【愚公系列】2022年05月 .NET架构班 066-分布式中间件 Elasticsearch搜索数据原理

【摘要】 前言 1.正排索引正排索引也称为"前向索引"。它是创建倒排索引的基础,具有以下字段。LocalId字段(表中简称"Lid"):表示一个文档的局部编号。WordId字段:表示文档分词后的编号,也可称为"索引词编号"。NHits字段:表示某个索引词在文档中出现的次数。HitList变长字段:表示某个索引词在文档中出现的位置,即相对于正文的偏移量。是以文档对象的唯一 ID 作为索引,以文档内容作...
前言
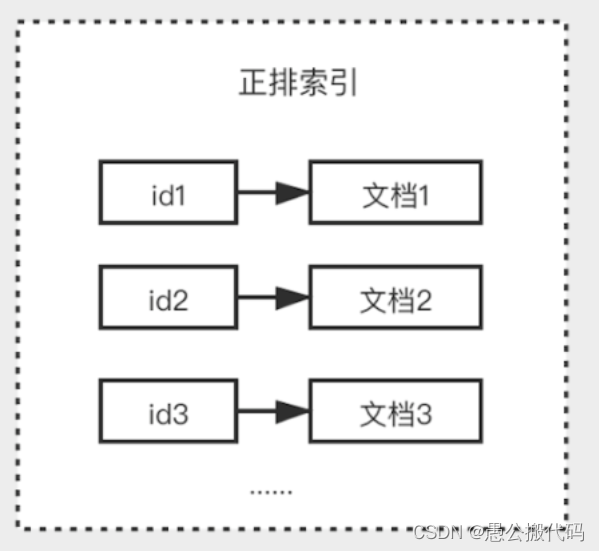
1.正排索引
正排索引也称为"前向索引"。它是创建倒排索引的基础,具有以下字段。
- LocalId字段(表中简称"Lid"):表示一个文档的局部编号。
- WordId字段:表示文档分词后的编号,也可称为"索引词编号"。
- NHits字段:表示某个索引词在文档中出现的次数。
- HitList变长字段:表示某个索引词在文档中出现的位置,即相对于正文的偏移量。
是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
2.倒排索引
倒排索引是一种以关键字和文档编号结合,并以关键字作为主键的索引结构。倒排索引分为两个部分。
- 第1个部分:由不同索引词(index term)组成的索引表,称为"词典"(lexicon)。其中保存了各种中文词汇,以及这些词汇的一些统计信息(例如出现频率nDocs),这些统计信息用于各种排名算法(Ranking Algorithm) [Salton 1989;Witten 1994]
- 第2个部分:由每个索引词出现过的文档集合,以及命中位置等信息构成,也称为"记录表"(posting file)或"记录列表"(posting list)。
指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。

