机器学习之Python有关numpy创建ndarray,Matplotlib库,绘制出抛物线曲线图,panda读取csv文件。

【摘要】 根据示例创建ndarray,并按要求完成操作 1.按要求进行切片操作 2.将数组中的每个元素乘2后,按行和按列方式分别计算其最大值,打印输出结果 利用Matplotlib库,绘制出抛物线曲线图 1.panda读取csv文件1并统计每个积分区间(每5分)人数分布,绘制图形 1.读取 CSV文件生成DataFrame 2. 数据预处理 3. 对数据进行离散化处理 4. 按积分分割区间进行分组统...
根据示例创建ndarray,并按要求完成操作

1.按要求进行切片操作
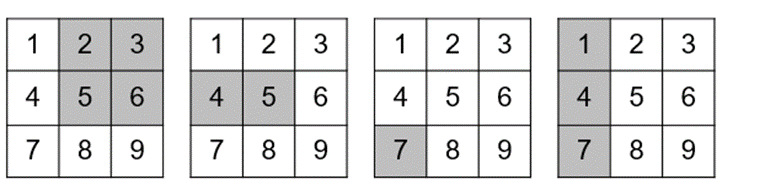
import numpy as np
arr1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr1[:2, 1:])
print(arr1[1:2, 0:2])
print(arr1[2:, 0:1])
print(arr1[:, 0:1])
# 将数组中的每个元素乘2后,按行和按列方式分别计算其最大值,打印输出结果
arr2 = arr1*2
print('按行方式分别计算其最大值:', arr2.max(1))
print('按列方式分别计算其最大值:', arr2.max(0))
2.将数组中的每个元素乘2后,按行和按列方式分别计算其最大值,打印输出结果
arr2 = arr1*2
print('按行方式分别计算其最大值:', arr2.max(1))
print('按列方式分别计算其最大值:', arr2.max(0))
利用Matplotlib库,绘制出抛物线曲线图
1.线为红色圆型点线图
2.横坐标取值范围:[-10, 10],绘制点数50
3.坐标轴说明(x轴:x tick,y軕:voltage)
4.图标题为抛物线示意图。
import matplotlib.pyplot as plt
import numpy as np
x = np. linspace(-10, 10, 50) # x坐标采样点生成,[-10,10]区间,50个点
y = []
for i in x:
a = i**2
y.append(a)
plt.plot(x, y, 'ro--') # 控制图形格式为红色圆形的虚线
plt.title("抛物线示意图") # 设置图表标题
plt.xlabel("x tick") # 设置x坐标轴标签
plt.ylabel("voltage") # 设置y坐标轴标签
plt.rcParams['font.sans-serif'] = ['Kaiti'] # 用来正常显示中文(黑体)常用字体包括: Kaiti-楷体; FangSong-仿宋; Microsoft YaHei-微软雅黑
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.savefig("test", dpi=300) # 保存图表
plt.show()
1.panda读取csv文件1并统计每个积分区间(每5分)人数分布,绘制图形
1.读取 CSV文件生成DataFrame
df = pd.read_csv('D:/luohu3.csv')
print(df)
2. 数据预处理
data = df.dropna(0) # 删除所有包含空值的行或列
print(data.info())
3. 对数据进行离散化处理
通过describe()查看最大值最小值,来确定区间
x = data["积分分值"]
print(data.describe()) # 查看最大值与最小值
bins = np.arange(90, 126, 5)
score_bins = pd.cut(x, bins) # 对数据进行离散化处理
print(score_bins)
4. 按积分分割区间进行分组统计
df1 = data.groupby(score_bins)["积分分值"].count()
print(df1)
5. 绘制图形
rot=0使横坐标的数据横过来
df1.plot(kind="bar", rot=0)
plt.rcParams['font.sans-serif'] = ['Kaiti'] # 用来正常显示中文(黑体)常用字体包括: Kaiti-楷体; FangSong-仿宋; Microsoft YaHei-微软雅黑
plt.rcParams['axes.unicode_minus'] = False # 显示负号
plt.show()
完整代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取 CSV文件生成DataFrame
df = pd.read_csv('D:/luohu3.csv')
print(df)
print(df.info()) # 获取 DataFrame 的摘要
print(df.head()) # 根据位置返回对象的前n行信息(默认值为5) ,用于快速测试数据集
print(df.describe()) # 生成描述性统计数据,总结数据集分布的集中趋势,分散和形状,不包括 NaN值。
# 数据预处理
data = df.dropna(0) # 删除所有包含空值的行或列
print(data.info())
# data = df.drop_duplicates()
# print(data.info())
x = data["积分分值"]
print(data.describe()) # 查看最大值与最小值
bins = np.arange(90, 126, 5)
score_bins = pd.cut(x, bins) # 对数据进行离散化处理
print(score_bins)
# 按积分分割区间进行分组统计
df1 = data.groupby(score_bins)["积分分值"].count()
print(df1)
# 绘制图形
df1.plot(kind="bar", rot=0)
plt.rcParams['font.sans-serif'] = ['Kaiti'] # 用来正常显示中文(黑体)常用字体包括: Kaiti-楷体; FangSong-仿宋; Microsoft YaHei-微软雅黑
plt.rcParams['axes.unicode_minus'] = False
plt.show()

