Kubernetes 系列(3)核心资源对象

目录
文章目录
Object
Object 是 Kubernetes 系统中的持久化实体(存储在 etcd cluster 中),Kubernetes 使用这些 objects 来表示集群中的状态。
这些 Object 描述了哪些应用应该运行在集群中,它们请求的资源下限和上限以及重启、升级和容错的策略。每一个创建的对象其实都是我们对集群状态的改变,这些对象描述的其实就是集群的期望状态,Kubernetes 会根据我们指定的期望状态不断检查对当前的集群状态进行迁移。
type Deployment struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec DeploymentSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status DeploymentStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
每一个 Object 都包含两个嵌套对象来描述规格(Spec)和状态(Status),对象的规格其实就是我们期望的目标状态,而状态描述了对象的当前状态,这部分一般由 Kubernetes 系统本身提供和管理,是我们观察集群本身的一个接口。
容器与镜像
什么是容器?
在介绍容器的具体概念之前,先简单回顾一下操作系统是如何管理进程的。
首先,当我们登录到操作系统之后,可以通过 ps 等操作看到各式各样的进程,这些进程包括系统自带的服务和用户的应用进程。那么,这些进程都有什么样的特点?
- 第一,这些进程可以相互看到、相互通信;
- 第二,它们使用的是同一个文件系统,可以对同一个文件进行读写操作;
- 第三,这些进程会使用相同的系统资源。
这样的三个特点会带来什么问题呢?
- 因为这些进程能够相互看到并且进行通信,高级权限的进程可以攻击其他进程;
- 因为它们使用的是同一个文件系统,因此会带来两个问题:这些进程可以对于已有的数据进行增删改查,具有高级权限的进程可能会将其他进程的数据删除掉,破坏掉其他进程的正常运行;此外,进程与进程之间的依赖可能会存在冲突,如此一来就会给运维带来很大的压力;
- 因为这些进程使用的是同一个宿主机的资源,应用之间可能会存在资源抢占的问题,当一个应用需要消耗大量 CPU 和内存资源的时候,就可能会破坏其他应用的运行,导致其他应用无法正常地提供服务。
针对上述的三个问题,如何为进程提供一个独立的运行环境呢?
-
针对不同进程使用同一个文件系统所造成的问题而言,Linux 和 Unix 操作系统可以通过 chroot 系统调用将子目录变成根目录,达到视图级别的隔离;进程在 chroot 的帮助下可以具有独立的文件系统,对于这样的文件系统进行增删改查不会影响到其他进程;
-
因为进程之间相互可见并且可以相互通信,使用 Namespace 技术来实现进程在资源的视图上进行隔离。在 chroot 和 Namespace 的帮助下,进程就能够运行在一个独立的环境下了;
-
但在独立的环境下,进程所使用的还是同一个操作系统的资源,一些进程可能会侵蚀掉整个系统的资源。为了减少进程彼此之间的影响,可以通过 Cgroup 来限制其资源使用率,设置其能够使用的 CPU 以及内存量。
综上可以得到答案:容器就是一个视图隔离、资源可限制、独立文件系统的进程集合。
- 所谓 “视图隔离” 就是能够看到部分进程以及具有独立的主机名等;
- 控制资源使用率则是可以对于内存大小以及 CPU 使用个数等进行限制;
- 容器具有一个独立的文件系统,因为使用的是系统的资源,所以在独立的文件系统内不需要具备内核相关的代码或者工具,我们只需要提供容器所需的二进制文件、配置文件以及依赖即可。只要容器运行时所需的文件集合都能够具备,那么这个容器就能够运行起来。
什么是镜像?
综上所述,我们将这些:容器运行时所需要的所有的文件集合称之为容器镜像。
通常情况下,我们会采用 Dockerfile 来构建镜像,这是因为 Dockerfile 提供了非常便利的语法糖,能够帮助我们很好地描述构建的每个步骤。当然,每个构建步骤都会对已有的文件系统进行操作,这样就会带来文件系统内容的变化,我们将这些变化称之为 changeset。当我们把构建步骤所产生的变化依次作用到一个空文件夹上,就能够得到一个完整的镜像。
changeset 的分层以及复用特点能够带来几点优势:
- 第一,能够提高分发效率,简单试想一下,对于大的镜像而言,如果将其拆分成各个小块就能够提高镜像的分发效率,这是因为镜像拆分之后就可以并行下载这些数据;
- 第二,因为这些数据是相互共享的,也就意味着当本地存储上包含了一些数据的时候,只需要下载本地没有的数据即可,举个简单的例子就是 golang 镜像是基于 alpine 镜像进行构建的,当本地已经具有了 alpine 镜像之后,在下载 golang 镜像的时候只需要下载本地 alpine 镜像中没有的部分即可;
- 第三,因为镜像数据是共享的,因此可以节约大量的磁盘空间,简单设想一下,当本地存储具有了 alpine 镜像和 golang 镜像,在没有复用的能力之前,alpine 镜像具有 5M 大小,golang 镜像有 300M 大小,因此就会占用 305M 空间;而当具有了复用能力之后,只需要 300M 空间即可。
如何运行容器?
