Hadoop快速入门——第二章、分布式集群(第四节、搭建开发环境)

【摘要】 Hadoop快速入门——第二章、分布式集群引包:<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version></dependency>可以先安装一下【Big Data Tools】安装完成后需要重新启动一下。个人建议,先...

![]()
Hadoop快速入门——第二章、分布式集群
引包:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
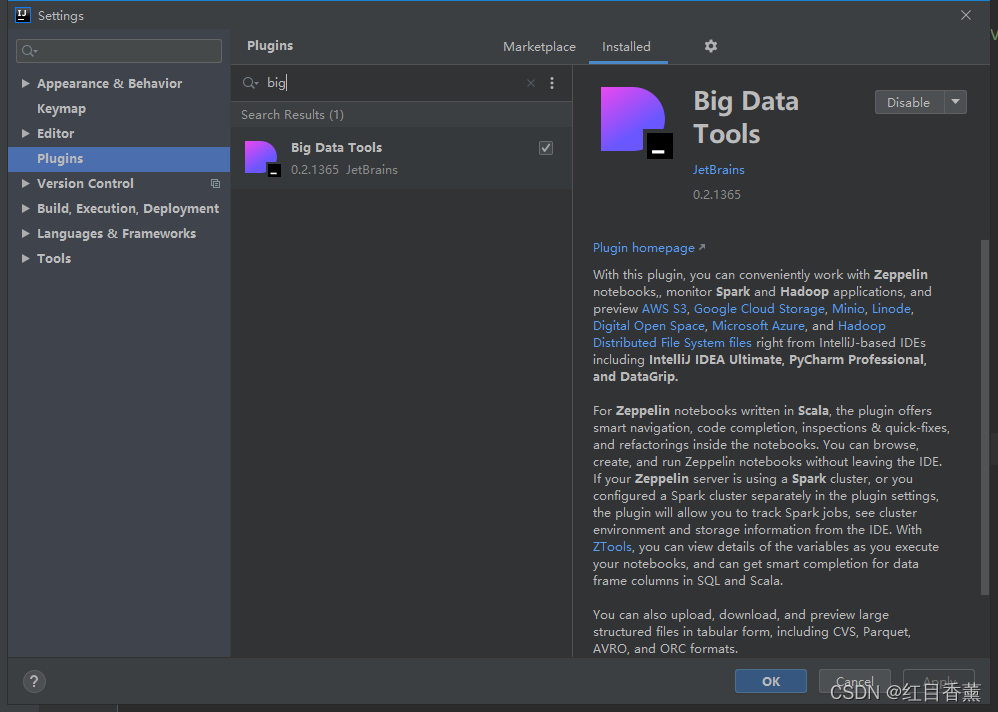
可以先安装一下【Big Data Tools】
![]()
安装完成后需要重新启动一下。
个人建议,先改一下【镜像】位置为国内的,我就没改,直接update了,玩了好几把【连连看】都没下载完毕。

![]()
创建测试类:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
System.out.println(action.conf);
System.out.println(action.fs);
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
输出:
Configuration: core-default.xml, core-site.xml, mapred-default.xml, mapred-site.xml, yarn-default.xml, yarn-site.xml, hdfs-default.xml, hdfs-site.xml
org.apache.hadoop.fs.LocalFileSystem@43195e57

![]()
文件操作:
mkdirs:创建文件夹
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
boolean isf = action.fs.mkdirs(new Path("/data/infos/"));
System.out.println(isf?"创建成功":"创建失败");
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