2.按照"单位名称"分组统计每个单位的人数信息,将人数排名前10的单位和人数用柱状图表示出来。
前面几步和上一个基本相同,就不多说了。
特殊的就三步:
1.按单位名称进行分组统计
df1 = data.groupby(data['单位名称'])["单位名称"].count()
2.分组结果排序
df2 = df1.sort_values(ascending=False)
3.取排序结果的前10个数据,切片
df3 = df2[0:10]
完整代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取 CSV文件生成DataFrame
df = pd.read_csv('D:/luohu3.csv')
# print(df)
print(df.info()) # 获取 DataFrame 的摘要
# print(df.head()) # 根据位置返回对象的前n行信息(默认值为5) ,用于快速测试数据集
# print(df.describe()) # 生成描述性统计数据,总结数据集分布的集中趋势,分散和形状,不包括 NaN值。
# 数据预处理
data = df.dropna(0) # 删除所有包含空值的行或列
print(data.info())
# data = df.drop_duplicates()
# print(data.info())
df1 = data.groupby(data['单位名称'])["单位名称"].count() # 按单位名称进行分组统计
print(df1)
df2 = df1.sort_values(ascending=False) # 分组结果排序
print(df2)
df3 = df2[0:10] # 取排序结果的前10个数据
# 绘制图表
df3.plot(kind="bar", rot=0)
plt.rcParams['font.sans-serif'] = ['Kaiti'] # 用来正常显示中文(黑体)常用字体包括: Kaiti-楷体; FangSong-仿宋; Microsoft YaHei-微软雅黑
plt.rcParams['axes.unicode_minus'] = False
plt.show()

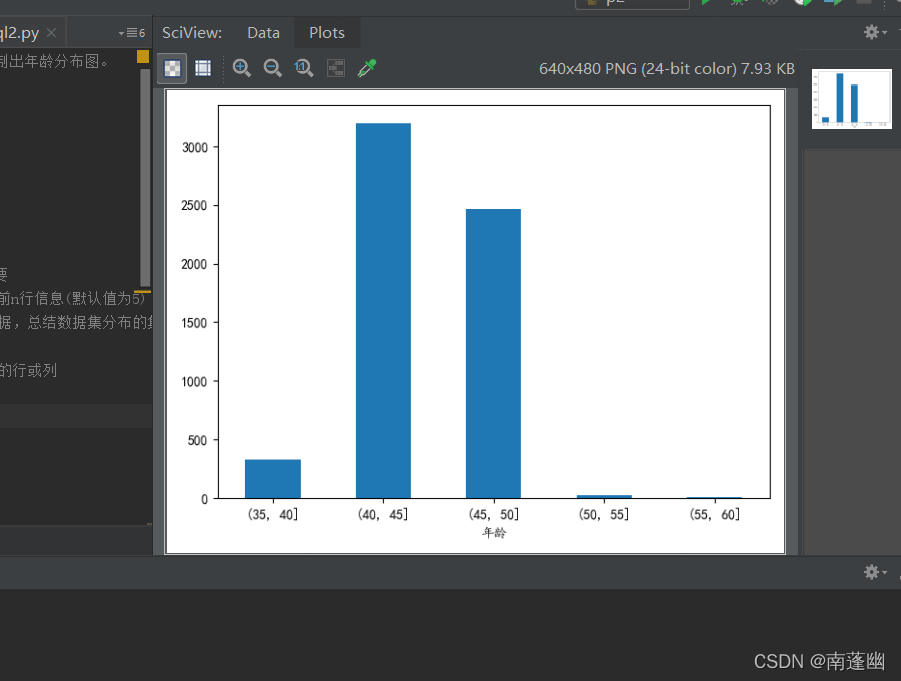
3.统计年龄分布情况(5岁的间隔统计),绘制出年龄分布图。
这个和第一个非常相似,难点在于需要将出生年月转化为年龄。
data = data.copy()
data['年龄'] = [dt.datetime.today().year - i.year for i in pd.to_datetime(data["出生年月"])]
如果不添加data.copy()会报错
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value instead
完整代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import datetime as dt
# 读取 CSV文件生成DataFrame
df = pd.read_csv('D:/luohu3.csv')
print(df)
print(df.info()) # 获取 DataFrame 的摘要
print(df.head()) # 根据位置返回对象的前n行信息(默认值为5) ,用于快速测试数据集
print(df.describe()) # 生成描述性统计数据,总结数据集分布的集中趋势,分散和形状,不包括 NaN值。
# 数据预处理
data = df.dropna(0) # 删除所有包含空值的行或列
print(data.info())
# data = df.drop_duplicates()
# print(data.info())
# 获取年龄数据
data = data.copy()
data['年龄'] = [dt.datetime.today().year - i.year for i in pd.to_datetime(data["出生年月"])] # 日期数据如何处理
x = data["年龄"]
# 设置统计分值段范围
print(data.describe()) # 查看最大值与最小值
bins = np.arange(35, 65, 5)
time_bins = pd.cut(x, bins) # 对数据进行离散化处理
print(time_bins)
# 按积分分割区间进行分组统计
df1 = data.groupby(time_bins)["年龄"].count()
print(df1)
# 绘制图形
df1.plot(kind="bar", rot=0)
plt.rcParams['font.sans-serif'] = ['Kaiti'] # 用来正常显示中文(黑体)常用字体包括: Kaiti-楷体; FangSong-仿宋; Microsoft YaHei-微软雅黑
plt.rcParams['axes.unicode_minus'] = False
plt.show()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)