一、Elasticsearch搜索数据原理
1.倒排索引的生成过程
文档内容:
productTitle:苏州街维亚大厦
productTitle:桔子酒店苏州街店
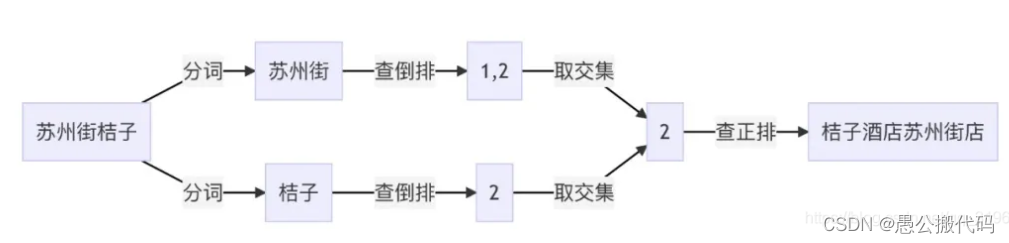
倒排索引生成过程:
对文档(苏州街维亚大厦 、桔子酒店苏州街店)进行分词,把分词作为索引对应文档ID建立对应关系建立成链表,就能构成倒排索引。图解如下:
| 单词 | 文档ID |
|---|---|
| 苏州街 | 1,2 |
| 维亚大厦 | 1 |
| 维亚 | 1 |
| 桔子 | 2 |
| 酒店 | 2 |
| 大厦 | 1 |
有了倒排索引,能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。
例如,如果需要在上述两个文档中查询 苏州街桔子 ,可以通过分词后 苏州街 查到 1、2,通过 桔子 查到 2,然后再进行取交取并等操作得到最终结果。
2.倒排索引的结构
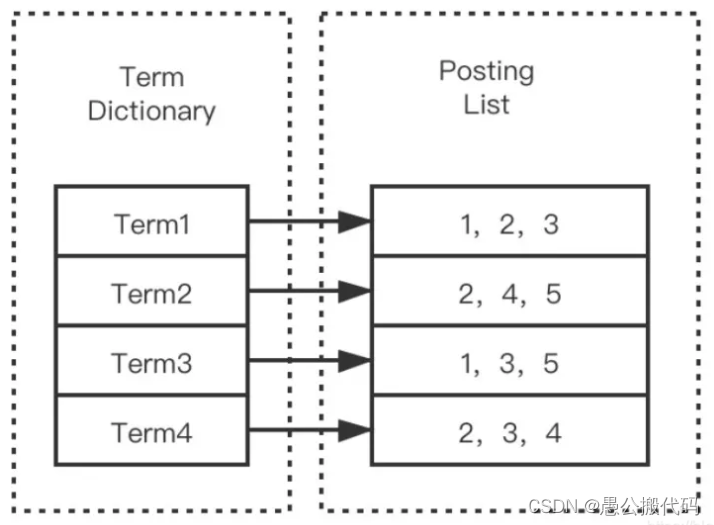
- Term Dictionary:存储单词和文档Id对应关系
- Postings List:记录表,记录文档Id
| 字段 | 说明 |
|---|---|
| 文档 id(DocId, Document Id) | 包含单词的所有文档唯一 id,用于去正排索引中查询原始数据。 |
| 词频(TF,Term Frequency) | 记录 Term 在每篇文档中出现的次数,用于后续相关性算分。 |
| 位置(Position) | 记录 Term 在每篇文档中的分词位置(多个),用于做词语搜索(Phrase Query)。 |
| 偏移(Offset) | 记录 Term 在每篇文档的开始和结束位置,用于高亮显示等。 |
3.倒排索引磁盘结构

4.倒排索引存储结构
segment 段存储结构
5.倒排索引term索引
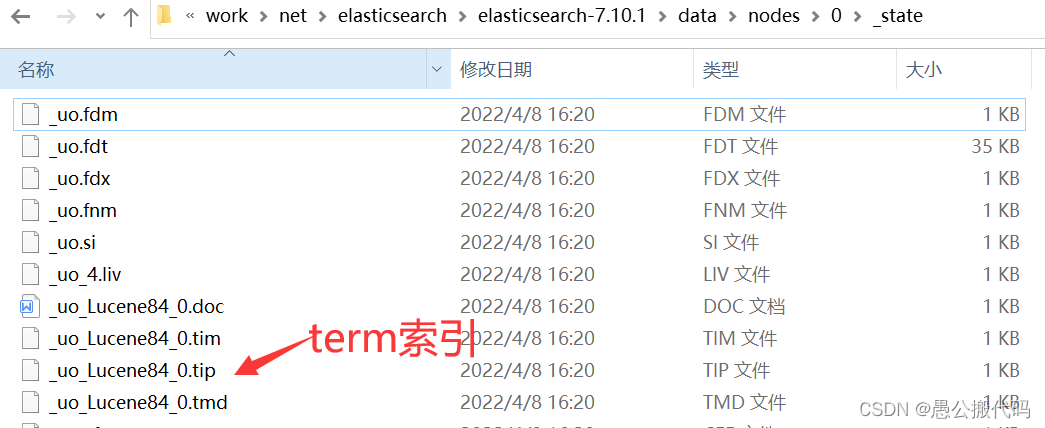
term用来存储分词id
6.完整搜索过程


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)