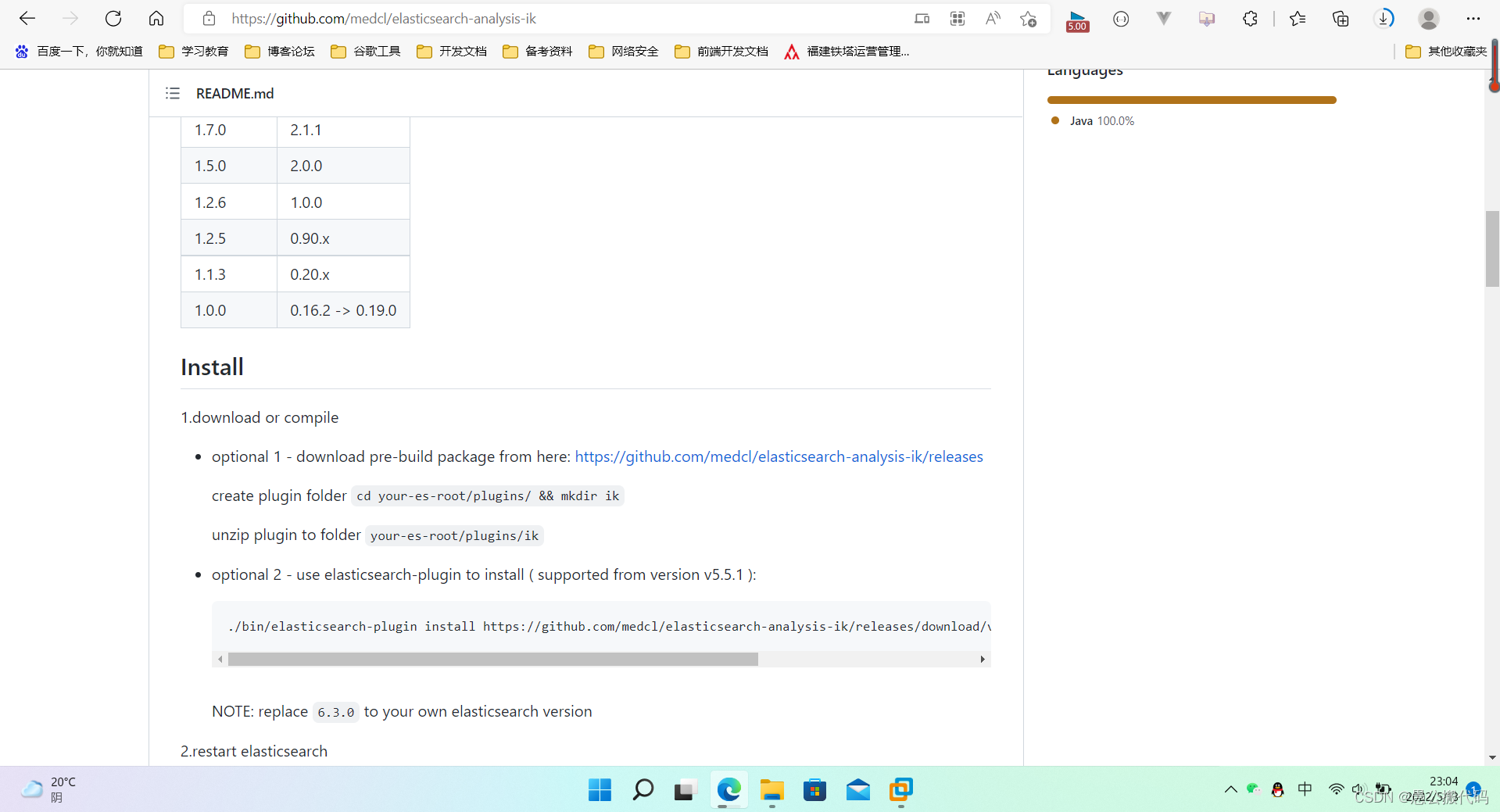
注意:分词器版本必须和ES版本一致
二、.NET Core ElasticSearch分词器落地
1.创建项目
vs2022创建项目
2.下载Elasticsearch
下载地址:https://www.elastic.co/downloads/elasticsearch
3.然后启动Elasticsearch
通过cmd执行命令
./elasticsearch.bat
默认地址:http://localhost:9200/
4、在项目中引入NEST
dotnet add package NEST
在项目中NEST连接Elasticsearch,通过NEST提供的API进行添加商品数据,然后在进行模糊查询。
三、ElasticSearch根据片段查询出文档
ElasticSearch根据片段查询出文档步骤如下:
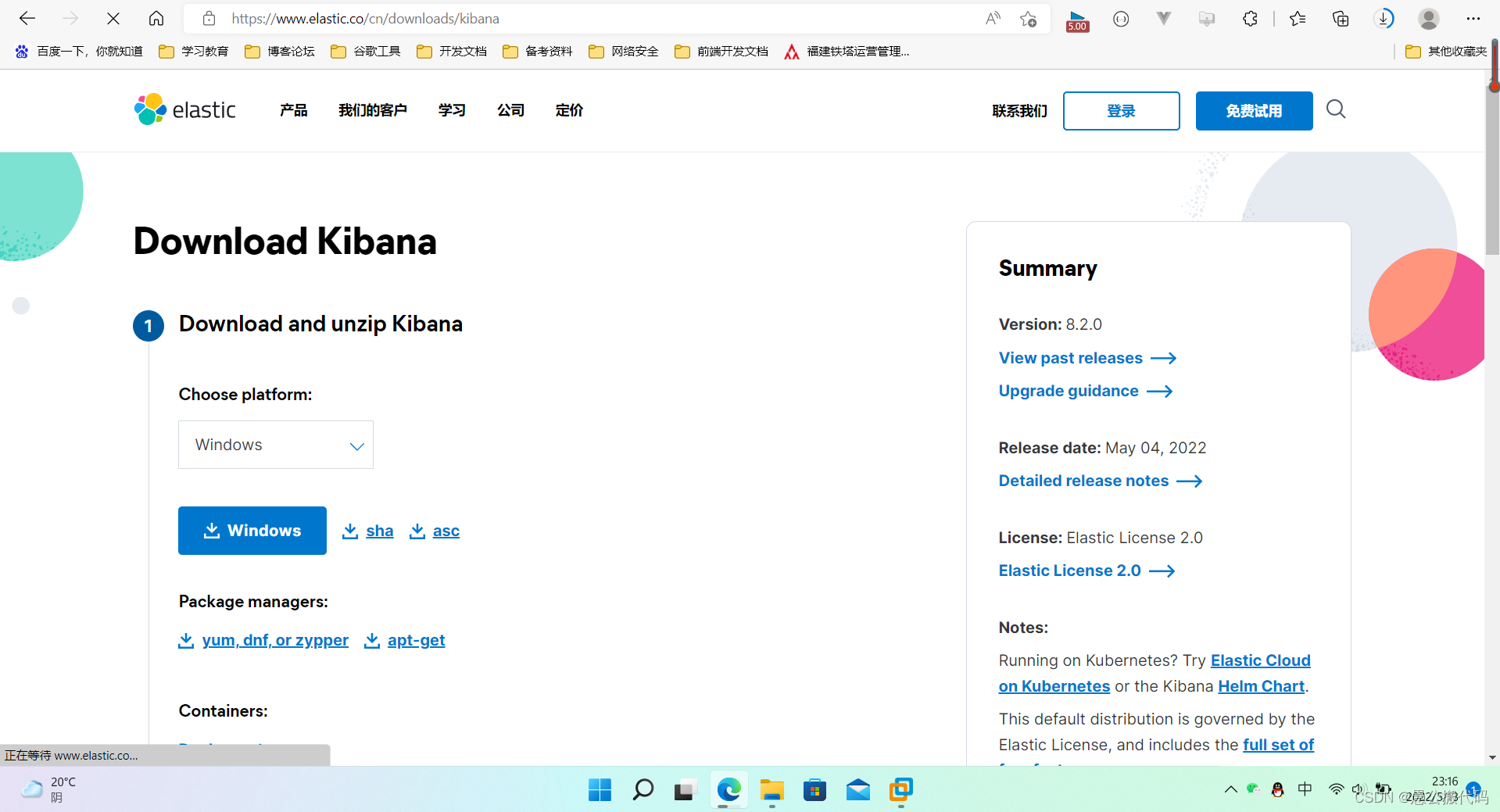
1、先下载kibana。
Kibana是一个设计出来用于和Elasticsearch一起使用的开源的分析与可视化平台,可以用kibana 搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等展示高级数据分析与可视化,基于浏览器的接口使你能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘,让大量数据变得简单,容易理解
注意:安装kibana时,必须先安装elasticsearch且kibana的版本和elasticsearch的版本号必须一致
kibana下载网址:https://www.elastic.co/cn/downloads/kibana
2、然后配置kibana
kibana\config\kibana.yml配置文件,此处根据自己实际减压后的路径去找kibana.yml配置文件。
