线性回归与logistic回归综合实战

综合应用
在上二个章节,分别介绍了二中回归的用户分层情况与lift(提升度)的图形制作,本章重在综合展现,从二个维度对用户进行分层
1 logistic回归建模
#########################################################################################################################################
############################################################ Part1: logistic model #######################################################
#########################################################################################################################################
file_path_logistic<-"data_response_model.csv" #change the location
raw_logistic<-read.csv(file_path_logistic,stringsAsFactors = F) #read in your csv data
train_logistic<-raw_logistic[raw_logistic$segment=='build',] #select build sample
var_list_logistic<-c('m1_WEB_MNTHS_SINCE_LAST_SES',
'm1_POS_MNTHS_LAST_ORDER',
'm1_POS_NUM_ORDERS_24MO',
'm1_pos_mo_btwn_fst_lst_order',
'm1_EM_COUNT_VALID',
'm1_POS_TOT_REVPERSYS',
'm1_EM_MONTHS_LAST_OPEN',
'm1_POS_LAST_ORDER_DPA'
) #put the final model variables
mods_logistic<-train_logistic[,c('dv_response',var_list_logistic)] #select Y and varibales you want to try
model_glm<-glm(dv_response~.,data=mods_logistic,family =binomial(link ="logit")) #logistic model
summary(model_glm) #model summary
直接用整理好的变量与数据对数据进行logistic建模
2线性回归建模
#########################################################################################################################################
############################################################ Part2: Linear model #######################################################
#########################################################################################################################################
file_path_linear<-"data_revenue_model.csv" #change the location
raw_linear<-read.csv(file_path_linear,stringsAsFactors = F) #read in your csv data
train_linear<-raw_linear[raw_linear$segment=='build',] #select build sample
var_list_linear<-c('m2_POS_REVENUE_BASE',
'm2_POS_LAST_TOTAL_REVENUE',
'm2_POS_MNTHS_LAST_ORDER',
'm2_POS_REVENUE_BASE_SP_6MO',
'm2_POS_SP_QTY_24MO',
'm2_POS_TOT_REVPERSYS',
'm2_WEB_MNTHS_SINCE_LAST_SES',
'm2_SH_MNTHS_LAST_INQUIRED'
) #put the final model variables
mods_linear<-train_linear[,c('dv_revenue',var_list_linear)] #select Y and varibales you want to try
