推荐算法 R实例

R语言:recommenderlab包的总结与应用案例
1 框架包介绍
- 推荐系统:recommenderlab包整体思路
recommenderlab包提供了一个可以用评分数据和0-1数据来发展和测试推荐算法的框架。
它提供了几种基础算法,并可利用注册机制允许用户使用自己的算法
recommender包的数据类型采用S4类构造。
(1)评分矩阵数据接口:使用抽象的raringMatrix为评分数据提供接口。
raringMatrix采用了很多类似矩阵对象的操作,如 dim(),dimnames() ,rowCounts() ,colMeans() ,rowMeans(),colSums(),rowMeans();
也增加了一些特别的操作方法,如sample(),用于从用户(即,行)中抽样,image()可以生成像素图。
raringMatrix的两种具体运用是realRatingMatrix和binaryRatingMatrix,分别对应评分矩阵的不同情况。
其中realRatingMatrix使用的是真实值的评分矩阵,存储在由Matrix包定义的稀疏矩阵(spare matrix)格式中;
binaryRatingMatrix使用的是0-1评分矩阵,存储在由arule包定义的itemMatrix
(2)存储推荐模型并基于模型进行推荐。类Recommender使用数据结构来存储推荐模型。
创建方法是:Rencommender(data=ratingMatrix,method,parameter=NULL),返回一个Rencommender对象object,可以用来做top-N推荐的预测:
predict(object,newdata,n,type=c('topNlist,ratings'),…)
(3)使用者可以利用registry包提供的注册机制自定义自己的推荐算法。
注册机制调用recommenderRegistry并存贮推荐算法的名字和简短描述。
(4)评价推荐算法的表现:recommender包提供了evaluationScheme类的对象用于创建并保存评价计划。
创建函数如下: evaluatiomScheme(data,method,train,k,given) 这里的方法可以采用简单划分、自助法抽样、k-折交叉验证等。
接下来可以使用函数evalute()使用评价计划的多个评价算法的表现。
实例分析
2 数据预览
library(recommenderlab)
library(ggplot2)
library(reshape2)
#install.packages(“reshape”)
library(reshape)
Sys.setlocale(category=“LC_ALL”,locale=“Chinese”)
#设置好工程路径后,可用读入数据,注意数据的格式,第一列是user id,第二列是item id,第三列是rating,第四列是时间戳,
#时间戳这里用不到,可去掉。

ml100k <- read.table(“u.data”,header=FALSE, stringsAsFactors = T)
head(ml100k)
ml100k <- ml100k[, -4]
可以简单看下rating的分布情况
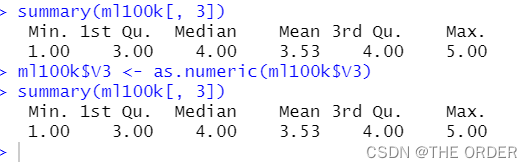
prop.table(table(ml100k[, 3]))
summary(ml100k[, 3])
ml100k
V3)
summary(ml100k[, 3])
3 数据处理转换
as(ml.ratingMatrix , "matrix")[1:3, 1:10]
as(ml.ratingMatrix , "list")[[1]][1:10]
另外,recommenderlab包中有提供用于归一化的函数normalize,默认是均值归一化x – mean,
建立推荐模型的函数,里面有归一化处理的,在此不必单独进行归一化。
在建模之前可以先看下针对realRatingMatrix,recommederlab有提供那些推荐技术,总共有6种,
我们会用到其中的三种random(随机推荐),ubcf(基于流行度推荐),ibcf(基于项目协同过滤)
以IBCF为例简单介绍参数的含义
K:取多少个最相似的item,默认为30
method :相似度算法,默认采用余弦相似算法cosine
Normalize:采用何种归一化算法,默认均值归一化x –mean
normalize_sim_matrix:是否对相似矩阵归一化,默认为否
alpha:alpha参数值,默认为0.5
na_as_zero:是否将NA作为0,默认为否
minRating:最小评分,默认不设置
这些参数均可在建立模型时设置,本文全部采用默认参数。
建立推荐模型
#recommender是recommenderlab包中用于建立模型的函数,用法也相当简单,
#注意在调用recommender之前需给矩阵的所有列按照itemlabels进行列命名。
colnames(ml.ratingMatrix) <- paste(“M”, 1:1682, sep = “”)
as(ml.ratingMatrix[1,1:10], “list”)

4 建立模型与预测
##【Warning】在建立推荐模型之前一定要给item按照itemLabels进行命名,否则会有如下错误
##Error in validObject(.Object) :
## invalid class “topNList” object: invalid object for slot "itemLabels" in class "topNList": got class "NULL", should be or extend class "character"
ml.recommModel <- Recommender(ml.ratingMatrix[1:30], method = "IBCF")
ml.recommModel
#Recommender of type ‘POPULAR’ for ‘realRatingMatrix’
#learned using 800 users.
#模型建立以后,可以用来进行预测和推荐了,同样使用predict函数,这里分别给801-803三个用户进行推荐,
#predict函数有一个type参数,可用来设置是top-n推荐还是评分预测,默认是top-n推荐。
##TopN推荐,n = 5 表示Top5推荐
ml.predict1 <- predict(ml.recommModel, ml.ratingMatrix[801:803], n = 5)
ml.predict1
as( ml.predict1, "list") ##显示三个用户的Top3推荐列表