运行一个容器一般情况下分为三步:
- 第一步:从镜像仓库中将相应的镜像下载下来;
- 第二步:当镜像下载完成之后就可以通过 docker images 来查看本地镜像,这里会给出一个完整的列表,我们可以在列表中选中想要的镜像;
- 第三步:当选中镜像之后,就可以通过 docker run 来运行这个镜像得到想要的容器,当然可以通过多次运行得到多个容器。一个镜像就相当于是一个模板,一个容器就像是一个具体的运行实例,因此镜像就具有了一次构建、到处运行的特点。
容器运行时的生命周期
容器是一组具有隔离特性的进程集合,在使用 docker run 的时候会选择一个镜像来提供独立的文件系统并指定相应的运行程序。这里指定的运行程序称之为 initial 进程,这个 initial 进程启动的时候,容器也会随之启动,当 initial 进程退出的时候,容器也会随之退出。
因此,可以认为容器的生命周期和 initial 进程的生命周期是一致的。当然,因为容器内不只有这样的一个 initial 进程,initial 进程本身也可以产生其他的子进程或者通过 docker exec 产生出来的运维操作,也属于 initial 进程管理的范围内。当 initial 进程退出的时候,所有的子进程也会随之退出,这样也是为了防止资源的泄漏。
但是这样的做法也会存在一些问题,首先应用里面的程序往往是有状态的,其可能会产生一些重要的数据,当一个容器退出被删除之后,数据也就会丢失了,这对于应用方而言是不能接受的,所以需要将容器所产生出来的重要数据持久化下来。容器能够直接将数据持久化到指定的目录上,这个目录就称之为数据卷。
数据卷有一些特点,其中非常明显的就是数据卷的生命周期是独立于容器的生命周期的,也就是说容器的创建、运行、停止、删除等操作都和数据卷没有任何关系,因为它是一个特殊的目录,是用于帮助容器进行持久化的。简单而言,我们会将数据卷挂载到容器内,这样一来容器就能够将数据写入到相应的目录里面了,而且容器的退出并不会导致数据的丢失。
通常情况下,数据卷管理主要有两种方式:
-
第一种是通过 bind 的方式,直接将宿主机的目录直接挂载到容器内;这种方式比较简单,但是会带来运维成本,因为其依赖于宿主机的目录,需要对于所有的宿主机进行统一管理。
-
第二种是将目录管理交给运行引擎。
Pod
Kubernetes 以 Pod 为最小单位进行调度、扩展、资源分配、管理生命周期。Pod 的运行模式通常设置为单个主容器,也可选择添加对日志支持等辅助功能的挎斗模式(sidecar)容器。Pod 通常由 Deployment 管理。
为什么要引入 Pod 这一逻辑对象?
-
可管理性:有些容器天生就是需要紧密联系,一起工作的。例如:微服务中的 Side Car(边车)模式,Pod 中的一个 ContainerA 提供业务,另一个 ContainerB 专门负责对 ContainerA 进行收集、监控日志和流量信息;又例如:ContainerA 作为 File Puller 定期从外部拉取最新的文件,将其存放到共享 Volume 中,ContainerB 作为 Web Server 直接从 Volume 读取文件,两个 Containers 紧密合作;Pod 将 Containers 封装到一个部署单元中。
-
通信和资源共享:Pod 中的所有 Containers 使用同一个 network namespace,即 Containers 具有相同的 IP 地址和 Port 空间,它们互相之间可以直接用 localhost 进行通信。同样的,这些容器也会共享存储,当 Kubernetes 挂载 Volume 到 Pod,本质上是将 Volume 挂载到 Pod 中的每一个 Container。
由此,Pod 是 Containers 的集合,共享存储和网络。Pod 具有独立的 IP 地址、主机名(Hostname),Pod 中的 Containers 共享这个 IP 地址、端口空间,并且可以通过 localhost 彼此查找。Pod 利用 Namespace 进行资源隔离,相当于一个独立的沙箱环境。不同的 Pod 之间的通信属于远程访问。
Pod 是虚拟的资源对象(进程),如果没有实体(物理机,物理网卡)与之对应,就无法直接对外提供服务访问。所以,Pod 如果想要对外提供服务,必须绑定物理主机的端口,让这个端口和 Pod 的端口进行映射,这样就可以通过物理主机的 IP + Port 进行数据包的转发。
kind: Pod
apiVersion: v1
metadata:
labels:
app: nginx-app
spec:
containers:
- name: nginx-container
image: nginx:latest
restartPolicy: Never
Pod 的本质是什么?
- 容器的本质是一个进程,是一个视图被隔离,资源被受限的进程。
- 容器镜像的本质是一个包含了容器运行时全部所需文件的集合。
- Kubernetes 的本质是是云时代的操作系统,它管理着这些进程(容器)。
实际上,一个生产应用往往需要多个进程之间(进程组)的协同才能完成工作,所以同一个进程组中的进程应该统一被原子性的进行调度、运行和销毁。
可见,Pod 的本质对应的就是一个进程组,是一个最终生产应用的逻辑集合。
Pod 的实现机制
像 Pod 这样一个东西,本身是一个逻辑概念。那在机器上,它究竟是怎么实现的呢?
