用户画像之线性回归逻辑回归综合实战

【摘要】 用户画像之线性回归逻辑回归综合实战
@TOC
线性回归篇
导语:本次使用的数据是网上提供的脱敏消费数据,因变量全数值类型,数据本身符合线性回归标准,初始数据选择请确保数据符合马尔可夫五大假设,再进行线性回归拟合,
1 线性与参数
2 不存在多重共线性
3 残差的正态性
4 残差的均值为0
5 残差的同方差性
1 初期准备
raw<-read.csv("data_revenue_model.csv",stringsAsFactors = F)#read in your csv data
str(raw) #check the varibale type
View(raw) #take a quick look at the data
summary(raw) #take a quick look at the summary of variable
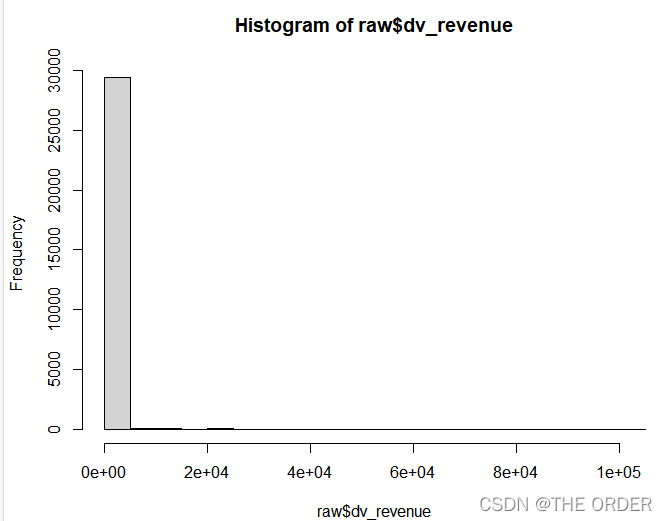
Y值预览明显右偏
#dv_revenue
hist(raw$dv_revenue) #Y histogram
quantile(raw$dv_revenue,(1:20)/20) #Y quantile
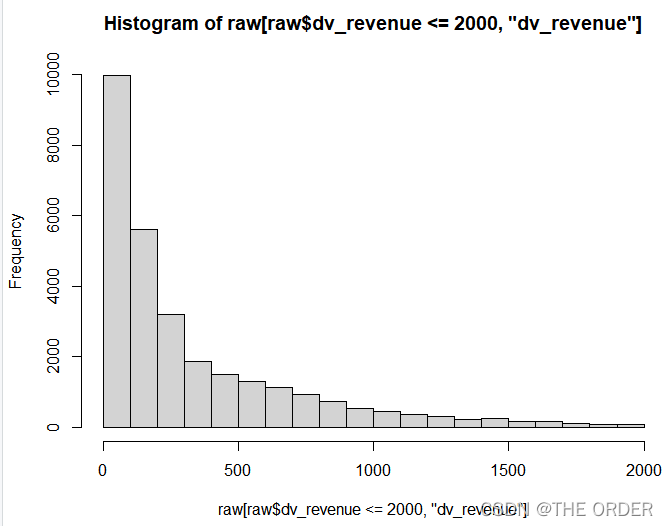
阈值处理
hist(raw[raw$dv_revenue<=2000,'dv_revenue'])
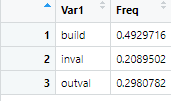
2 分割数据集
# modeling segments
View(table(raw$segment))
View(prop.table(table(raw$segment)))
将数据集分为训练集,验证集,测试集
#train validation 70/30 split
raw_2=raw[raw$segment!="outval",]
View(prop.table(table(raw_2$segment)))
#Separate Build Sample
train<-raw[raw$segment=='build',] #select build sample
View(table(train$segment)) #check segment
#Separate invalidation Sample
test<-raw[raw$segment=='inval',] #select invalidation(OOS) sample
View(table(test$segment)) #check segment
#Separate out of validation Sample
validation<-raw[raw$segment=='outval',] #select out of validation(OOT) sample
View(table(validation$segment)) #check segment
3 lift制作
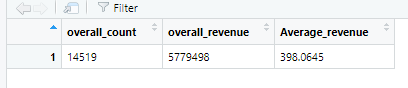
预览数据,查看分层情况,对数据进行计算,计算总的消费金额,记录总行数,平均用户消费金额
#overall performance
overall_cnt=nrow(train) #calculate the total count
overall_revenue=sum(train$dv_revenue) #calculate the total revenue
Average_revenue=overall_revenue/overall_cnt #calculate the average revenue
