【愚公系列】2022年05月 .NET架构班 064-分布式中间件 Elasticsearch数据存储原理和结构

【摘要】 一、Elasticsearch数据存储原理ES底层是基于Lucene,最核心的概念就是Segment(段),每个段本身就是一个倒排索引。ES中的Index由多个段的集合和commit point(提交点)文件组成。提交点文件中有一个列表存放着所有已知的段。 1.数据存储过程如下步骤如下:不断将 Document 写入到 In-memory buffer (内存缓冲区)。当满足一定条件后内存...
一、Elasticsearch数据存储原理
ES底层是基于Lucene,最核心的概念就是Segment(段),每个段本身就是一个倒排索引。
ES中的Index由多个段的集合和commit point(提交点)文件组成。
提交点文件中有一个列表存放着所有已知的段。
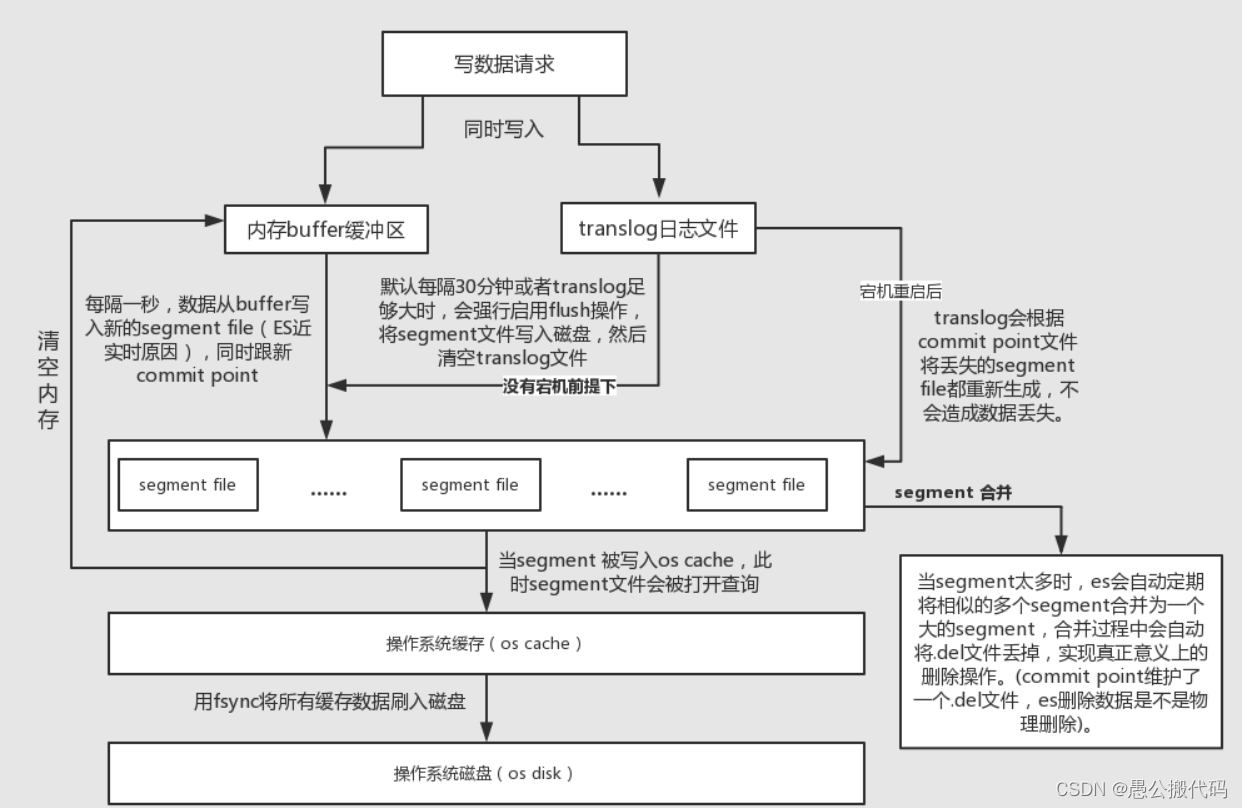
1.数据存储过程如下
步骤如下:
- 不断将 Document 写入到 In-memory buffer (内存缓冲区)。
- 当满足一定条件后内存缓冲区中的 Documents 刷新到 高速缓存(cache)。
- 生成新的 segment ,这个 segment 还在 cache 中。
- 这时候还没有 commit ,但是已经可以被读取了。
说明:
数据从 buffer 到 cache 的过程是定期每秒刷新一次。所以新写入的Document 最慢 1 秒就可以在 cache 中被搜索到。而 Document 从 buffer 到 cache 的过程叫做 ?refresh 。一般是 1 秒刷新一次,不需要进行额外修改。
2.数据写入防止丢失
步骤如下:
- Document 不断写入到 In-memory buffer,此时也会追加 translog。
- 当 buffer 中的数据每秒 refresh 到 cache 中时,translog 并没有进入到刷新到磁盘,是持续追加的。
- translog 每隔 5s 会 fsync 到磁盘。
- translog 会继续累加变得越来越大,当 translog 大到一定程度或者每隔一段时间,会执行 flush。
flush 操作会分为以下几步执行:
- buffer 被清空。
- 记录 commit point。
- cache 内的 segment 被 fsync 刷新到磁盘。
- translog 被删除。
说明:
translog 每 5s 刷新一次磁盘,所以故障重启,可能会丢失 5s 的数据。
translog 执行 flush 操作,默认 30 分钟一次,或者 translog 太大 (2G)也会执行。
2.数据存储过程完整结构图如下
二、Elasticsearch数据设计结构
- Dcoument:数据在ES中的表现形式,类似json数据格式。
- Index(数据库):Dcoument存储到这里
- Index(查询):从Index进行查询

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)