Hadoop快速入门——第二章、分布式集群(第三节、HDFS Shell的常用命令)

【摘要】 Hadoop快速入门——第二章、分布式集群HDFS概述:在 2002 年,Google 发表的论文 GFS 中提到希望构建一个能够运行于商业硬件集群上的以流式数据访问形式存储超大文件的文件系统,HDFS 就是为了实现这一目标HDFS 的设计特点如下超大文件流式数据访问商用硬件不能处理低时间延迟的数据访问不能存放大量小文件无法高效实现多用户写入或者任意修改文件在 HDFS 中有一些特殊的...

![]()
Hadoop快速入门——第二章、分布式集群
HDFS概述:
在 2002 年,Google 发表的论文 GFS 中提到希望构建一个能够运行于商业硬件集群上的以流式数据访问形式存储超大文件的文件系统,HDFS 就是为了实现这一目标HDFS 的设计特点如下
- 超大文件
- 流式数据访问
- 商用硬件
- 不能处理低时间延迟的数据访问
- 不能存放大量小文件
- 无法高效实现多用户写入或者任意修改文件
在 HDFS 中有一些特殊的概念,需要特别重点的理解数据块:在普通的文件系统中,每个磁盘都有默认的数据块,这是磁盘进行数据读 / 写的最小单位NameNode:它是 Hadoop 的 HDFS 的核心组件,它维护着文件系统树和整棵树内所有的文件和目录DataNode: DataNode 是文件系统的工作节点,也就是数据节点,它根据存储需要检索数据块,并定期向 NameNode 发送它所存储的块的列表SecondNameNode: SecondNameNode 是对主 NameNode 的一个补充,它会周期地执行对 HDFS 元数据的检查点HDFS 的安全模式:在 NameNode 启动时,首先将镜像文件 fsimage 载入内存,并执行编辑日志 edits 中的各项操作n数据完整性:在 Hadoop 系统中检测数据完整性是一个常见的措施