核心就在于如何让一个 Pod 里的多个容器之间最高效的共享某些资源和数据。因为,容器之间原本是被 Linux Namespace 和 cgroups 隔开的,所以现在实际要解决的是怎么去打破这个隔离,然后共享某些事情和某些信息。这就是 Pod 的设计要解决的核心问题所在。
共享网络
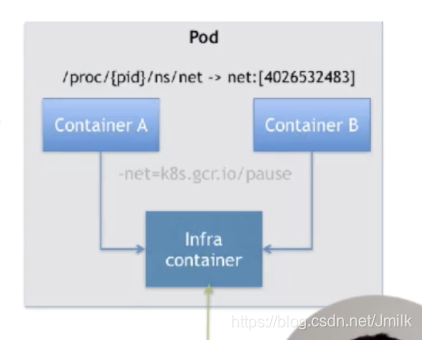
比如说现在有一个 Pod,其中包含了一个容器 A 和一个容器 B,它们两个就要共享 Network Namespace。在 Kubernetes 里的解法是这样的:它会在每个 Pod 里,额外起一个 Infra container 小容器来共享整个 Pod 的 Network Namespace。
Infra container 是一个非常小的镜像,大概 100~200KB 左右,是一个汇编语言写的、永远处于 “暂停” 状态的容器。由于有了这样一个 Infra container 之后,其他所有容器都会通过 Join Namespace 的方式加入到 Infra container 的 Network Namespace 中。
所以说一个 Pod 里面的所有容器,它们看到的网络视图是完全一样的。即:它们看到的网络设备、IP地址、Mac地址等等,跟网络相关的信息,其实全是一份,这一份都来自于 Pod 第一次创建的这个 Infra container。这就是 Pod 解决网络共享的一个解法。
在 Pod 里面,一定有一个 IP 地址,是这个 Pod 的 Network Namespace 对应的地址,也是这个 Infra container 的 IP 地址。所以大家看到的都是一份,而其他所有网络资源,都是一个 Pod 一份,并且被 Pod 中的所有容器共享。这就是 Pod 的网络实现方式。
由于需要有一个相当于说中间的容器存在,所以整个 Pod 里面,必然是 Infra container 第一个启动。并且整个 Pod 的生命周期是等同于 Infra container 的生命周期的,与容器 A 和 B 是无关的。这也是为什么在 Kubernetes 里面,它是允许去单独更新 Pod 里的某一个镜像的,即:做这个操作,整个 Pod 不会重建,也不会重启,这是非常重要的一个设计。
共享存储
Pod 共享存储就相对比较简单。
比如说现在有两个容器,一个是 Nginx,另外一个是非常普通的容器,在 Nginx 里放一些文件,让我能通过 Nginx 访问到。所以它需要去 share 这个目录。我 share 文件或者是 share 目录在 Pod 里面是非常简单的,实际上就是把 volume 变成了 Pod level。然后所有容器,就是所有同属于一个 Pod 的容器,他们共享所有的 volume。
例如有一个 volume 叫做 shared-data,它是属于 Pod level 的,所以在每一个容器里可以直接声明:要挂载 shared-data 这个 volume,只要你声明了你挂载这个 volume,你在容器里去看这个目录,实际上大家看到的就是同一份。这个就是 Kubernetes 通过 Pod 来给容器共享存储的一个做法。
所以,如果一个应用容器 App 写了日志,只要这个日志是写在一个 volume 中,只要声明挂载了同样的 volume,这个 volume 就可以立刻被另外一个 LogCollector 容器给看到。以上就是 Pod 实现存储的方式。
Pod 的生命周期
在 kubernetes 的官方文档中,对 Pod 的生命周期做出了解释。
和容器类似的,Pod 也是一个具有临时性(而不是长期存在)的实体。Pod 本身不具备自愈能力,在创建时,Pod 会被赋予一个 UUID,然后被调度到某个 Node,在终止(根据重启策略)或删除该 Pod 之前就一直运行在该 Node 上。注意,如果一个 Node 宕机了,那么调度到该 Node 的 Pods 也会在计划给定的超时期限后被删除。
