logistic回归用户画像用户响应度预测

logistic回归篇章
数据集接应上一节数据集合,本次的分析是从用户是否为高响应用户进行划分,使用logistic回归对用户进行响应度预测,得到响应的概率。线性回归,参考上一篇章
1 读取和预览数据
对数据进行加载读取,数据依旧是脱敏数据,
file_path<-"data_response_model.csv" #change the location
# read in data
options(stringsAsFactors = F)
raw<-read.csv(file_path) #read in your csv data
str(raw) #check the varibale type
View(raw) #take a quick look at the data
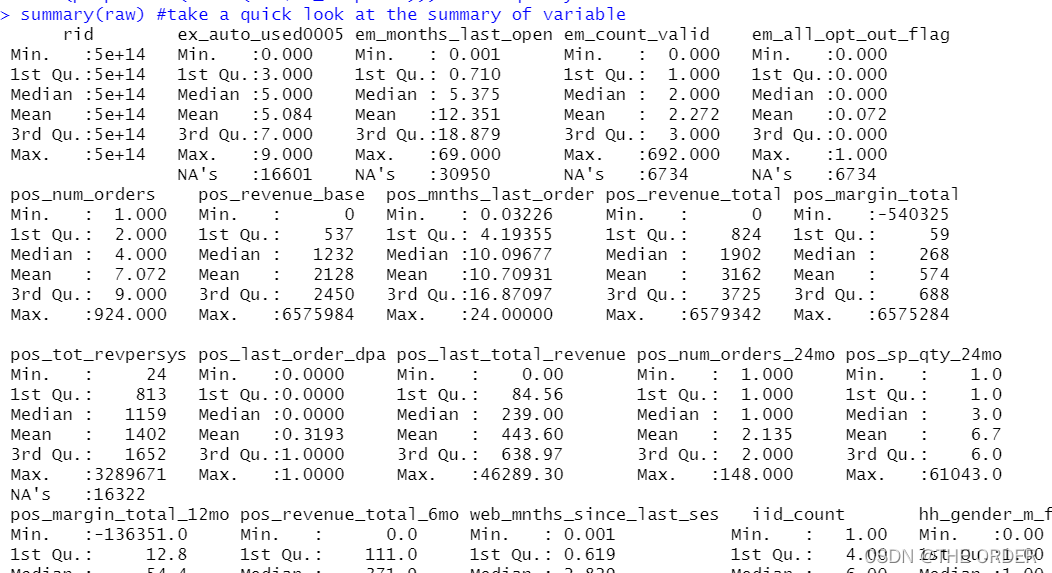
summary(raw) #take a quick look at the summary of variable
# response variable
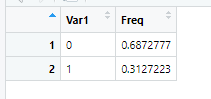
View(table(raw$dv_response)) #Y
View(prop.table(table(raw$dv_response))) #Y frequency
根据业务确定,数据的y值是响应率是dv_response,并观察其情况
2 划分数据
依旧把数据划分为三部分,分别为训练集,验证集和测试集。
#Separate Build Sample
train<-raw[raw$segment=='build',] #select build sample, it should be random selected when you build the model
View(table(train$segment)) #check segment
View(table(train$dv_response)) #check Y distribution
View(prop.table(table(train$dv_response))) #check Y distribution
#Separate invalidation Sample
test<-raw[raw$segment=='inval',] #select invalidation(OOS) sample
View(table(test$segment)) #check segment
View(prop.table(table(test$dv_response))) #check Y distribution
#Separate out of validation Sample
validation<-raw[raw$segment=='outval',] #select out of validation(OOT) sample
View(table(validation$segment)) #check segment
View(prop.table(table(validation$dv_response))) #check Y distribution
3 profilng制作
对数据即中的响应率进行求和,原数据中高响应客户为1,低响应客户为0.求和的总数就是高响应客户数,length就是总记录数,求出其平均数即为总体平均数
# overall performance
overall_cnt=nrow(train) #calculate the total count
overall_resp=sum(train$dv_response) #calculate the total responders count
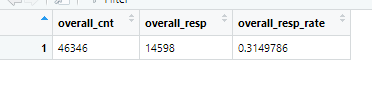
overall_resp_rate=overall_resp/overall_cnt #calculate the response rate
overall_perf<-c(overall_count=overall_cnt,overall_responders=overall_resp,overall_response_rate=overall_resp_rate) #combine
overall_perf<-c(overall_cnt=nrow(train),overall_resp=sum(train$dv_response),overall_resp_rate=sum(train$dv_response)/nrow(train)) #combine
View(t(overall_perf)) #take a look at the summary
这里做的划分如同上一章节的划分lift图制作,也可用sql语句来写,如同group by,计算出每组的平均响应率与总体响应率的比较。
在library之前,请先下载plyr包,写sql需下载sqldf
install.packages(“sqldf”)
library(plyr) #call plyr
?ddply
prof<-ddply(train,.(hh_gender_m_flag),summarise,cnt=length(rid),res=sum(dv_response)) #group by hh_gender_m_flg
View(prof) #check the result
tt=aggregate(train[,c("hh_gender_m_flag","rid")],by=list(train[,c("hh_gender_m_flag")]),length) #group by hh_gender_m_flg
View(tt)
#calculate the probablity
#prop.table(as.matrix(prof[,-1]),2)
