【进阶篇】全流程学习《20天掌握Pytorch实战》纪实 | Day04 | 时间序列建模流程范例

开源自由,知识无价~
@TOC
所用到的源代码及书籍+数据集以帮各位小伙伴下载放在文末,自取即可~
😁概览

一、 🎉准备数据
2020年发生的新冠肺炎疫情灾难给各国人民的生活造成了诸多方面的影响。
有的同学是收入上的,有的同学是感情上的,有的同学是心理上的,还有的同学是体重上的。
本文基于中国2020年3月之前的疫情数据,建立时间序列RNN模型,对中国的新冠肺炎疫情结束时间进行预测。
本次数据建模具有一定的可用性,与实际采样的数据有关联,可细细学习。
老规矩,导入时间库,以便后续打印训练时间
import os
import datetime
import importlib
import torchkeras
#打印时间
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
所用到的数据集取自tushare,获取该数据集的方法参考如下地址:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
查看绘制数据图
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
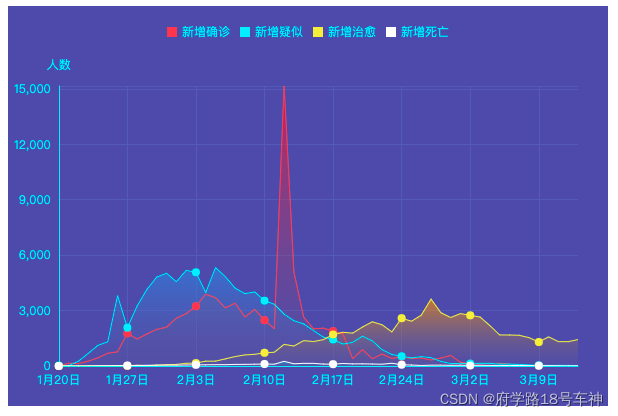
df = pd.read_csv("./data/covid-19.csv",sep = "\t")
df.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6))
plt.xticks(rotation=60);
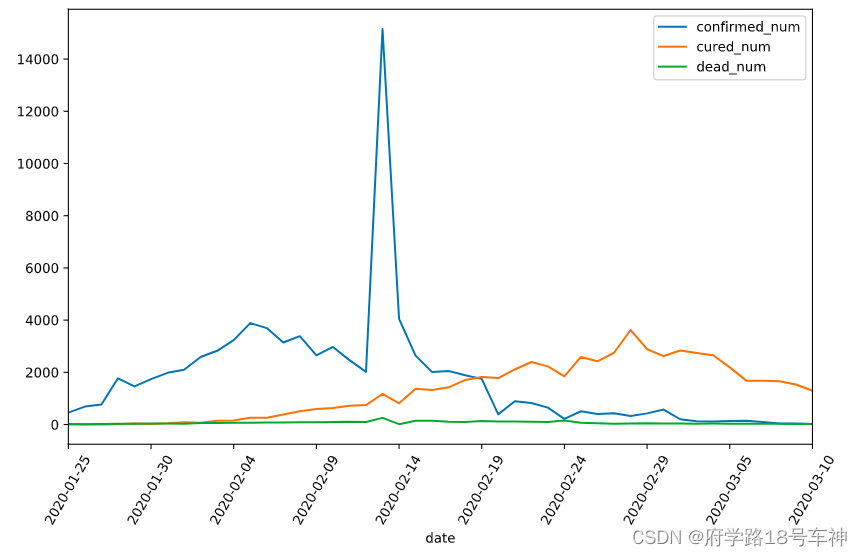
dfdata = df.set_index("date")
dfdiff = dfdata.diff(periods=1).dropna()
dfdiff = dfdiff.reset_index("date")
dfdiff.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6))
plt.xticks(rotation=60)
dfdiff = dfdiff.drop("date",axis = 1).astype("float32")
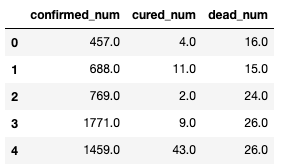
查看一下表头信息
print(dfdiff.head())
文档中使用torch的工具,以继承torch.utils.data.Dataset实现自定义时间序列数据集。
torch.utils.data.Dataset是一个抽象类,用户想要加载自定义的数据只需要继承这个类,并且覆写其中的两个方法即可:
__len__:实现len(dataset)返回整个数据集的大小。__getitem__:用来获取一些索引的数据,使dataset[i]返回数据集中第i个样本。
不覆写这两个方法会直接返回错误。
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
#用某日前8天窗口数据作为输入预测该日数据
WINDOW_SIZE = 8
class Covid19Dataset(Dataset):
def __len__(self):
return len(dfdiff) - WINDOW_SIZE
def __getitem__(self,i): # 数据、标签划分
x = dfdiff.loc[i:i+WINDOW_SIZE-1,:]
feature = torch.tensor(x.values)
y = dfdiff.loc[i+WINDOW_SIZE,:]
label = torch.tensor(y.values)
return (feature,label)
ds_train = Covid19Dataset()
#数据较小,可以将全部训练数据放入到一个batch中,提升性能
dl_train = DataLoader(ds_train,batch_size = 38)
二、 🎉定义模型
依旧是定义模型的老朋友了
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器进行封装。
此处选择第二种方式构建模型。