Kubernetes 通过 Controller 来管理这些 “临时性” 的 Pod,当一个 Pod(由 UUID 定义)被删除后,Controller 会启动一个新的、几乎完全相同的 Pod 来进行替代。如果需要的话,新 Pod 的名字保持不变,但是其 UID 也会不同,表示并非是同一个 Pod。
对于 “普通” 的 Volume 而言,其生命周期与 Pod 一样,即:Volume 会伴随 Pod 的整个生命周期,Pod 删除或重建后,那么 Pod 运行期间产生的数据就会随之被删除。
Volume
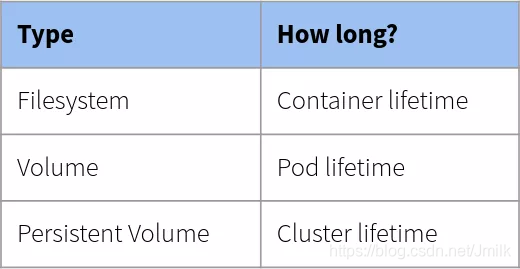
- Filesystem:在 Kubernetes 中,每个 Container 都可以在其自身的文件系统中执行读写操作。但是,Container 重启或删除后,写入该文件系统的数据将被破坏。
- Volume:是 Pod 可访问的文件系统目录,被同一个 Pod 中的 Containers 间共享。Volume 的生命周期与包含它的 Pod 一致。
- Persistent Volume(持久化卷):持久卷,则提供长期存储,只要 Kubernetes 集群存在,持久卷就存在。Pod 可声明使用持久卷读取、写入和读写。
Kubernetes Volume 支持多种存储插件,它可以支持本地的存储,可以支持分布式的存储,比如:Ceph、GlusterFS;也可以支持云存储,比如:阿里云的云盘等。
PV、PVC
PV、PVC Object 面向持久化存储。
PV(PersistentVolume):是 Kubernetes Cluster 中的一块存储空间,由管理员创建和维护,或者使用 Storage Class 动态扩展。与 Node 一样,属于集群资源。与 Volume 相似,但生命周期独立于 Pod。
PVC(PersistentVolumeClaim):是用户对存储的请求。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(e.g. 只读、读写)等信息,Kubernetes 会查找并提供满足条件的 PV。
有了 PersistentVolumeClaim,用户只需要告诉 Kubernetes 需要什么样的存储资源,而不必关心真正的空间从哪里分配、以及如何访问等底层细节信息。这些 Storage Provider 的底层信息交给管理员来处理,只有管理员才应该关心创建 PersistentVolume 的细节信息。
PV、PVC 的生命周期
PV 是群集中的资源,PVC 是对这些资源的请求,并且还充当对资源的检查。PV 和 PVC 之间的相互作用遵循以下生命周期:
-
Provisioning(供应准备):通过集群外的存储系统(e.g. CEPH)或者云平台(e.g. OpenStack Cinder)来提供存储持久化支持。
- Static(静态提供):集群管理员创建多个 PV,它们携带可供集群用户使用的真实存储的详细信息,然后再绑定到 PVC。
- Dynamic(动态提供):当管理员创建的 Static PV 都不匹配用户的 PVC 时,集群可能会尝试为 PVC 动态创建一个 PV,该操作需要基于 Storage Classes。即:PVC 必须请求一个 Classes(类别),并且集群管理员必须已经创建并配置好了该 Classes,才能动态提供 PV。
-
Binding(绑定):用户创建 PVC 并指定需要的资源和访问模式。在找到可用 PV 之前,PVC 会保持未绑定状态。
-
Using(使用):Pod 资源基于 PVC 的定义将选定的 PV 关联为 PVC,而后即可被容器所使用。对于支持多种访问模式的 PV 而言,用户需要额外指定访问模式。
-