#t(t(prof)/colSums(prof))
prof1<-within(prof,{res_rate<-res/cnt
index<-res_rate/overall_resp_rate*100
percent<-cnt/overall_cnt
}) #add response_rate,index, percentage
View(prof1) #check the result
library(sqldf)
#整型乘浮点型变浮点数据
sqldf("select hh_gender_m_flag,count() as cnt,sum(dv_response)as res,1.0sum(dv_response) /count(*) as res_rate from train group by 1 ")
缺失值也能作为特征的一部分,同样可以对缺失值进行lift比较
nomissing<-data.frame(var_data[!is.na(var_data$em_months_last_open),]) #select the no missing value records
missing<-data.frame(var_data[is.na(var_data$em_months_last_open),]) #select the missing value records
###################################### numeric Profiling:missing part #############################################################
missing2<-ddply(missing,.(em_months_last_open),summarise,cnt=length(dv_response),res=sum(dv_response)) #group by em_months_last_open
View(missing2)
missing_perf<-within(missing2,{res_rate<-res/cnt
index<-res_rate/overall_resp_rate*100
percent<-cnt/overall_cnt
var_category<-c('unknown')
}) #summary
View(missing_perf)

这里对非缺失值数据进行了划分,将非缺失值数据,按照十分位数划分成了10等分。分别计算其总记录数和总高响应客户数量
nomissing_value<-nomissing$em_months_last_open #put the nomissing values into a variable
#method1:equal frequency
nomissing$var_category<-cut(nomissing_value,unique(quantile(nomissing_value,(0:10)/10)),include.lowest = T)#separte into 10 groups based on records
class(nomissing$var_category)
View(table(nomissing$var_category)) #take a look at the 10 category
prof2<-ddply(nomissing,.(var_category),summarise,cnt=length(dv_response),res=sum(dv_response)) #group by the 10 groups
View(prof2)
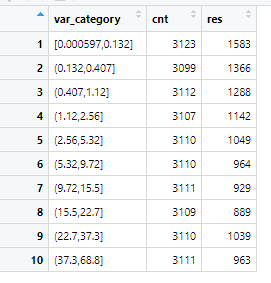
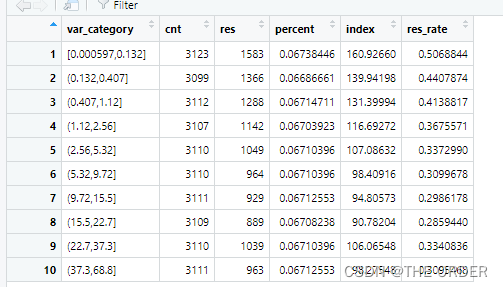
再次对划分为10等分的数据每一组都进行lift计算,比较每组的平均高响应用户数与总体的用户数的比值。大于100%就是高于总体表现的客户标签
nonmissing_perf<-within(prof2,
{res_rate<-res/cnt
index<-res_rate/overall_resp_rate*100
percent<-cnt/overall_cnt
}) #add resp_rate,index,percent
View(nonmissing_perf)
#set missing_perf and non-missing_Perf together
View(missing_perf)
View(nonmissing_perf)
em_months_last_open_perf<-rbind(nonmissing_perf,missing_perf[,-1]) #set 2 data together
View(em_months_last_open_perf)
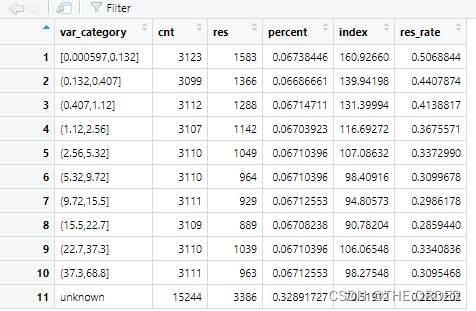
4 缺失值,异常值处理
1 少于3%直接删除或者中位数,平均数填补
2 3%——20%删除或knn,EM回归填补
3 20%——50% 多重插补
4 50——80%缺失值分类法
5 高于80%丢弃,数据太不准确了,分析失误性很大
异常值通常用盖帽法解决
numeric variables
train$m2_em_count_valid <- ifelse(is.na(train$em_count_valid) == T, 2, #when em_count_valid is missing ,then assign 2
ifelse(train$em_count_valid <= 1, 1, #when em_count_valid<=1 then assign 1
ifelse(train$em_count_valid >=10, 10, #when em_count_valid>=10 then assign 10