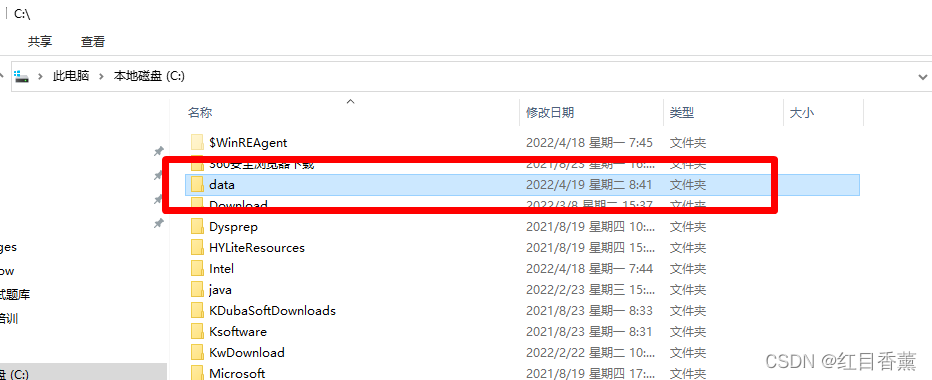
会创建在【C盘的根目录】
![]()
copyFromLocalFile:复制文件到服务器(本地模拟)
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
action.fs.copyFromLocalFile(new Path("D:/info.txt"),new Path("/data/infos"));
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
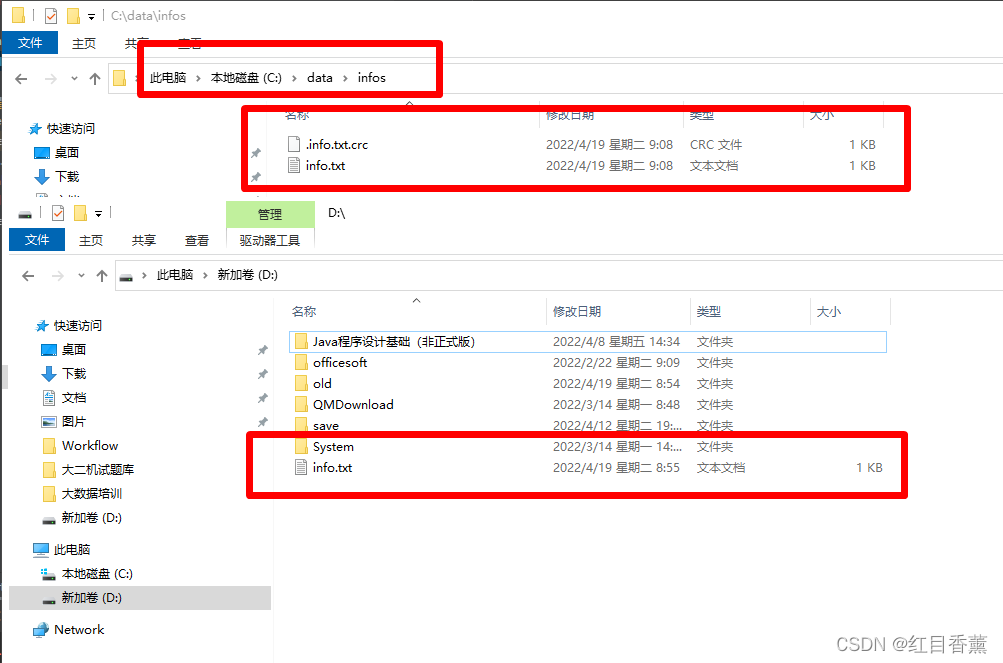
本地效果:
![]()
修改文件名称【rename】:
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
SimpleDateFormat format=new SimpleDateFormat("yyyy_MM_dd");
Date now = new Date();
boolean isf = action.fs.rename(new Path("/data/infos/info.txt"), new Path("/data/infos/" + format.format(now) + ".txt"));
System.out.println(isf?"修改成功":"修改失败");
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
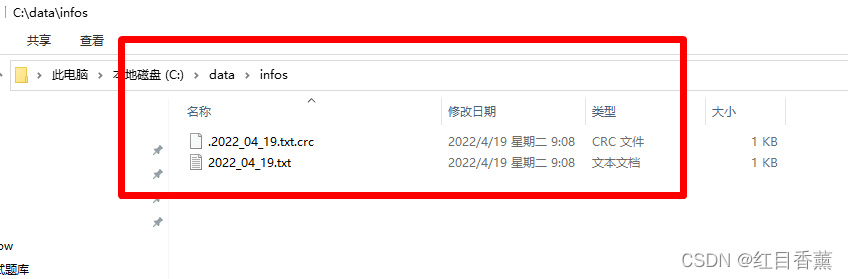
本地效果:
![]()
删除文件deleteOnExit:
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
boolean isf = action.fs.deleteOnExit(new Path("/data/infos/2022_04_19.txt"));
System.out.println(isf?"刪除成功":"刪除失败");
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}

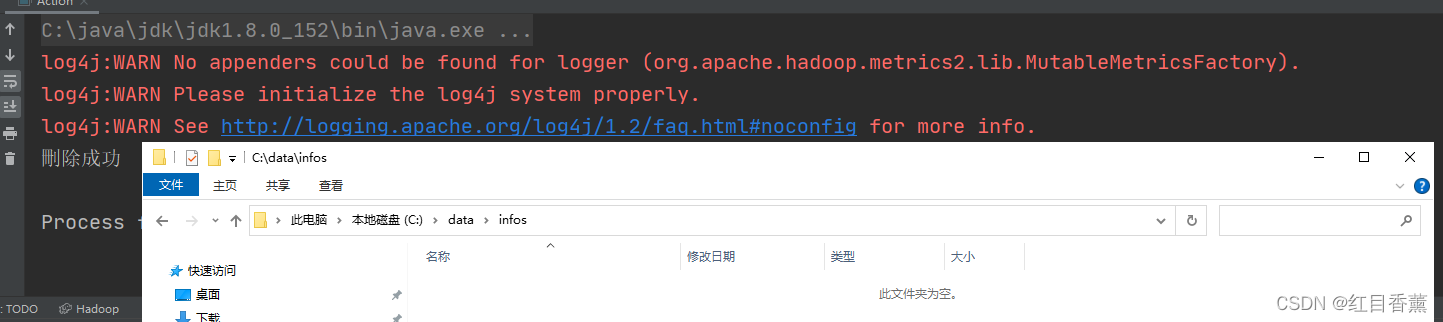
查看目录信息:
做一些测试文件:
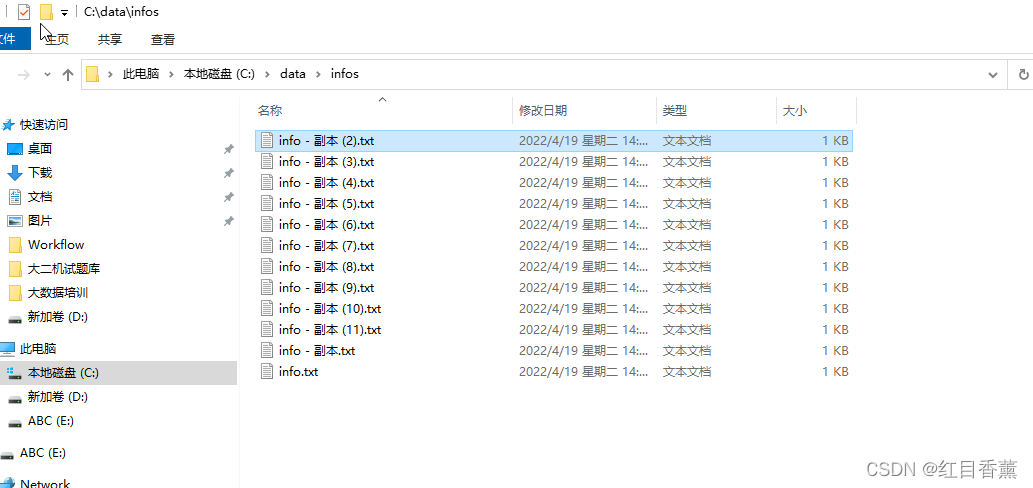
![]()
遍历【/data/下的所有文件】
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.permission.FsPermission;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
//查看根目录信息
RemoteIterator<LocatedFileStatus> listFiles = action.fs.listFiles(new Path("/data/infos/"),true);
while (listFiles.hasNext()){
LocatedFileStatus next = listFiles.next();
Path path = next.getPath();
long blockSize = next.getBlockSize();
FsPermission permission = next.getPermission();
long len = next.getLen();
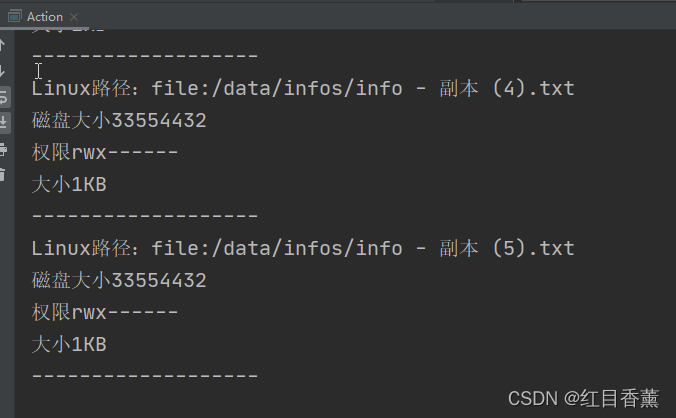
System.out.println("Linux路径:"+path);
System.out.println("磁盘大小"+blockSize);
System.out.println("权限"+permission);
System.out.println("大小"+len+"KB");
System.out.println("-------------------");
}
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
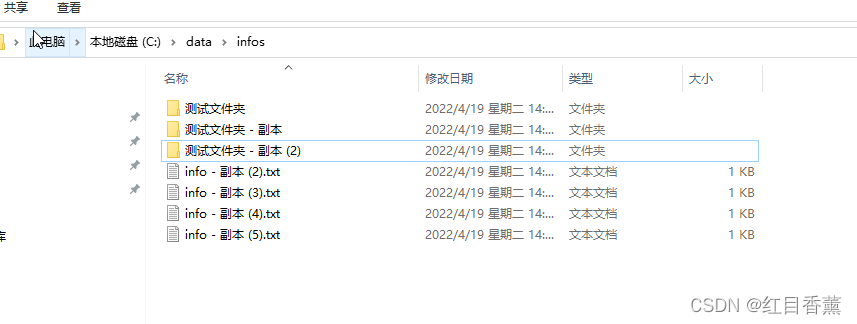
遍历文件以及文件夹listStatus:
![]()
编码:
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
//查看根目录信息
FileStatus[] fileStatuses = action.fs.listStatus(new Path("/data/infos/"));