Storage Object in Use Protection(保护):有用户希望删除仍处于某个 Pod 使用中的 PVC 或 PV 时,Kubernetes 不会立即予以移除、而是推迟到 PV 不再被任何 Pod 使用后方才执行删除操作。
-
Reclaiming(回收):PV 可以设置 2 种回收策略:
- Retain(保留)策略:删除 PVC 之后,kubernetes 不会自动删除 PV,而仅仅是将它置于 “Releases(释放)” 状态。此种状态的 PV 尚且不能被其他 PVC 申请所绑定,因为此前的申请生成的数据仍然存在,需要由管理员手动决定其后续处理方案。
- Delete(删除)策略:对于支持 Delete 策略的 CSI 来说、在 PVC 被删除后会直接移除 PV,同时移除 PV 相关的外部存储系统上的存储资产。Dynamic PV 的回收策略取决于相关 Storage Classes 的定义,默认为 Delete 策略。
Controller
Kubernetes 提供了多种 Controllers 来对 Pods 进行管理,包括:Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等,以满足不同的业务需求。这些控制器都运行在 Master 上。
在 Kuberentes 的 kubernetes/pkg/controller/ 目录中包含了官方提供的一些常见控制器,可以通过下面这个函数看到所有需要运行的控制器。这些 Controller 会随着 Controller Manager 的启动而运行,它们会监听集群状态的变更来调整集群中的 Kuberentes 对象的状态。
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers := map[string]InitFunc{}
controllers["endpoint"] = startEndpointController
controllers["replicationcontroller"] = startReplicationController
controllers["podgc"] = startPodGCController
controllers["resourcequota"] = startResourceQuotaController
controllers["namespace"] = startNamespaceController
controllers["serviceaccount"] = startServiceAccountController
controllers["garbagecollector"] = startGarbageCollectorController
controllers["daemonset"] = startDaemonSetController
controllers["job"] = startJobController
controllers["deployment"] = startDeploymentController
controllers["replicaset"] = startReplicaSetController
controllers["horizontalpodautoscaling"] = startHPAController
controllers["disruption"] = startDisruptionController
controllers["statefulset"] = startStatefulSetController
controllers["cronjob"] = startCronJobController
// ...
return controllers
}
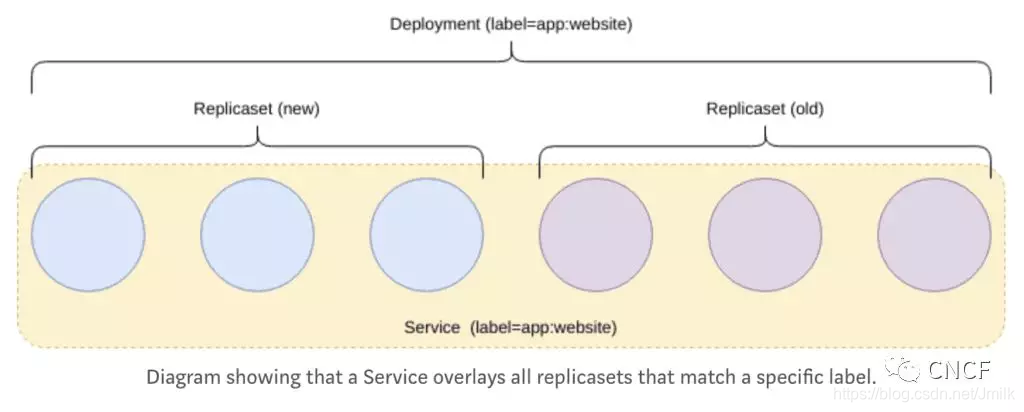
ReplicaSet(副本控制器)