overall_perf<-c(overall_count=overall_cnt,overall_revenue=overall_revenue,Average_revenue=Average_revenue) #combine
View(t(overall_perf)) #take a look at the summary
对变量进行lift系数计算,lift=对该变量分组后组内的平均消费额度/总数据平均消费额度
prof_exe<-ddply(train,.(ex_auto_used0005),summarise,cnt=length(rid),rev=sum(dv_revenue))
View(prof_exe)
prof1_exe<-within(prof_exe,
{AVG_REVENUE<-rev/cnt
index<-AVG_REVENUE/Average_revenue*100
percent<-cnt/overall_cnt
})
View(prof1_exe)
也可以用sql写
#use sqldf if you are familiar with sql
#install.packages(‘sqldf’)
#library(sqldf)
#sqldf("select hh_gender_m_flag,count() as cnt,sum(dv_revenue)as rev,sum(dv_revenue)/count() as AVG_REVENUE from train group by 1 ")
4 缺失值处理
缺失值少于20%可直接删除,或者平均数,中位数填充,甚至可以knn填充
train$m3_pos_revenue_base_sp_6mo <- ifelse(is.na(train$pos_revenue_base_sp_6mo) == T, 294.16, #when pos_revenue_base_sp_6mo is missing ,then assign 294.16
ifelse(train$pos_revenue_base_sp_6mo <= 0, 0, #when pos_revenue_base_sp_6mo<=0 then assign 0
ifelse(train$pos_revenue_base_sp_6mo >=4397.31, 4397.31, #when pos_revenue_base_sp_6mo>=4397.31 then assign 4397.31
train$pos_revenue_base_sp_6mo))) #when 0<pos_revenue_base_sp_6mo<4397.31 and not missing then assign the raw value
summary(train$m3_pos_revenue_base_sp_6mo) #do a summary
summary(train$m2_POS_REVENUE_BASE_SP_6MO) #do a summary
summary(train$pos_revenue_base_sp_6mo)
train$mn_ex_auto_used0005_x1 <- ifelse(is.na(train$ex_auto_used0005), 0,
ifelse(train$ex_auto_used0005 == 1, 1, 0))
View(train)
5 变量确定与模型拟合
确定变量的第一步是根据业务确定,确定有可能的指标,再进行相关分析,模型拟合,AIC筛选
library(picante) #call picante
var_list1<-c(
'm2_POS_REVENUE_BASE',