train$em_count_valid))) #when 1<em_count_valid<10 and not missing then assign the raw value
summary(train$m2_em_count_valid) #do a summary
summary(train$m1_EM_COUNT_VALID) #do a summary
5 模型拟合
根据业务选取最有价值的变量
library(picante) #call picante
var_list<-c('dv_response','m1_POS_NUM_ORDERS_24MO',
'm1_POS_NUM_ORDERS',
'm1_SH_MNTHS_LAST_INQUIRED',
'm1_POS_SP_QTY_24MO',
'm1_POS_REVENUE_TOTAL',
'm1_POS_LAST_ORDER_DPA',
'm1_POS_MARGIN_TOTAL',
'm1_pos_mo_btwn_fst_lst_order',
'm1_POS_REVENUE_BASE',
'm1_POS_TOT_REVPERSYS',
'm1_EM_COUNT_VALID',
'm1_EM_NUM_OPEN_30',
'm1_POS_MARGIN_TOTAL_12MO',
'm1_EX_AUTO_USED0005_X5',
'm1_SH_INQUIRED_LAST3MO',
'm1_EX_AUTO_USED0005_X789',
'm1_HH_INCOME',
'm1_SH_INQUIRED_LAST12MO',
'm1_POS_LAST_TOTAL_REVENUE',
'm1_EM_ALL_OPT_OUT_FLAG',
'm1_POS_REVENUE_TOTAL_6MO',
'm1_EM_MONTHS_LAST_OPEN',
'm1_POS_MNTHS_LAST_ORDER',
'm1_WEB_MNTHS_SINCE_LAST_SES') #put the variables you want to do correlation analysis here
制作相关系数矩阵,根据相关性筛选变量相关的,共线性选择标识变量法或哑变量法,logistic回归可使用IV值选择变量
corr_var<-train[, var_list] #select all the variables you want to do correlation analysis
str(corr_var) #check the variable type
correlation<-data.frame(cor.table(corr_var,cor.method = 'pearson')) #do the correlation
View(correlation)
cor_only=data.frame(row.names(correlation),correlation[, 1:ncol(corr_var)]) #select correlation result only
View(cor_only)
选择完,准备放到模型里面的变量
var_list<-c('m1_WEB_MNTHS_SINCE_LAST_SES',
'm1_POS_MNTHS_LAST_ORDER',
'm1_POS_NUM_ORDERS_24MO',
'm1_pos_mo_btwn_fst_lst_order',
'm1_EM_COUNT_VALID',
'm1_POS_TOT_REVPERSYS',
'm1_EM_MONTHS_LAST_OPEN',
'm1_POS_LAST_ORDER_DPA'
) #put the variables you want to try in model here
mods<-train[,c(‘dv_response’,var_list)] #select Y and varibales you want to try
str(mods)
非标准化拟合,拟合后再使用逐步回归法进行筛选变量
mods<-train[,c('dv_response',var_list)] #select Y and varibales you want to try
str(mods)
(model_glm<-glm(dv_response~.,data=mods,family =binomial(link ="logit"))) #logistic model
model_glm
#Stepwise
library(MASS)
model_sel<-stepAIC(model_glm,direction ="both") #using both backward and forward stepwise selection
model_sel
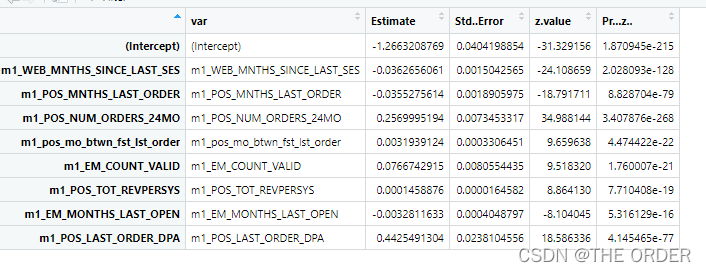
summary<-summary(model_sel) #summary
model_summary<-data.frame(var=rownames(summary$coefficients),summary$coefficients) #do the model summary
View(model_summary)
对数据进行标准化后的建模,标准化的建模方便查看每个变量对y的影响程度
#variable importance
#standardize variable
#?scale
mods2<-scale(train[,var_list],center=T,scale=T)
mods3<-data.frame(dv_response=c(train$dv_response),mods2[,var_list])
# View(mods3)
(model_glm2<-glm(dv_response~.,data=mods3,family =binomial(link ="logit"))) #logistic model