负责 Pod 的多副本管理,保证 Pod 的副本数量永远与设定的数量一致,以此达到:“Pod 是脆弱的,但应用是健壮的” 的效果。在版本较新(1.18)的 ContrKubernetesller 中,建议使用 ReplicaSet 代替 ReplicationController 作为副本控制器。
注意:ReplicaSet 控制器是不支持滚动更新的,应用的需求在不断更新迭代,版本也在不断的升级,此时就需要应用 Deployment 控制器来支持滚动升级。所以 Deployment 和 ReplicaSet 通常会一起使用。使用 Deployment 的同时会自动创建 ReplicaSet,也就是说 Deployment 实际是通过 ReplicaSet 来管理 Pod 多副本的,通常不需要直接使用 ReplicaSet。
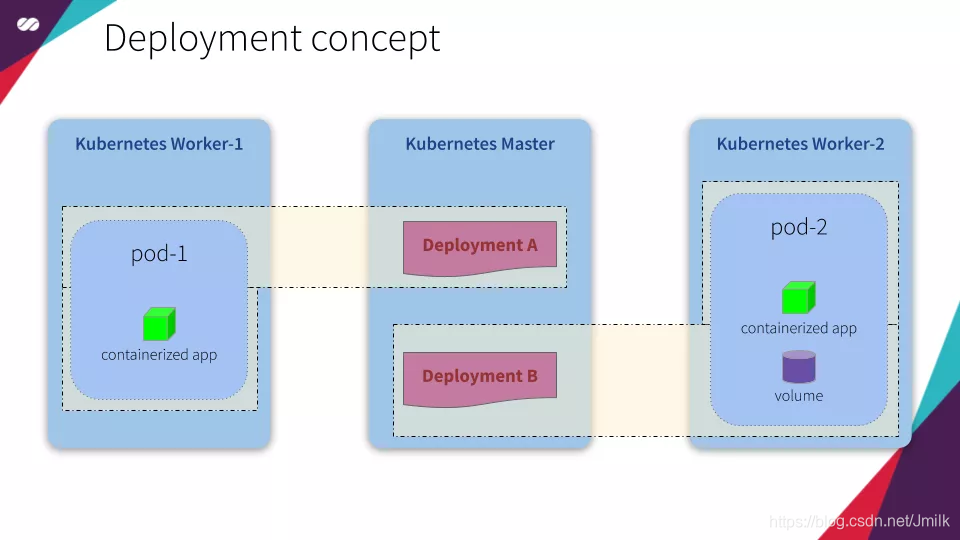
Deployment(部署控制器)
负责 Pod 的部署,并维护部署拓扑(e.g. 创建、监控、自修复 Pod),保证 Pod 按照期望的状态运行。
注意:不能使用 Deployment 部署有状态的服务。对于有状态的服务,使用 StatefulSet 控制器来进行部署。有状态服务,即:有实时的数据需要存储;无状态服务,即:没有实时的数据需要存储。
下面是一个 Deployment 的配置文件(nginx-deployment.yaml)。在正方形灰框内(从 template 开始)的是嵌入在 Deployment 里的 Pod 的设置,灰框上面的是部署(Deployment)的设置。当你运行这个配置文件时,它会创建一个 Deployment,同时也会创建嵌入在里面的 Pod。这就是为什么我们一般不需要单独的 Pod 的配置文件,因为已经把它嵌入在了 Deployment 里了。
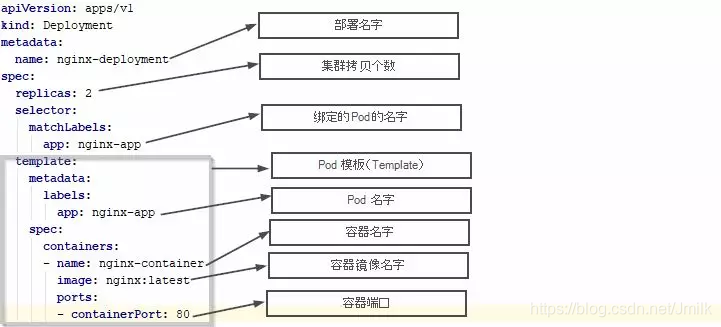
StatefuleSet(有状态部署控制器)
一般的,当 Pod 因为故障需要删除并重新启动时,它的名称会发生变化。为了解决有状态服务使用容器化部署的问题,StatefulSet 保证 Pod 重新建立后,Hostname 不会发生变化,Pod 就可以通过 Hostname 来关联持久化的数据。即:StatefuleSet 控制器可以保证 Pod 的所有副本的名称在其整个生命周期中是不变的。StatefuleSet 还可以保证 Pod 的副本按照固定的顺序启动、更新或者删除。
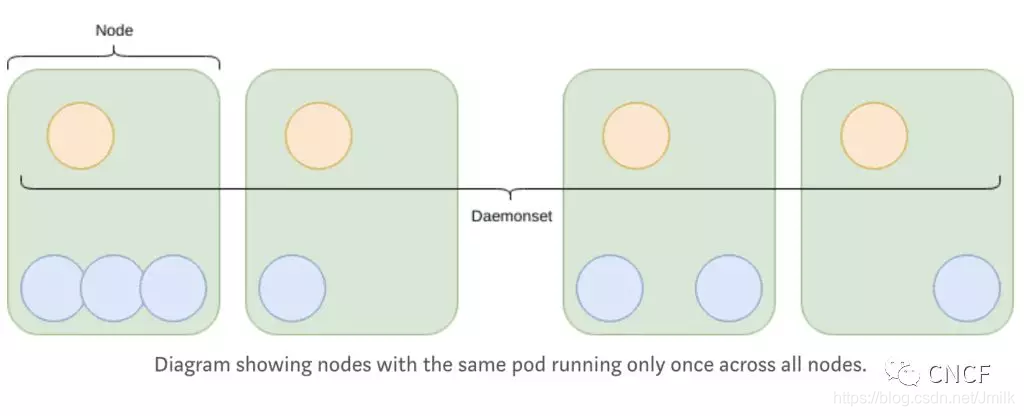
DaemonSet(守护进程控制器)
用于每个 Node 都运行且只运行一个 Pod 副本的场景,通常用于运行 daemon 守护服务进程。这对于在所有 Node 上运行诸如 Fluentd 之类的日志代理非常有用。当然,也可以通过使用污点(Taint)略过某些节点。
Job(任务控制器)
特殊的任务控制器,用于 App 运行结束就可以立即删除 Pod 的场景。
Service
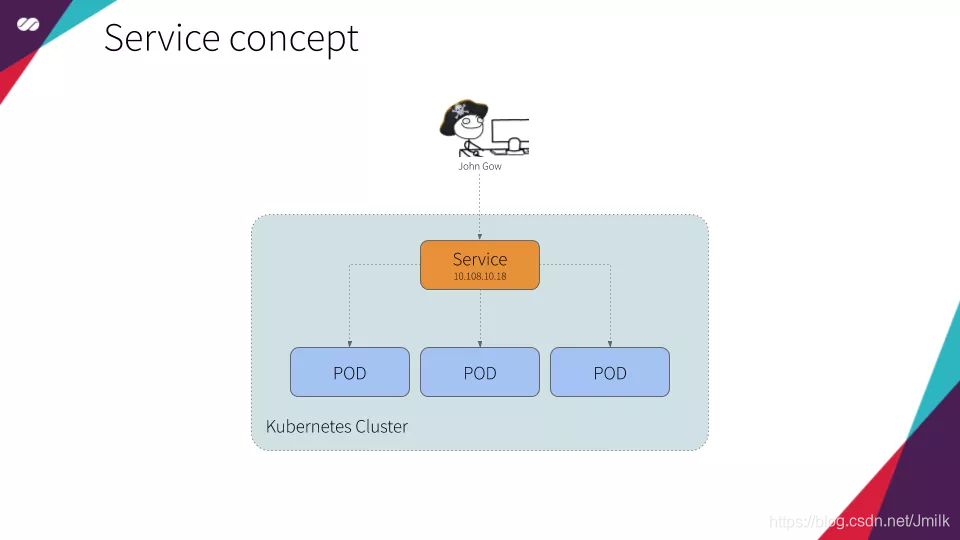
Pod 是一个进程,具有生命周期,宕机、版本更新时都会创建新的 Pod。这时候 Pod 的 IP 地址、Hostname 就会发生变化,无法直接使用 Nginx 等反向代理来进行负载均衡。
为此,Kubernetes 设计了 Service 这一抽血的概念,表示可以被 “他人” 所使用的服务。Service 用于定义外界访问一组特定 Pod 的方式:北向定义访问方式(ClusterIP、NodePort、LoadBalancer),南向通过 Label 和 Selectors 来匹配特定的 Pods,还可以为 Pods 提供了负载均衡。
客户端只需要访问 Service 的 IP,Kubernetess 则负责建立和维护 Service 与 Pod 的映射关系。无论后端 Pod 的 IP 地址如何变化,对客户端不会有任何影响,因为 Service 的 IP 没有变。