model_lm<-lm(dv_revenue~.,data=mods_linear) #Linear model
summary(model_lm) #model summary
3 综合应用
#########################################################################################################################################
############################################################ Part3:application of 2 models ########################################
#########################################################################################################################################
二种模型预测
file_path<-"two_stage_data.csv"
# read in data
raw<-read.csv(file_path,stringsAsFactors = F)
pred_prob_resp<-predict(model_glm,raw,type='response') #using the logistic model to predict response score
pred_prob_reve<-predict(model_lm,raw,type='response') #using the linear model to predict revenue
################################### 3.1 combo performance #######################
将预测金额*预测概率得出用户评分
combo<-pred_prob_resp*pred_prob_reve #usage 1
head(combo)
# 3.1.1 separate to 10 gorups based on combo
decile_combo<-cut(combo,unique(quantile(combo,(0:10)/10)),labels=10:1, include.lowest = T)
table(decile_combo)
按照得出来的评分进行10分位数分组,排序划分用户层次,进行分组聚合计算活跃用户比列类似sql里面的count(*) group by ,计算本组活跃用户率/总体用户活跃率得出分组后的效果lift图
performance for response based on decile_combo
library(plyr)
#put actual response,predicted response,decile together
combo_resp<-data.frame(actual=raw$dv_response,pred_prob_resp=pred_prob_resp,decile_combo_resp=decile_combo)
#group by decile_combo_resp
combo_decile_sum_resp<-ddply(combo_resp,.(decile_combo_resp),summarise,cnt=length(actual),resp=sum(actual))
combo_decile_sum_resp
combo_decile_sum_resp2<-within(combo_decile_sum_resp,
{rr<-resp/cnt
index<-100*rr/(sum(resp)/sum(cnt))
}) #add rr,index
combo_decile_sum_resp3<-combo_decile_sum_resp2[order(combo_decile_sum_resp2[,1],decreasing=T),] # order decile
View(combo_decile_sum_resp3)
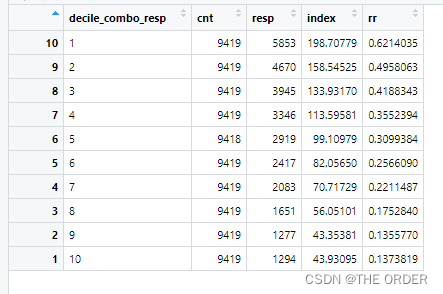
从图中可以发现提升效果很明显
再从线性回归预测的用户消费金额进行分析,同样进行group by ,使用本组平均/全体平均*100得到提升度lift
performance for revenue based on decile_combo
put actual revenue,predicted revenue,decile together
combo_reve<-data.frame(actual=raw$dv_revenue,pred_prob_reve=pred_prob_reve,decile_combo_reve=decile_combo)
#group by decile_combo_reve