由于接下来使用类形式的训练循环,我们进一步将模型封装成torchkeras中的Model类来获得类似Keras中高阶模型接口的功能。
Model类实际上继承自nn.Module类。
模型构建:
import torch
from torch import nn
import importlib
import torchkeras
torch.random.seed()
class Block(nn.Module):
def __init__(self):
super(Block,self).__init__()
def forward(self,x,x_input):
x_out = torch.max((1+x)*x_input[:,-1,:],torch.tensor(0.0))
return x_out
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 3层lstm,长短时记忆网络
self.lstm = nn.LSTM(input_size = 3,hidden_size = 3,num_layers = 5,batch_first = True)
self.linear = nn.Linear(3,3)
self.block = Block()
def forward(self,x_input): # 前向
x = self.lstm(x_input)[0][:,-1,:]
x = self.linear(x)
y = self.block(x,x_input)
return y
net = Net()
model = torchkeras.Model(net)
print(model)
model.summary(input_shape=(8,3),input_dtype = torch.FloatTensor)
输出结果:
Model(
(net): Net(
(lstm): LSTM(3, 3, num_layers=5, batch_first=True)
(linear): Linear(in_features=3, out_features=3, bias=True)
(block): Block()
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
LSTM-1 [-1, 8, 3] 480
Linear-2 [-1, 3] 12
Block-3 [-1, 3] 0
================================================================
Total params: 492
Trainable params: 492
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.000092
Forward/backward pass size (MB): 0.000229
Params size (MB): 0.001877
Estimated Total Size (MB): 0.002197
----------------------------------------------------------------
Process finished with exit code 0
显示了上面构建的网络层信息,输出类别、参数、结果等,常规操作,经过之前几次的建模,感觉都是大同小异,调用函数也都很方便。
三、 🎉训练模型
同理,此处选用类形式训练循环。另外还有两种脚本形式训练循环,函数形式训练循环。
我们仿照Keras定义了一个高阶的模型接口Model,实现fit, validate,predict, summary方法,相当于用户自定义高阶API。
==注:循环神经网络调试较为困难,需要设置多个不同的学习率多次尝试,以取得较好的效果。==
def mspe(y_pred,y_true):
err_percent = (y_true - y_pred)**2/(torch.max(y_true**2,torch.tensor(1e-7)))
return torch.mean(err_percent)
model.compile(loss_func = mspe,optimizer = torch.optim.Adagrad(model.parameters(),lr = 0.1))
dfhistory = model.fit(100,dl_train,log_step_freq=10)
训练结果:
......