'm2_POS_LAST_TOTAL_REVENUE',
'm2_POS_REVENUE_TOTAL',
'm2_POS_REVENUE_TOTAL_6MO',
'm2_POS_MARGIN_TOTAL',
'm2_POS_MARGIN_TOTAL_12MO',
'm2_POS_SP_QTY_24MO',
'm2_EM_COUNT_VALID',
'm2_IID_COUNT',
'm2_EM_NUM_OPEN_30',
'm2_SH_INQUIRED_LAST12MO',
'm2_WEB_CNT_IID_ACCESSED',
'm2_SH_INQUIRED_LAST3MO',
'm2_POS_MNTHS_LAST_ORDER',
'm2_POS_NUM_ORDERS',
'm2_POS_TOT_REVPERSYS',
'm2_POS_NUM_ORDERS_24MO',
'm2_HH_INCOME',
'm2_EM_MONTHS_LAST_OPEN',
'm2_HH_AGE',
'm2_WEB_MNTHS_SINCE_LAST_SES',
'm2_POS_REVENUE_BASE_SP_6MO',
'm2_SH_MNTHS_LAST_INQUIRED')
进行相关分析,做出相关性矩阵
####all variables correlation
corr_var<-train[, var_list1] #select all the variables you want to do correlation analysis
str(corr_var) #check the variable type
correlation<-data.frame(cor.table(corr_var,cor.method = 'pearson')) #do the correlation
View(correlation)
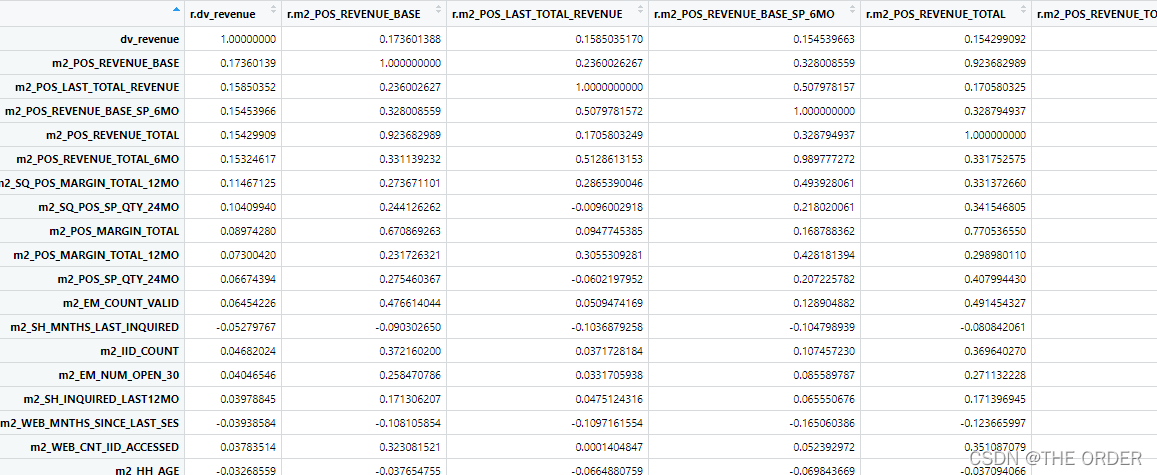
依据相关系数矩阵筛选相关系数高的变量,对于x之间相关性高的可以做标识变量或哑变量
初次模型拟合
mods<-train[,c('dv_revenue',var_list1)] #select Y and variables you want to try
model_lm<-lm(dv_revenue~.,data=mods) #regression model
model_lm
summary(model_lm)
再使用逐步回归法
#Stepwise
library(MASS)
model_sel<-stepAIC(model_lm,direction ="both") #using both backward and forward stepwise selection
summary<-summary(model_sel) #summary
summary
model_summary<-data.frame(var=rownames(summary$coefficients),summary$coefficients) #do the model summary
model_summary
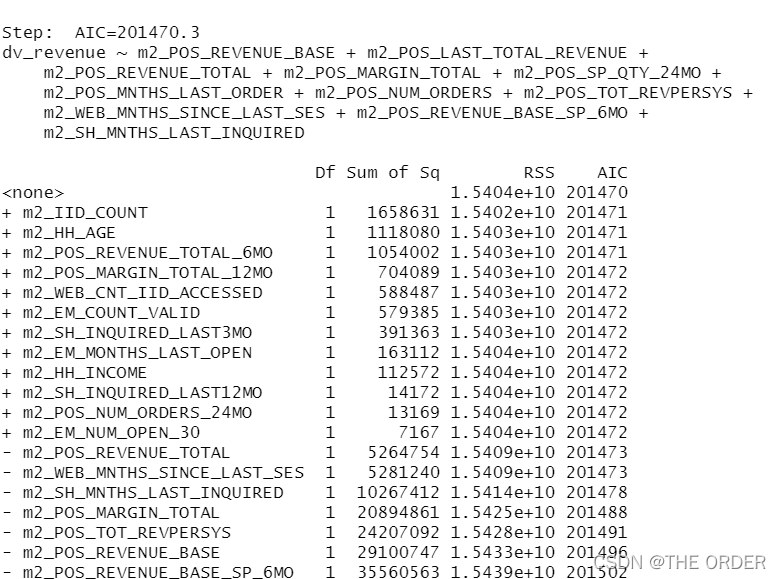
模型预测,并对预测的结果进行分群排序,分别依照10分为数划分,1代表前10%
#lift Chart:train
pred<-predict(model_lm,train,type='response') #Predict Y
decile<-cut(pred,unique(quantile(pred,(0:10)/10)),labels=10:1, include.lowest = T) #Separate into 10 groups