(summary2<-summary(model_glm2))
model_summary2<-data.frame(var=rownames(summary2$coefficients),summary2$coefficients) #do the model summary
View(model_summary2)
model_summary2_f<-model_summary2[model_summary2$var!='(Intercept)',]
model_summary2_f$contribution<-abs(model_summary2_f$Estimate)/(sum(abs(model_summary2_f$Estimate)))
View(model_summary2_f)
6 模型评估
回归拟合的VIF值
#Variable VIF
fit <- lm(dv_response~., data=mods) #regression model
#install.packages('car') #Install Package 'Car' to calculate VIF
require(car) #call Car
vif=data.frame(vif(fit)) #get Vif
var_vif=data.frame(var=rownames(vif),vif) #get variables and corresponding Vif
View(var_vif)
相关系数矩阵制作
#variable correlation
cor<-data.frame(cor.table(mods,cor.method = 'pearson')) #calculate the correlation
correlation<-data.frame(variables=rownames(cor),cor[, 1:ncol(mods)]) #get correlation only
View(correlation)

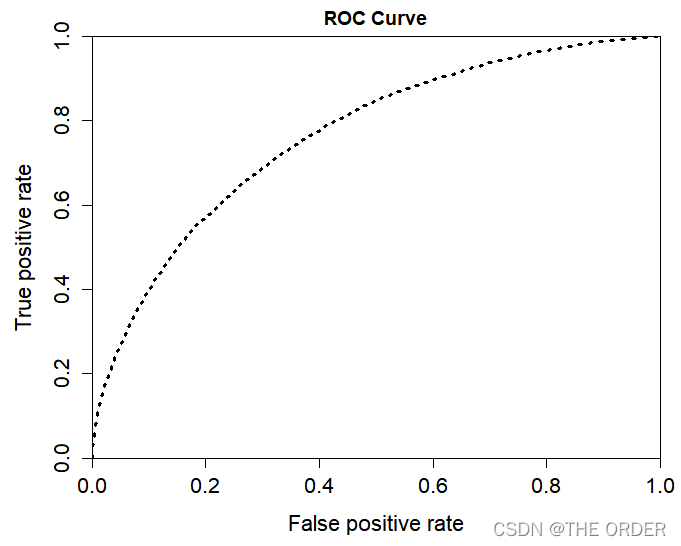
最后制作ROC曲线,对模型画ROC曲线图,观察其效果
library(ROCR)
#### test data####
pred_prob<-predict(model_glm,test,type='response') #predict Y
pred_prob
pred<-prediction(pred_prob,test$dv_response) #put predicted Y and actual Y together
pred@predictions
View(pred)
perf<-performance(pred,'tpr','fpr') #Check the performance,True positive rate
perf
par(mar=c(5,5,2,2),xaxs = "i",yaxs = "i",cex.axis=1.3,cex.lab=1.4) #set the graph parameter
#AUC value
auc <- performance(pred,"auc")
unlist(slot(auc,"y.values"))
#plotting the ROC curve
plot(perf,col="black",lty=3, lwd=3,main='ROC Curve')
#plot Lift chart
perf<-performance(pred,‘lift’,‘rpp’)
plot(perf,col=“black”,lty=3, lwd=3,main=‘Lift Chart’)

7 总体划分用户群lift图

pred<-predict(model_glm,train,type='response') #Predict Y
decile<-cut(pred,unique(quantile(pred,(0:10)/10)),labels=10:1, include.lowest = T) #Separate into 10 groups
sum<-data.frame(actual=train$dv_response,pred=pred,decile=decile) #put actual Y,predicted Y,Decile together
decile_sum<-ddply(sum,.(decile),summarise,cnt=length(actual),res=sum(actual)) #group by decile
decile_sum2<-within(decile_sum,
{res_rate<-res/cnt
index<-100*res_rate/(sum(res)/sum(cnt))
}) #add resp_rate,index
decile_sum3<-decile_sum2[order(decile_sum2[,1],decreasing=T),] #order decile
View(decile_sum3)
采用的是十分位数划分,等记录数的划分客户群体,可以发现1-10个层次的用户,真实响应率lift值不错。
将回归方程贴出来
ss <- summary(model_glm) #put model summary together
ss
which(names(ss)=="coefficients")
#XBeta
#Y = 1/(1+exp(-XBeta))
#output model equoation
gsub("\\+-","-",gsub('\\*\\(Intercept)','',paste(ss[["coefficients"]][,1],rownames(ss[["coefficients"]]),collapse = "+",sep = "*")))


- 点赞
- 收藏
- 关注作者
评论(0)