for (FileStatus file:fileStatuses) {
if(file.isFile()){
System.out.println("文件"+file.getPath().getName());
}else{
System.out.println("文件夹"+file.getPath().getName());
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
效果:
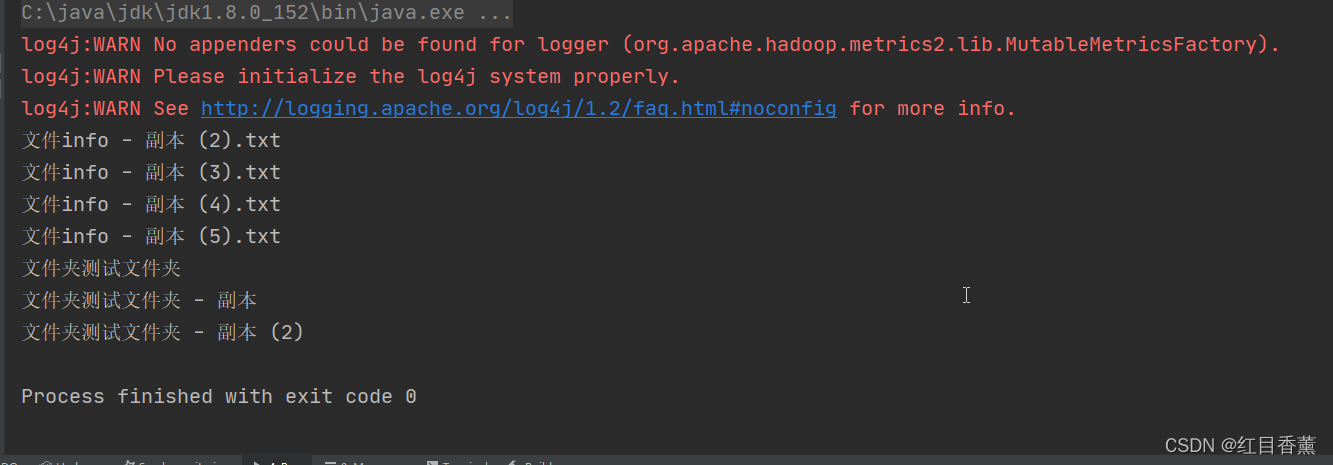
![]()
获取所有节点信息(win系统上看不到)
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
public class Action {
public static void main(String[] args) {
Action action = new Action();
action.init();
try {
DistributedFileSystem distributedFileSystem =
(DistributedFileSystem) action.fs;
DatanodeInfo[] datanodeInfos = distributedFileSystem.getDataNodeStats();
for (DatanodeInfo datanodeInfo : datanodeInfos) {
System.out.println(datanodeInfo.getHostName());
}
} catch (IOException e) {
e.printStackTrace();
}
}
Configuration conf = null;
FileSystem fs = null;
public void init() {
conf = new Configuration();
try {
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
HDFS 的设计特点
能够存储超大文件
流式数据访问
商用硬件
不能处理低时间延迟的数据访问
不能存放大量小文件
无法高效实现多用户写入或者任意修改文件

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)