Spark基础学习笔记26:Spark SQL数据源 - JSON数据集

【摘要】
文章目录
零、本讲学习目标一、读取JSON文件概述二、读取JSON文件案例演示(一)创建JSON文件并上传到HDFS(二)读取JSON文件,创建临时表,进行关联查询1、读取user.json文件,...
文章目录
零、本讲学习目标
- 掌握如何读取JSON文件
- 掌握如何进行关联查询
一、读取JSON文件概述
- Spark SQL可以自动推断JSON文件的Schema,并将其加载为DataFrame。在加载和写入JSON文件时,除了可以使用
load()方法和save()方法外,还可以直接使用Spark SQL内置的json()方法。该方法不仅可以读写JSON文件,还可以将Dataset[String]类型的数据集转为DataFrame。 - 需要注意的是,要想成功地将一个JSON文件加载为DataFrame,JSON文件的每一行必须包含一个独立有效的JSON对象,而不能将一个JSON对象分散在多行。
二、读取JSON文件案例演示
(一)创建JSON文件并上传到HDFS
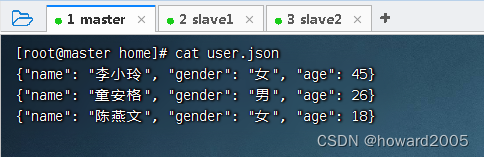
- 创建
user.json文件

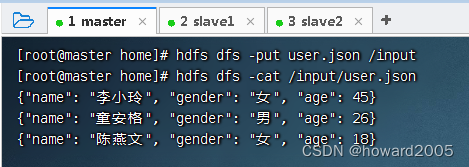
- 上传到HDFS的
/input目录
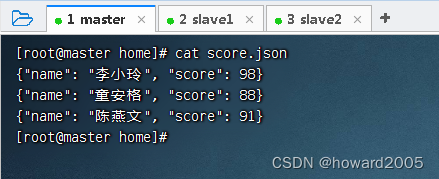
- 创建
score.json文件
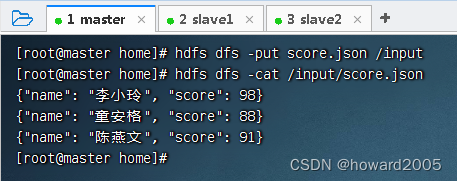
- 上传到HDFS的
/input目录
(二)读取JSON文件,创建临时表,进行关联查询
1、读取user.json文件,创建临时表t_user
- 执行命令:
val userdf = spark.read.json("hdfs://master:9000/input/user.json")
- 查看用户数据帧的内容
- 创建临时表
t_user

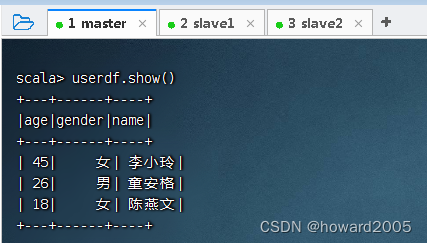
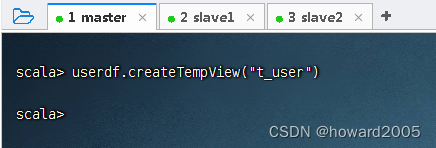
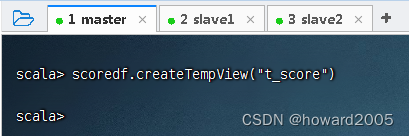
2、读取score.json文件,创建临时表t_score
- 执行命令:
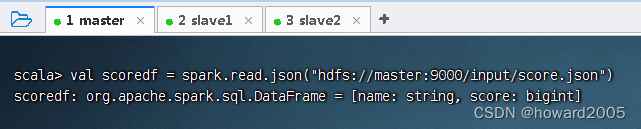
val scoredf = spark.read.json("hdfs://master:9000/input/score.json")
- 查看成绩数据帧的内容
- 创建临时表
t_score
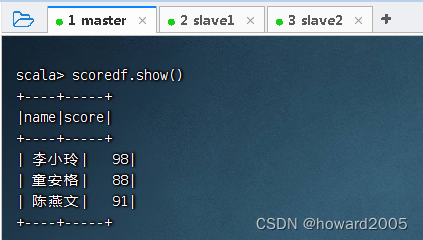
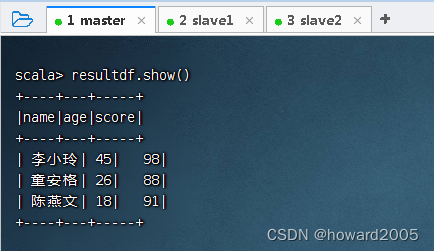
3、关联查询生成新的数据帧
- 执行命令:
val resultdf = spark.sql("select u.name, u.age, s.score from t_user u inner join t_score s on u.name = s.name")
- 查看结果数据帧的内容

