信息论与编码之信源编码详解

镇帖神图:
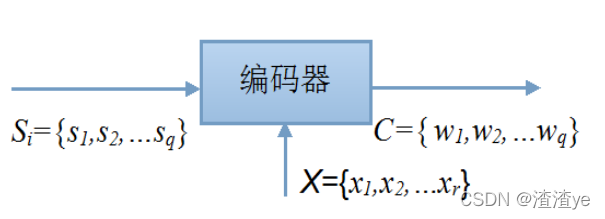
信源符号:Si={s1,s2,…sq} 码符号集:X={x1,x2,…xr}
码符号(码元):{xj,j=1,2,…r} 是码符号集中的元素,是适合信道传输的。
码字:编码器的输出符号序列wi(i=1,2,…q),与信源符号一一对应。
编码器的作用:是将信源符号集S中的符号si,i=1,2,…q(或者长为N的信源符号序列)变换成由基本符号xj(j=1,2,…r)组成的长为li的一一对应的输出符号序列。
要实现无失真编码,这种映射必须是一一对应的,可逆的。
码的N次扩展码:对离散无记忆信源的N次扩展信源进行编码得到N次扩展码。
设有信源集合S={s1,s2,…sq}经信源编码后,得到代码组C{w1,w2,…wq},wi与si(i=1,2,…q)是一一对应的。

信源S的N次扩展信源为:
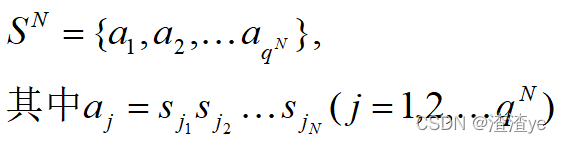
码的分类:
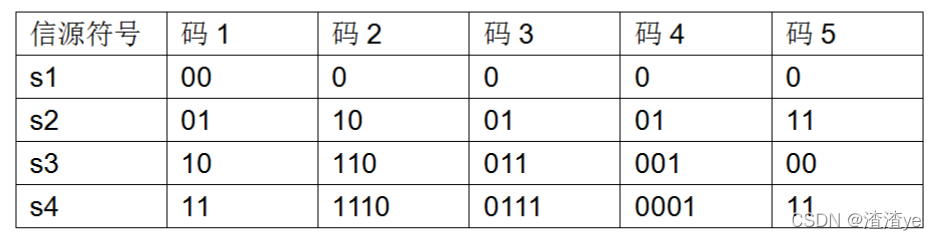
1.分组码与非分组码
• 分组码:将信源符号集中 的每个信源符号si映射成一个固定的码字wi 。• 非分组码:2.按码的长度不同,分为:
• 定长码: l i =l(i=1,2,…q)• 变长码:3.按码组中,码字是否有重复,分为:
• 奇异码 :一组码中 有相同的码字 。• 非奇异码 :一组码中无相同的码字。非奇异码是分组码能够正确译码的必要条件而非充分条件。
4.按每个码符号xi,i=1,2,…r所占的传输时间是否相同
• 同价码 :码符号集中,每个码符号x i 所占的传输时间相同。• 非同价码 :例:莫尔斯码是非同价码,其码符号:点(.)或划(_)所占的传输时间不相同。
信源编码的目的:
无失真信源码主要针对离散信源,连续信源在量化编码的过程中必然会有量化失真。
信源编码的目的:就是针对信源输出符号序列的统计特性,寻找一定的方法把信源输出符号序列变换为最短的码字序列。
因为信源概率分布的不均匀性和符号之间存在的相关性,使得信源存在冗余度,而实际上传送信源信息只需要传送信源极限熵大小的信息量。
去除冗余度的方法:
1)去除相关性,使编码后码序列中的各个码符号尽可能地相互独立,这一般利用对信源符号序列进行编码而不是对单个信源的符号进行编码而实现的。
2)使编码后各个码符号出现的概率尽可能地相等,而使概率分布均匀化,这可以通过概率匹配的方法,也就是使小概率消息对应长码,大概率消息对应短码。
定长编码的要求:
1.要实现无失真编码,所需的码必须是唯一可译码。
2.若定长编码时非奇异码,则它的任意有限长N次扩展码也一定是非奇异码,即等长非奇异码一定是唯一可译码。
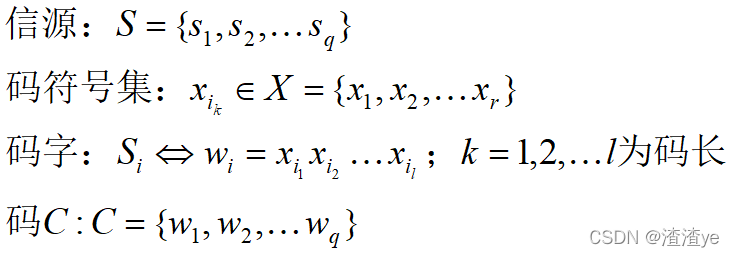
信源存在唯一可译定长码的条件:
若对一个简单信源进行定长编码,则必须满足:
其中,q是信源S的符号个数,r为码符号集中的码符号数,l为定长码码长。
例如:若q=4,进行二元等长编码,即r=2,
含义:rl表示l长的码符号所能提供的码字数,大于或等于信源符号数q时才能实现唯一可译码。
若要实现唯一可译的定长编码,则必须满足:

表明:只有当l长的码符号序列数rl不小于N次扩展信源符号个数qN时,才能存在定长唯一可译码。
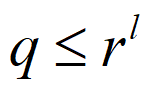

定长编码的编码速率和编码效率:
(编码速率):又称为编码信息率,设熵为H(S)的离散无记忆信源,若对信源的长为N的符号序列进行定长编码,设码字是从r个码符号集中选取l个码元构成,定义:

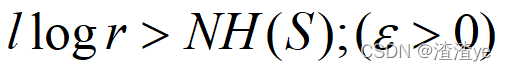
下期继续!
文章来源: blog.csdn.net,作者:渣渣ye,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/yyfloveqcw/article/details/123831774

- 点赞
- 收藏
- 关注作者
评论(0)