Service 和 Pod 之间可以直接进行通信,它们的通信属于局域网通信。Pod 把请求交给 Service 后,Service 使用 iptable、ipvs 等技术做数据包的分发(NAT、LB)。
Service 资源对象包括如下三部分:
- Pod IP:每个 Pod 特有的 IP 地址,Pod IP 无法通过外网访问,只能在 Service 下属的 Pods 进行访问。
- Node IP:每台物理主机的 IP 地址,如果有一个 Service 申请的 IP 类型为 Node IP,并且 Service 的 Port 为 30222,那么外部就可以通过 Node IP: 30222 来访问这个 Service 了。
- Cluster IP:虚拟 IP(VIP),如果 Service 申请的 IP 类型为 Cluster IP,那么该 Service 对象就是一个 VIP 的资源对象,而且这个 IP 是不变的。每个 Node 中都有 Kube-Proxy,监听所有 Pods。如果发现 Pod 的 IP 地址发生变化时,就动态更新(Etcd 中存储的)对应的 IP 地址映射关系。
selector:
app=x 选择一组订单的服务 pod ,创建一个 service;
通过 endpoints 存放一组 pod ip;
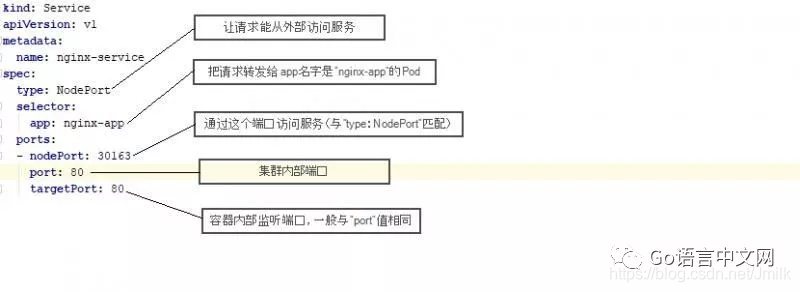
下面就是 Service 的配置文件 nginx-service.yaml。一般来说调用 Service 需要知道三个东西:IP、Port、Protocol,例如:http://10.0.2.1:80。但如果我们希望使用域名来寻址,就需要 DNS 服务了。下面 Service 通过 selector 来与 Pod 进行绑定,这里它把请求转发给 label app 为 nginx-app 的 Pod。而 NodePort 则表示给 Service 创建了一个外部可以访问的端口,这样在虚拟机上就可以直接访问服务了。
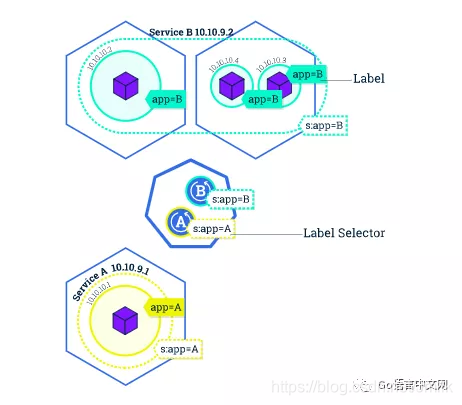
Label
Label 是一个非常核心的 kubernetes API 的概念,本质是一组键值对。这些 Label 可以被 Selector,也就是被选择器所查询到。与 SQL 中的 select 语句是非常相似的。通过 Label,kubernetes 的 API 层就可以对这些资源进行一个筛选。
每个 Kubernetes Object 都可以贴上多个 Label,下述的 app 就是一个用来标识 Pod 对象的 label。图里有两个 Pod,它们的 Label app 值分别为 A 和 B,其中 Pod B 是一个服务集群,而 Pod A 不是。Service 和 Deployment 都通过 Label Selector(标签选择器)来绑定与之匹配的 Pods。
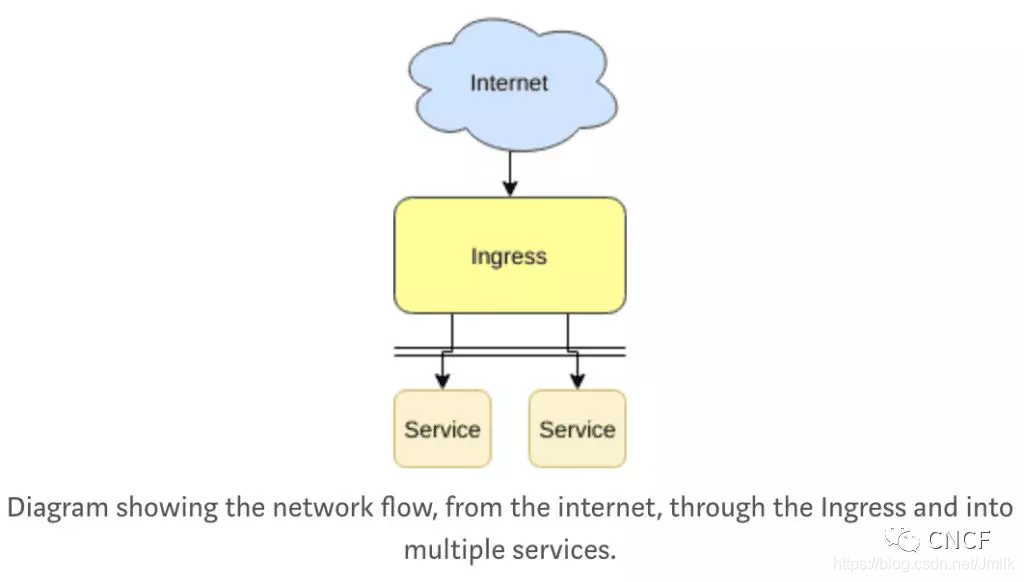
Ingress
在大多数组网场景中,Pods 和 Service 的 IP 地址只能在 Kubernetes Cluster 内部被访问,外网都是无法直接访问的。
Ingress 就可以通过一个 VIP 与 Kubernetes Cluster 内部进行通讯,一般会和 Service 进行配合使用,以提供外网访问入口。
它可以用于负载平衡、终止 TLS、提供外部可路由 URL 等等。Ingress 的本质也是 Kubernetes 的一个资源对象,然而,在大多数情况下 Ingress 对象需要有一个入口控制器(Ingress Controller),像 Nginx 等。
Namespace
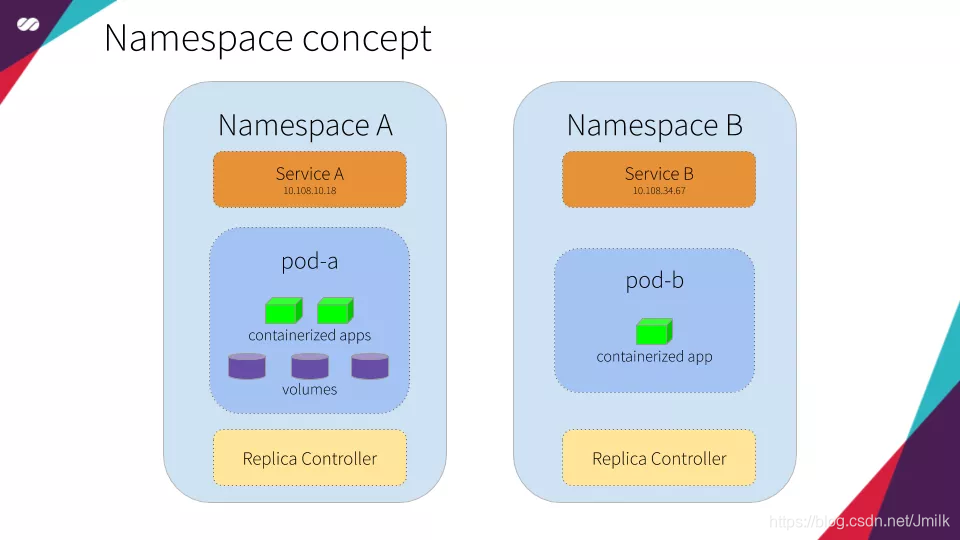