(三)利用json()方法将数据集转成数据帧
1、在Spark Shell里交互式完成任务
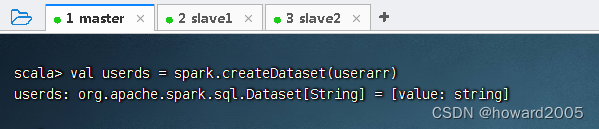
- 创建用户数组:执行命令:
val userarr = Array("{'name': 'Mike', 'age': 18}", "{'name': 'Alice', 'age': 30}", "{'name': 'Brown', 'age': 38}")
- 基于用户数组创建用户数据集,执行命令:
val userds = spark.createDataset(userarr)
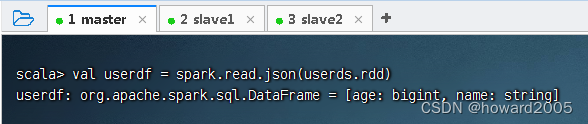
- 将用户数据集转成用户数据帧,执行命令:
val userdf = spark.read.json(userds.rdd)(注意要将数据集转成RDD才能作为json()方法的参数)
- 显示用户数据帧的内容

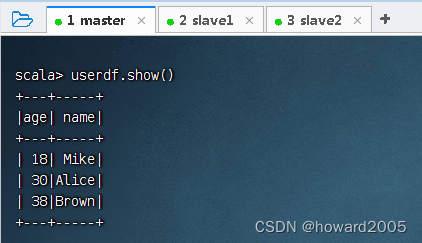
2、在IDEA里编写Scala程序完成任务
- 创建
Dataset2DataFrame单例对象
package net.hw.sparksql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:利用json()方法将数据集转成数据帧
* 作者:华卫
* 日期:2022年05月11日
*/
object Dataset2DataFrame {
def main(args: Array[String]): Unit = {
// 设置HADOOP用户名属性,否则本地运行访问会被拒绝
System.setProperty("HADOOP_USER_NAME", "root")
// 创建或得到SparkSession
val spark = SparkSession.builder()
.appName("SparkSQLDataSource")
.master("local[*]")
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 创建用户数组
val userarr = Array("{'name': 'Mike', 'age': 18}",
"{'name': 'Alice', 'age': 30}",
"{'name': 'Brown', 'age': 38}")
// 基于用户数组创建用户数据集
val userds: Dataset[String] = spark.createDataset(userarr)
// 将用户数据集转成用户数据帧
val userdf = spark.read.json(userds.rdd)
// 显示用户数据帧内容
userdf.show()
}
}
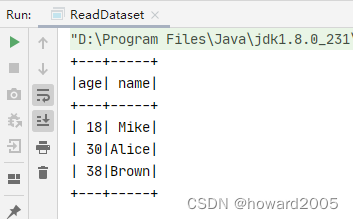
- 运行程序,查看结果
文章来源: howard2005.blog.csdn.net,作者:howard2005,版权归原作者所有,如需转载,请联系作者。
原文链接:howard2005.blog.csdn.net/article/details/124717761

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)