# decile
sum<-data.frame(actual=train$dv_revenue,pred=pred,decile=decile) #put actual Y,predicted Y,Decile together
View(sum)
decile_sum<-ddply(sum,.(decile),summarise,cnt=length(actual),rev=sum(actual)) #group by decile
decile_sum2<-within(decile_sum,
{rev_avg<-rev/cnt
index<-100*rev_avg/(sum(rev)/sum(cnt))
}) #add Avg_Rev,index
View(decile_sum2)
decile_sum3<-decile_sum2[order(decile_sum2[,1],decreasing=T),] #order decile
View(decile_sum3)

从中可以发现排序较前分组里面的平均花费比总体平均高,并成降序排序
#test data
pred_test<-predict(model_lm,test,type='response')
decile_test<-cut(pred_test,unique(quantile(pred_test,(0:10)/10)),labels = 10:1,include.lowest = T)
sum_test<-data.frame(actual=test$dv_revenue,pred=pred_test,decile=decile_test)
View(sum_test)
decile_sum_test<-ddply(sum_test,.(decile_test),summarise,cnt=length(actual),rev=sum(actual))
decile_sum_test2<-within(decile_sum_test,
{rev_avg<-rev/cnt
index<-100*rev_avg/(sum(rev)/sum(cnt))
})
View(decile_sum_test2)
decile_sum_test3<-decile_sum_test2[order(decile_sum_test2[,1],decreasing = T),]
View(decile_sum_test3)
测试集数据同理
6 lift图制作
#plot
plot(1:10, decile_sum3$index, type="b",pch=16,lty=1,xlab="decile",ylab="index")
lines(1:10,decile_sum_test3$index,type='b',lty=2,pch=17)
legend('topright',inset=0.05,c('train','test'),lty=c(1,2),pch=c(16,17))
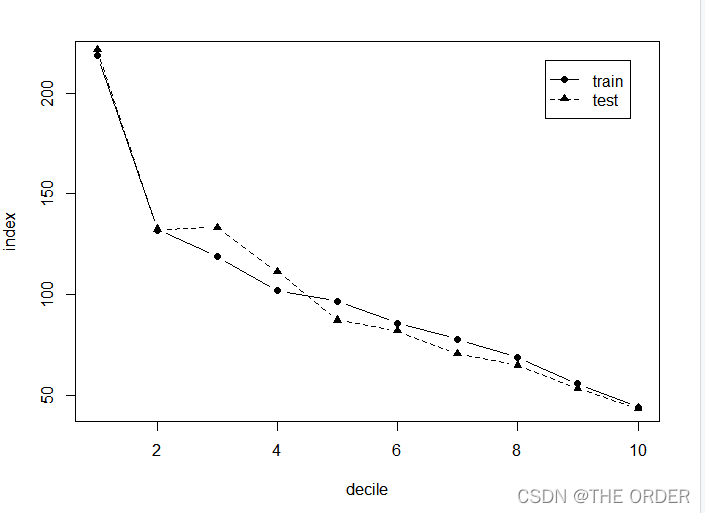
7 输出模型公式
#output model equoation
ss <- summary(model_lm)
names(ss)
ss[[4]]
gsub("\\+-","-",gsub('\\*\\(Intercept\\)','',paste(ss[[4]][,1],rownames(ss[[4]]),collapse = "+",sep = "*")

将客户分群与客户信息相结合

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)