Namespace 提供了一种集群资源的划分方法,包括鉴权、资源管理等,用于 Kubernetes 实现多租户的效果。将一个物理的 Kubernetes Cluster 从逻辑上划分成多个虚拟的 Kubernetes Cluster,每个虚拟 Cluster 就是一个 Namespace,不同 Namespace 间的资源完全隔离。
- default Namespace:默认的 Namespace,如果创建任意资源时若不特别指定,就会将资源放到这个 namespace 下。
- kube-system Namespace:Kubernetes 自己创建的系统资源将放到这个 namespace 下。
- custom Namespace:租户自定义的 namespace。
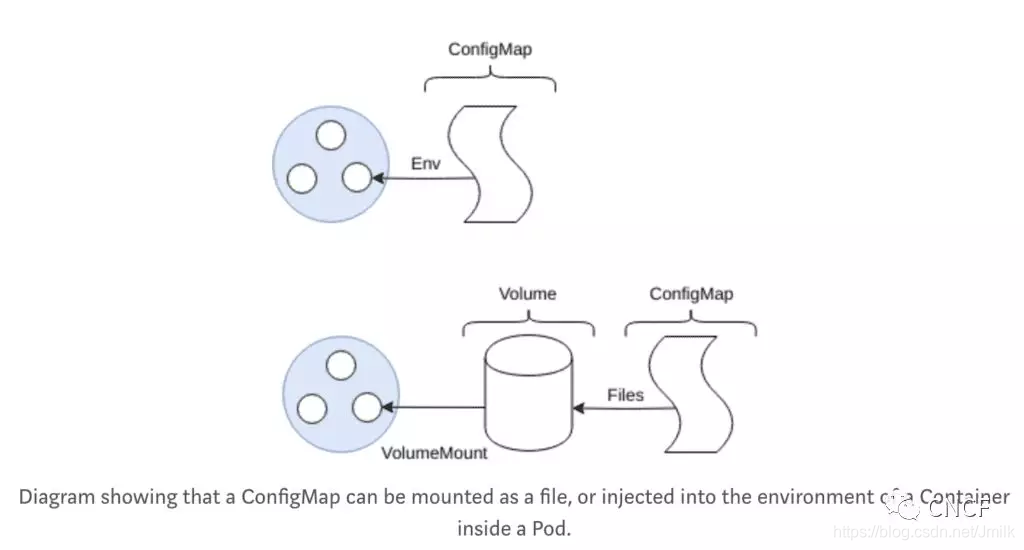
ConfigMap
设计良好的应用程序应该遵循 12 因素的应用程序声明,对于应用程序的配置,应该将配置存储在 “环境” 中。尽管现在常见的安全实践指出,在环境中存储配置可能会导致机密的意外泄漏,因为一些应用程序在失败时抛出了它们的环境,但是配置应该与构建的应用程序分开存储,因为每个环境都有配置更改。(开发、临时、生产)。
ConfigMap 允许将配置文件作为环境变量或文件系统挂载到 Pod 中,从而解决了这个问题。
容器设计模式
InitContainer

有了 InitContainer 之后就可以这样去描述:Pod 是一个自包含的,可以把这一个 Pod 在全世界任何一个 Kubernetes 上面都顺利启用起来。不用担心有没有分布式存储、Volume 是不是持久化的。
通过组合两个不同角色的容器,并且按照这样一些像 Init Container 这样一种编排方式,统一的去打包这样一个应用,把它用 Pod 来去做的非常典型的一个例子。像这样的一个概念,在 Kubernetes 里面就是一个非常经典的容器设计模式,叫做:“Sidecar”。
Sidecar
什么是 Sidecar?就是说其实在 Pod 里面,可以定义一些专门的容器,来执行主业务容器所需要的一些辅助工作,比如我们前面举的例子,其实就干了一个事儿,这个 Init Container,它就是一个 Sidecar,它只负责把镜像里的 WAR 包拷贝到共享目录里面,以便被 Tomcat 能够用起来。
其它有哪些操作呢?比如说:
-
原本需要在容器里面执行 SSH 需要干的一些事情,可以写脚本、一些前置的条件,其实都可以通过像 Init Container 或者另外像 Sidecar 的方式去解决;
-
还有一个典型例子就是日志收集,日志收集本身是一个进程,是一个小容器,那么就可以把它打包进 Pod 里面去做这个收集工作;
-
还有一个非常重要的东西就是 Debug 应用,实际上现在 Debug 整个应用都可以在应用 Pod 里面再次定义一个额外的小的 Container,它可以去 exec 应用 pod 的 namespace;
-
查看其他容器的工作状态,这也是它可以做的事情。不再需要去 SSH 登陆到容器里去看,只要把监控组件装到额外的小容器里面就可以了,然后把它作为一个 Sidecar 启动起来,跟主业务容器进行协作,所以同样业务监控也都可以通过 Sidecar 方式来去做。
这种做法一个非常明显的优势就是在于其实将辅助功能从我的业务容器解耦了,所以我就能够独立发布 Sidecar 容器,并且更重要的是这个能力是可以重用的,即同样的一个监控 Sidecar 或者日志 Sidecar,可以被全公司的人共用的。这就是设计模式的一个威力。
文章来源: is-cloud.blog.csdn.net,作者:范桂飓,版权归原作者所有,如需转载,请联系作者。
原文链接:is-cloud.blog.csdn.net/article/details/124708261

- 点赞
- 收藏
- 关注作者
评论(0)