5 模型评估
##用户对item的评分预测
ml.predict2 <- predict(ml.recommModel, ml.ratingMatrix[801:803], type = "ratings")
ml.predict2
as(ml.predict2, "matrix")[1:3, 1:6] ##查看三个用于对M1-6的预测评分
#模型的评估
#本文只考虑评分预测模型的评估,对于Top-N推荐模型请查看后面的参考资料,对于评分预测模型的评估,最经典的参数是RMSE(均平方根误差)
rmse <- function(actuals, predicts)
{
sqrt(mean((actuals - predicts)^2, na.rm = T))
}
#幸运的是,recommenderlab包有提供专门的评估方案,对应的函数是evaluationScheme,
#能够设置采用n-fold交叉验证还是简单的training/train分开验证,本文采用后一种方法,
#即将数据集简单分为training和test,在training训练模型,然后在test上评估。
model.eval <- evaluationScheme(ml.ratingMatrix[1:943], method = "split", train = 0.9, given = 15, goodRating = 5)
model.eval
##分别用RANDOM、UBCF、IBCF建立预测模型
model.random <- Recommender(getData(model.eval, "train"), method = "RANDOM")
model.ubcf <- Recommender(getData(model.eval, "train"), method = "UBCF")
model.ibcf <- Recommender(getData(model.eval, "train"), method = "IBCF")
##分别根据每个模型预测评分
predict.random <- predict(model.random, getData(model.eval, "known"), type = "ratings")
predict.ubcf <- predict(model.ubcf, getData(model.eval, "known"), type = "ratings")
predict.ibcf <- predict(model.ibcf, getData(model.eval, "known"), type = "ratings")
#这里简单介绍,数据集是如何划分的,其实很简单,对于用户没有评分过的items,是没法进行模型评估的,因为预测值没有参照对象。
#getData的参数given便是来设置用于预测的items数量。
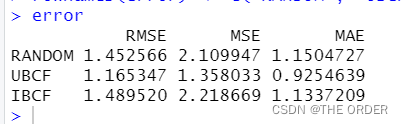
#接下来计算RMSE,对比三个模型的评估参数,calcPredictionError函数可以计算出MAE(绝对值均方误差)、MSE和RMSE。
error <- rbind(
calcPredictionAccuracy(predict.random, getData(model.eval, "unknown")),
calcPredictionAccuracy(predict.ubcf, getData(model.eval, "unknown")),
calcPredictionAccuracy(predict.ibcf, getData(model.eval, "unknown")))
rownames(error) <- c("RANDOM", "UBCF", "IBCF")
error
6 SVD比较
SVD 比较
model.svd <- Recommender(getData(model.eval, “train”), method = “SVD”)
predict.svd <- predict(model.svd, getData(model.eval, “known”), type = “ratings”)
calcPredictionAccuracy(predict.svd, getData(model.eval, “unknown”))
推荐结果比较
##分别给1-100用户建立模型
ml.recommModel_IBCF <- Recommender(ml.ratingMatrix[1:100], method = “IBCF”)
ml.recommModel_UBCF <- Recommender(ml.ratingMatrix[1:100], method = “UBCF”)
ml.recommModel_svd <- Recommender(ml.ratingMatrix[1:100], method = “SVD”)
给801-803进行预测
predict_IBCF <- predict(ml.recommModel_IBCF,ml.ratingMatrix[801:803], n = 5)
predict_UBCF <- predict(ml.recommModel_UBCF,ml.ratingMatrix[801:803], n = 5)
predict_svd <- predict(ml.recommModel_svd,ml.ratingMatrix[801:803], n = 5)
as(predict_IBCF,“list”)
as(predict_UBCF,“list”)
as(predict_svd,“list”)
evaluate result
evl.IBCF <- evaluate(model.eval,method=“IBCF”,n=c(1,3,5,10,15,20))
evl.IBCF
getConfusionMatrix(evl.IBCF)
model.eval1 <- evaluationScheme(ml.ratingMatrix, method=“cross”,k=4,given=15,goodRating=5 )
evl.IBCF <- evaluate(model.eval1,method=“IBCF”,n=c(1,3,5,10,15,20))
getConfusionMatrix(evl.IBCF)
avg(evl.IBCF)
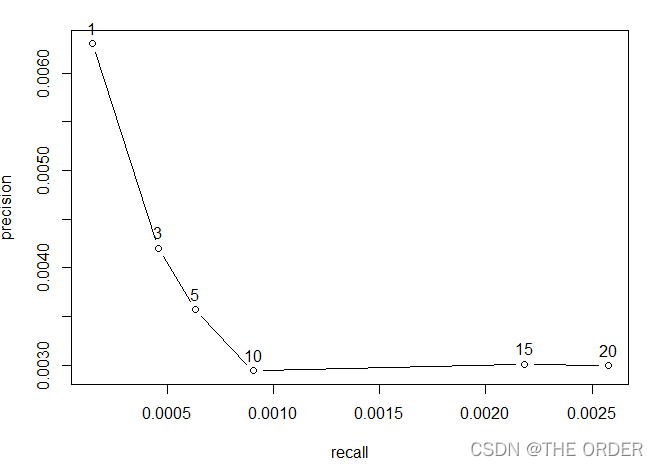
plot(evl.IBCF,annotate=TRUE)
plot(evl.IBCF,“prec/rec”,annotate=TRUE)
aggregate
together <- list(
“Random” = list(name=“RANDOM”,param=NULL),
“IBCF” = list(name=“IBCF”),
“UBCF” = list(name=“UBCF”),
“SVD” = list(name=“SVD”)
)
result <- evaluate(model.eval,together,n=c(1,3,5,10,15,20))
plot(result,annotate=TRUE,legend=“topleft”)
plot(result,“prec/rec”,annotate=TRUE,legend=“topleft”)


- 点赞
- 收藏
- 关注作者
评论(0)