python 数据分析机器学习sklearn包快速上手

【摘要】 python 数据分析机器学习介绍
1 sklearn自带数据集
sklearn中带有很多数据集
from sklearn import datasets
diabetes=datasets.load_diabetes()
X=diabetes.data
y=diabetes.target
X.shape
X[:5]
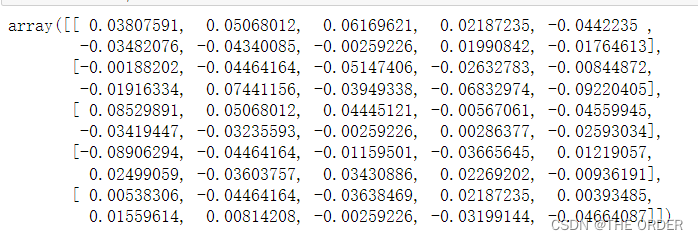
y[:10]
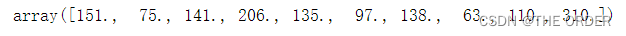
2 使用sklearn包中的模型
from sklearn.linear_model import Lasso #L1正则化线性回归
import numpy as np
from sklearn.model_selection import GridSearchCV
X_train=diabetes.data[:310]
y_train=diabetes.target[:310]
X_test=diabetes.data[310:]
y_test=diabetes.data[310:]
lasso=Lasso(random_state=0)
alphas=np.logspace(-4,-0.5,30)
estimator=GridSearchCV(lasso,dict(alpha=alphas))#估计器,里面是lasso这个模型,超参dict(alphas)
estimator.fit(X_train,y_train)#30个lasso模型比较,返回最好的模型

最高的评分
estimator.best_score_
0.46170948106181964
最好的模型
estimator.best_estimator_
Lasso(alpha=0.07880462815669913, random_state=0)
3 预测数据
estimator.predict(X_test)


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)