添加如下:
elasticsearch.hosts:["http://localhost:9200"]
i18n.locale:"zh-CN"
3、然后进入bin目录直接cmd启动:
kibana.bat
4、打开kibana,直接进入开发者工具页面
5、 然后通过分析器分析文本
GET products/_analyze
{
"text": "愚公搬代码"
}
即可得到被分词后的效果。默认使用是standard标准分析器实现
四、ElasticSearch Analyzer 分析器执行原理
ElasticSearch 分词时候主要做了如下三个事情:
- 字符过滤器 char_filter:过滤不必要的分词符号
- 分词器 tokenizer:实现分词规则
- 词单元过滤器 filter:实现自定义操作
五、ElasticSearch指定字段进行分词
1.先通过kibana查询Index商品表对应Mapping映射
GET products/_mapping
2.查看映射关系
发现string 都被默认转换成为了text文本。只有文本才能实现分词
ElasticSearch无法修改映射。需要重新创建索引。就是数据库
3.重新创建Index商品,然后指定映射。
PUT producs_0
{
"mappings": {
"properties": {
"productTitle": {
"type": "keyword"
}
}
}
}
4.迁移数据
POST _reindex
{
"source": {
"index": "products"
},
"dest": {
"index": "products_0"
}
}
5.查询映射关系
GET products_0/_mapping
然后在客户端查询数据
六、ElasticSearch进行自定义分词
1.先创建商品数据库products_1
PUT mall_product_8
{
"settings": {
"analysis": {
"analyzer": {
"my_tony":{
"type": "custom",
"char_filter": [ "html_strip"],
"tokenizer": "standard",
"filter":[ "lowercase"]
}
}
}},
"mappings": {
"properties": {
"productTitle": {
"type": "text",
"analyzer": "my_tony"
}
}
}
}
2.然后在数据库products_1中进行测试
GET product_1/_analyze
{
"analyzer": "my_tony",
"text": "<HTML>p6架构班TTEST11wqaaa"
}
然后进行数据读写
七.ElasticSearch进行自定义分词扩展
1、先进入到bin目录,然后安装elasticsearch-analysis-ik
elasticsearch-plugin.bat install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.1/elasticsearch-analysis-ik-7.10.1.zip
2、然后创建index数据库products_2
PUT products_2
{
"mappings": {
"properties": {
"productTitle": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
3、然后进行验证
GET mall_product_8/_analyze
{
"analyzer": "ik_max_word",
"text": "p6架构班"
}

- 点赞
- 收藏
- 关注作者
评论(0)