+-------+-------+
| epoch | loss |
+-------+-------+
| 89 | 0.142 |
+-------+-------+
================================================================================2022-04-20 09:36:29
+-------+-------+
| epoch | loss |
+-------+-------+
| 90 | 0.141 |
+-------+-------+
================================================================================2022-04-20 09:36:29
+-------+-------+
| epoch | loss |
+-------+-------+
| 91 | 0.141 |
+-------+-------+
================================================================================2022-04-20 09:36:29
+-------+-------+
| epoch | loss |
+-------+-------+
| 92 | 0.141 |
+-------+-------+
================================================================================2022-04-20 09:36:29
+-------+-------+
| epoch | loss |
+-------+-------+
| 93 | 0.141 |
+-------+-------+
================================================================================2022-04-20 09:36:29
+-------+-------+
| epoch | loss |
+-------+-------+
| 94 | 0.141 |
+-------+-------+
================================================================================2022-04-20 09:36:29
+-------+------+
| epoch | loss |
+-------+------+
| 95 | 0.14 |
+-------+------+
================================================================================2022-04-20 09:36:29
+-------+------+
| epoch | loss |
+-------+------+
| 96 | 0.14 |
+-------+------+
================================================================================2022-04-20 09:36:29
+-------+------+
| epoch | loss |
+-------+------+
| 97 | 0.14 |
+-------+------+
================================================================================2022-04-20 09:36:29
+-------+------+
| epoch | loss |
+-------+------+
| 98 | 0.14 |
+-------+------+
================================================================================2022-04-20 09:36:29
+-------+------+
| epoch | loss |
+-------+------+
| 99 | 0.14 |
+-------+------+
================================================================================2022-04-20 09:36:29
+-------+------+
| epoch | loss |
+-------+------+
| 100 | 0.14 |
+-------+------+
================================================================================2022-04-20 09:36:29
Finished Training...
Process finished with exit code 0
这样编写,简单高效。不解释
四、🎉评估模型
从文档来看,平常我们的检测指标这里用不上,准确率没有测出来,只检测了损失函数的情况。
评估模型一般要设置验证集或者测试集,由于此例数据较少,我们仅仅可视化损失函数在训练集上的迭代情况。
直接可视化loss:
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.title('Training '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric])
plt.show()
- 调用输出
plot_metric(dfhistory,"loss")
全叠一块儿了,单独出一个再
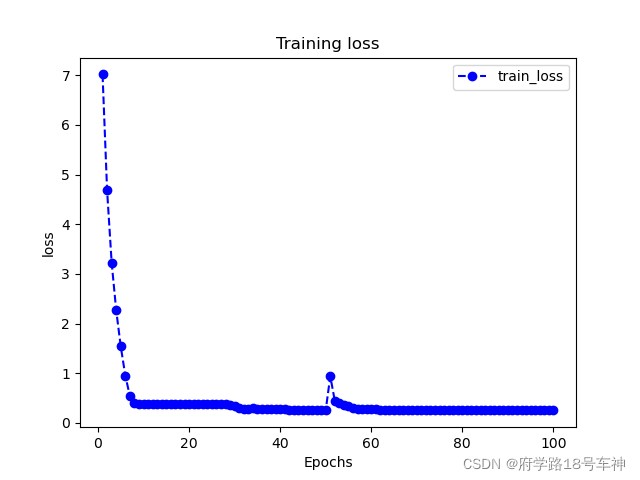
可以看出在50次左右会有一个尖峰,后面就变正常了,陷入了局部最优。
五、🎉使用模型
本示例的模型使用,此处我们使用模型预测疫情结束时间,即 新增确诊病例为0 的时间。
预测后面的数据:
#使用dfresult记录现有数据以及此后预测的疫情数据
dfresult = dfdiff[["confirmed_num","cured_num","dead_num"]].copy()
print(dfresult.tail())
结果为:
confirmed_num cured_num dead_num
41 143.0 1681.0 30.0
42 99.0 1678.0 28.0
43 44.0 1661.0 27.0
44 40.0 1535.0 22.0
45 19.0 1297.0 17.0
再预测后面200天的走势:
#预测此后200天的新增走势,将其结果添加到dfresult中
for i in range(200):
arr_input = torch.unsqueeze(torch.from_numpy(dfresult.values[-38:,:]),axis=0)
arr_predict = model.forward(arr_input)
dfpredict = pd.DataFrame(torch.floor(arr_predict).data.numpy(),
columns = dfresult.columns)
dfresult = dfresult.append(dfpredict,ignore_index=True)
print(dfresult.query("confirmed_num==0").head())
# 第50天开始新增确诊降为0,第45天对应3月10日,也就是5天后,即预计3月15日新增确诊降为0
# 注:该预测偏乐观
看一下结果:
confirmed_num cured_num dead_num
50 0.0 1043.0 5.0
51 0.0 999.0 4.0
52 0.0 957.0 3.0
53 0.0 917.0 2.0
54 0.0 878.0 1.0
再看下132天后的情况:
print(dfresult.query("cured_num==0").head())
# 第132天开始新增治愈降为0,第45天对应3月10日,也就是大概3个月后,即6月10日左右全部治愈。
# 注: 该预测偏悲观,并且存在问题,如果将每天新增治愈人数加起来,将超过累计确诊人数。
结果:
confirmed_num cured_num dead_num
119 0.0 0.0 0.0
120 0.0 0.0 0.0
121 0.0 0.0 0.0
122 0.0 0.0 0.0
123 0.0 0.0 0.0
六、🎉保存模型
也是同样的套路,不过好用就行。
推荐使用保存参数方式保存Pytorch模型。
# 保存模型参数
torch.save(model.net.state_dict(), "./data/model_parameter.pkl")
net_clone = Net()
net_clone.load_state_dict(torch.load("./data/model_parameter.pkl"))
model_clone = torchkeras.Model(net_clone)
model_clone.compile(loss_func = mspe)
# 评估模型
model_clone.evaluate(dl_train)
结果:
{'val_loss': 4.254558563232422}
说实话,想这种预测仅仅能作为一种参考,再理想情况下应该是可以实现完美的,但是现实生活中人与人的随机性太强了,不多说了,技术还是得慢慢学,存在即合理吧~
🤗往期纪实
| Date | 《20天掌握Pytorch实战》 |
|---|---|
| Day01 | 【进阶篇】全流程学习《20天掌握Pytorch实战》纪实 | Day01 | 结构化数据建模流程范例 |
| Day02 | 【进阶篇】全流程学习《20天掌握Pytorch实战》纪实| Day02 | 图片数据建模流程范例 |
| Day03 | 【进阶篇】全流程学习《20天掌握Pytorch实战》纪实 | Day03 | 文本数据建模流程范例 |
🥇总结
从数据建模的流程开始学习,按照准备数据、定义模型、训练模型、评估模型、使用模型、保存模型这六大常规思路,简单数据集入手,对于0基础的同学来说可能还是稍有难度,因此,本文中给出了大部分使用到的库的解释,同时给出了部分代码的注释,以便小伙伴的理解,仅供参考,如有错误,请留言指出,最后一句:开源万岁~
同时为原作者打Call:
如果本书对你有所帮助,想鼓励一下作者,记得给本项目加一颗星星star⭐️,并分享给你的朋友们喔😊!
地址在这里哦:https://github.com/lyhue1991/eat_pytorch_in_20_days
😊Reference
书籍源码在此:
链接:https://pan.baidu.com/s/1P3WRVTYMpv1DUiK-y9FG3A
提取码:yyds

- 点赞
- 收藏
- 关注作者
评论(0)