combo_decile_sum_reve<-ddply(combo_reve,.(decile_combo_reve),summarise,cnt=length(actual),rev=sum(actual))
combo_decile_sum_reve
combo_decile_sum_reve2<-within(combo_decile_sum_reve,
{rev_avg<-rev/cnt
index<-100*rev_avg/(sum(rev)/sum(cnt))
}) #add rev_avg,index
combo_decile_sum_reve3<-combo_decile_sum_reve2[order(combo_decile_sum_reve2[,1],decreasing=T),] # order decile
View(combo_decile_sum_reve3)
4 消费金额与响应率交叉表制作
response part
separate into 10 groups based on predict_response
decile_resp<-cut(pred_prob_resp,unique(quantile(pred_prob_resp,(0:10)/10)),labels=10:1, include.lowest = T)
table(decile_resp)
revenue part
separate into 10 groups based on predict_revenue
decile_rev<-cut(pred_prob_reve,unique(quantile(pred_prob_reve,(0:10)/10)),labels=10:1, include.lowest = T)
table(decile_rev)
set together
decile_cross<-data.frame( #rid=raw$rid,
dv_response=raw$dv_response,
dv_revenue=raw$dv_revenue,
pred_prob_resp=pred_prob_resp,
pred_prob_reve=pred_prob_reve,
decile_resp=decile_resp,
decile_reve=decile_rev
)
View(decile_cross)
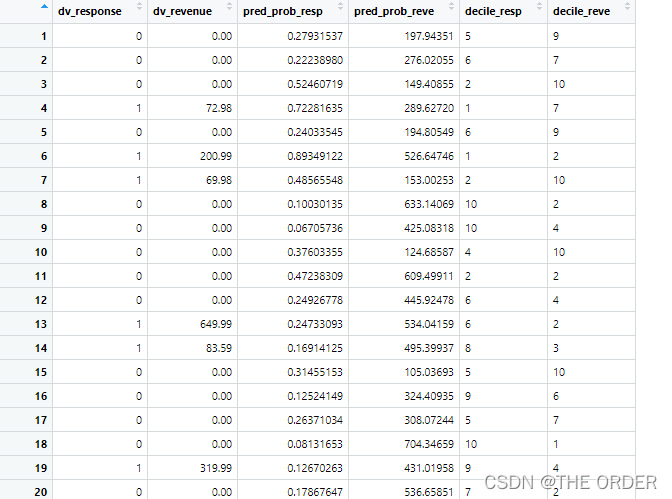
decile_cross
put decile_resp,decile_reve together
cross_table_freq<-table(decile_resp=decile_cross$decile_resp,decile_reve=decile_cross$decile_reve)
View(cross_table_freq)
cross_table_pct<-prop.table(cross_table_freq)
View(cross_table_pct)
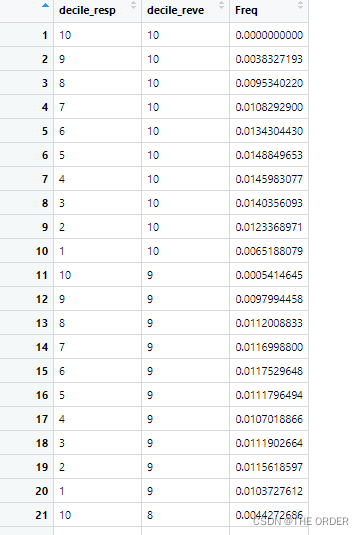
从结果发现清楚的将用户分成消费金额10个层次,用户活跃程度10个层次。10*10=100 总共100个层次的用户
library(sqldf)
a=sqldf(“select decile_reve as rank,
sum(case decile_resp when 1 then Freq else 0 end) as ‘1’,
sum(case decile_resp when 2 then Freq else 0 end) as ‘2’,
sum(case decile_resp when 3 then Freq else 0 end) as ‘3’,
sum(case decile_resp when 4 then Freq else 0 end) as ‘4’,
sum(case decile_resp when 5 then Freq else 0 end) as ‘5’,
sum(case decile_resp when 6 then Freq else 0 end) as ‘6’,
sum(case decile_resp when 7 then Freq else 0 end) as ‘7’,
sum(case decile_resp when 8 then Freq else 0 end) as ‘8’,
sum(case decile_resp when 9 then Freq else 0 end) as ‘9’,
sum(case decile_resp when 10 then Freq else 0 end) as ‘10’
from cross_table_freq
group by rank*1”)
执行sql语句,得到的排序就是用户消费和响应等级客户群体数量的交叉表
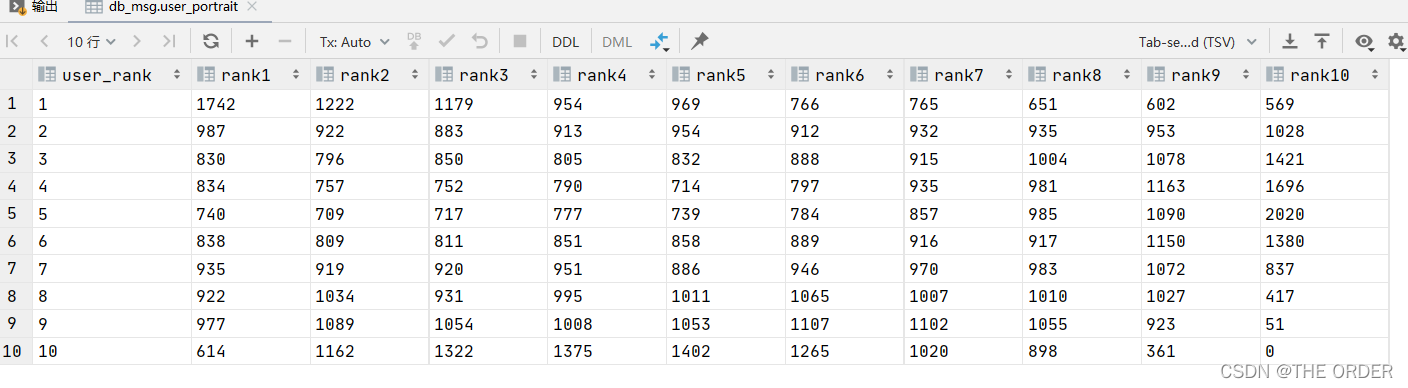
将分好群体的客户与客户原始数据相结合,再使用可视化工具对数据进行分组呈现,客户的标签就呈现出来了。

- 点赞
- 收藏
- 关注作者
评论(0)