CANN5.0如何实现resnet50训练性能翻倍

众所周知,MLPerf是当今权威性最大、影响力最广的国际AI性能基准测试,相当于AI技术领域的「晴雨表」。今年5月的MLperf training 1.0,鹏城实验室基于华为昇腾AI基础软硬件平台鹏城云脑II(采用搭载鲲鹏、昇腾处理器的Atlas 900集群,算力为1000P(每秒百亿亿次计算)),实现了在昇腾硬件基本不变的情况下,通过软件和系统级优化,「Resnet50单卡训练的性能」,在一年的时间内提高了82%,「Resnet50集群训练的性能」在一年的时间内提高了240%,时间开销仅为0.65min。
那么,在硬件不变情况下,CANN从3.0升级到5.0,单server下,Resnet50训练性能又是什么表现呢?
再看性能之前呢,我们先简单回顾下Resnet50训练网络。
Resnet是残差网络(Residual Network)的缩写,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分;
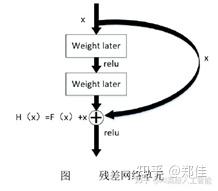
Resnet50 网络中包含了 49 个卷积层、一个全连接层。可以分成七个部分,第一部分不包含残差块,主要对输入224*224*3大小的图片进行卷积、正则化、激活函数、最大池化的计算。第二、三、四、五部分结构都包含了残差块,每个残差差 块 都 有 三 层 卷 积 , 那 网 络 总 共 有1+3×(3+4+6+3)=49个卷积层,加上最后的全连接层总共是 50 层,这也是Resnet50 名称的由来。它有24M的参数量,4.1GFLOPs计算量,如果在ImageNet的128万张图片数据集下训练,Resnet50训练90个Epoch,也就是90*128万这么大的数据集,普通的GPU耗时在3小时以上时间,这对快速迭代算法是不可忍受的,计算资源昂贵,训练性能提升就是在节约成本;
然而,在Ascend910硬件不变情况下,CANN从3.0升级到5.0,单server,Resnet50训练吞吐性能翻倍,90个Epoch的端到端耗时降低至80min以内,为广大开发者节约一半训练时间!那CANN是怎么做到的呢?现在就带大家去揭开这性能翻倍的神秘面纱。
首先呢,给出一个原则:无论在什么硬件平台下去优化Resnet50训练性能,保证同等计算过程和计算量,性能提升一定来源于如何最大效率的利用Host和device的资源,这里的Host就是指Host-CPU,device资源包括张量计算核心(如GPU的tensor core /google-TPU的matrix/HW-NPU的cube,这是AI芯片计算能力的核心),还有向量计算核心、图像处理加速模块、集体通信模块、互联模块、多级Cache等;这里的最大效率其实就是最优的异步计算并行度,举一个例子,你有100斤面要蒸馒头,而你只有一只能装10斤面的和面盆、一个炉子、一个一次能装10斤馒头的蒸锅,如何以最快的速度完成蒸馒头?我想大家都知道答案,就是先和面10斤,拿到炉子上蒸,然后立即去和面,炉子上在蒸馒头,同时和面,如此反复直到结束,这就是最简单的并行模型;而在Resnet50训练过程中,这样的硬件并行被设计的更为复杂,当然这一定需要算法设计和软件实现,这也是CANN5.0实现性能翻倍的关键所在。
讲到这里,Resnet50训练性能优化的关键技术点该登场了;
first,算子深度融合技术,将正向的卷积层+BN层+激活层进行了深度融合,使得在CUBE核心和Vector核心上的并行度进一步提升,释放CUBE超强算力;当然,这个优化能力是来自于Ascend910强大的CUBE核心,就相当于你有一个5层蒸锅,一次就可以蒸50斤馒头,而知道蒸锅的第一层温度最高,而算子深度融合优化呢,就是把蒸馒头过程中利用这5层的温差,在保证馒头蒸熟的前提下,现将第一个10斤馒头放到第一层,再来10斤就把原来的放到第二层,新的放到第一层,如此循环,保证CUBE“蒸锅”的利用效率;当然这种算子深度融合在反向的卷积、BN和激活层是一样的,只是反向计算过程更为复杂;
second,指令重排技术,CUBE的计算过程大致包含了:数据搬进、CUBE核心计算、vector核心计算、scale计算、数据搬出,这里个过程和算子实现过程强绑定外,还和指令排序执行强相关,让这几个计算过程默契的并行起来,离不开指令重排技术。还是蒸馒头的例子,假设炉子上的火是不均匀的,那么每一层上的10斤馒头在蒸煮过程中受热也不是均匀的,那就需要加一个旋转器,使得这一层的各个方向上的馒头以一种规则旋转,使这一层馒头更快速的达成均匀的某个成熟度,再转移到下一层继续蒸煮;指令重排技术在CPU上已经相当成熟,针对各种不一样的AI芯片架构,指令重排有着巨大差异;对于Ascend910硬件架构,在CANN5.0软件版本上,吸收了不同类型网络算子的重排场景,使得Resnet50中正反向卷积、正则化和激活层的算子性能显著提升;
last,Ascend调优引擎,针对Ascend系列AI芯片的复杂逻辑,获取算子和整网的最优性能依赖硬件执行计算的并行流水性能(这里的流水包括:多级Cache的数据搬运、计算核心的能力切分等);面对多种类算子的多shape场景,就像蒸馒头过程中,水温和力气大小决定了和面时间、习惯决定了揉馒头大小,放置馒头位置也存在随机性,旋转器转速不定,这都影响你蒸馒头过程的时间;如何在已知的人力、水、蒸锅、旋转器炉火等资源下,快速达成100斤的馒头蒸煮,不需要各种尝试,不需要各种调整,使用Ascend调优引擎,使用AI的方法来获取最优的算子和网络的执行参数配置,极大提升硬件并行流水,更加充分释放CUBE算力。
说到这里呢,我想大家不仅对蒸馒头有了新的认知,对Ascend910和CANN5.0也有一定程度的理解,那么接下来我就从抽象角度来和大家说说如何在CANN5.0上提升训练性能;
总结
1、 匹配好Host和device的计算时间,使得Host和Device能够极大并行,不至于相互等待;
2、 多P训练下,使用HCCL协调好多P的梯度更新与计算的并行,让梯度更新隐藏到计算流水中,当然CANN5.0是提供了HCCL自动寻优切分的工具的;
3、 尽可能的让CUBE和Vector算子融合,让CUBE和Vector的流水并行起来,CANN5.0提供了广泛的融合方案,也有可以直接引用的npu_ops.api;
4、 使用Ascend调优引擎,把你的训练模型中算子各个参数调优至极致;
5、 使用混合精度进行训练;

- 点赞
- 收藏
- 关注作者
评论(0)