常用命令:
hadoop fs -mkdir <paths>
示例:
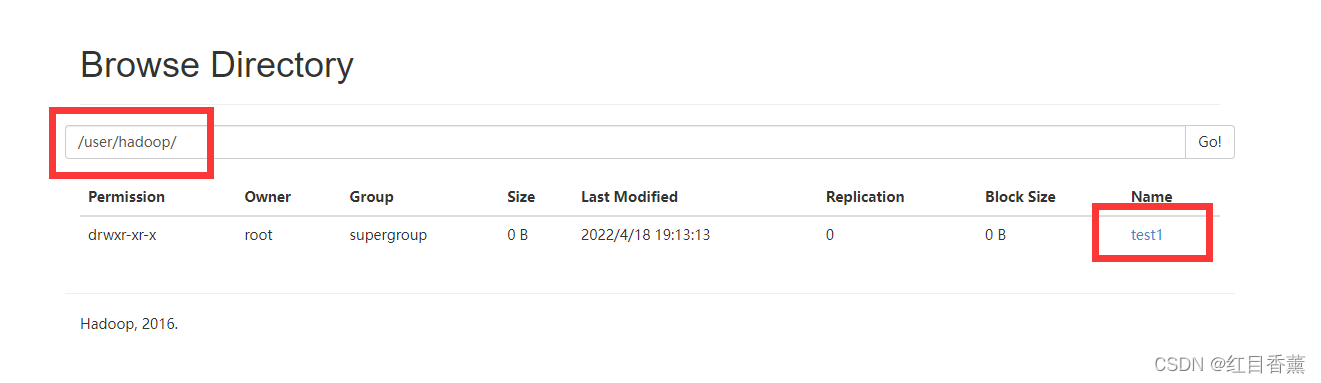
Mkdir:创建路径中的各级父目录(-p可以创建多级文件夹)
hadoop fs -mkdir -p /user/hadoop/test1
![]()
![]()
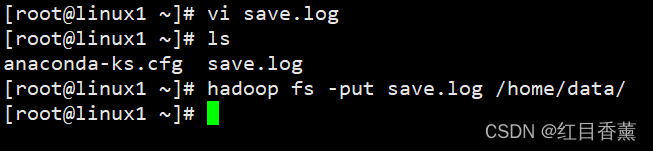
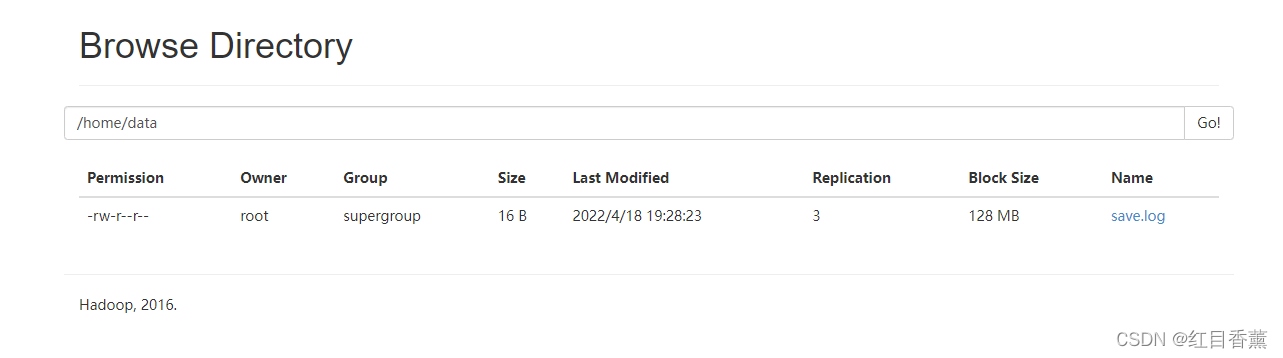
put:从本地文件系统中复制单个或多个源路径到目标文件系统。
![]()
![]()
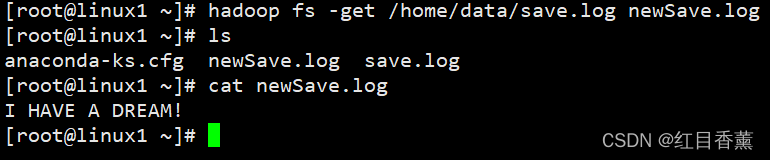
get:复制文件到本地文件系统
hadoop fs -get /home/data/save.log newSave.log
![]()
mv:移动文件
hadoop fs -mv /home/data/save.log /user/hadoop/newSave.log
![]()
![]()
cat:输出文件内容
hadoop fs -cat /user/hadoop/newSave.log
![]()
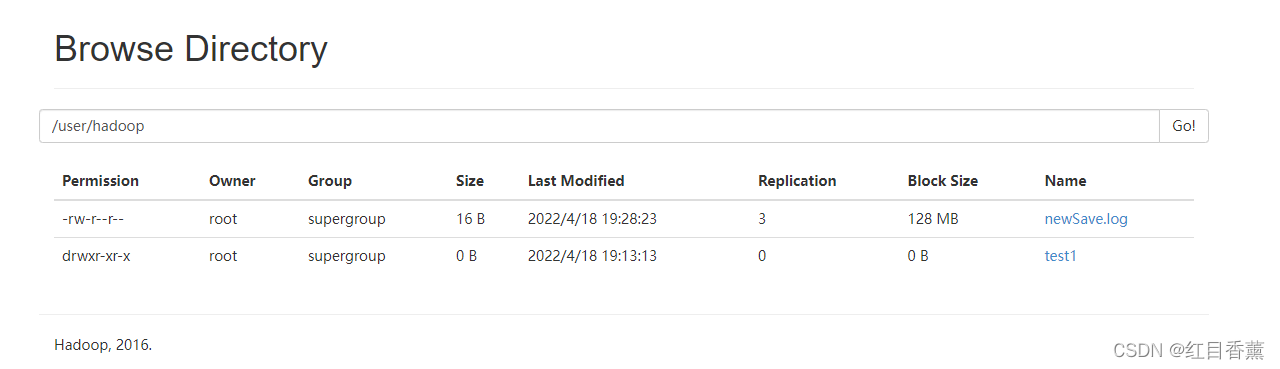
ls:返回文件或目录列表信息
hadoop fs -ls /user/hadoop/
![]()
ls -R:递归返回文件或目录列表信息
hadoop fs -ls -R /user
![]()
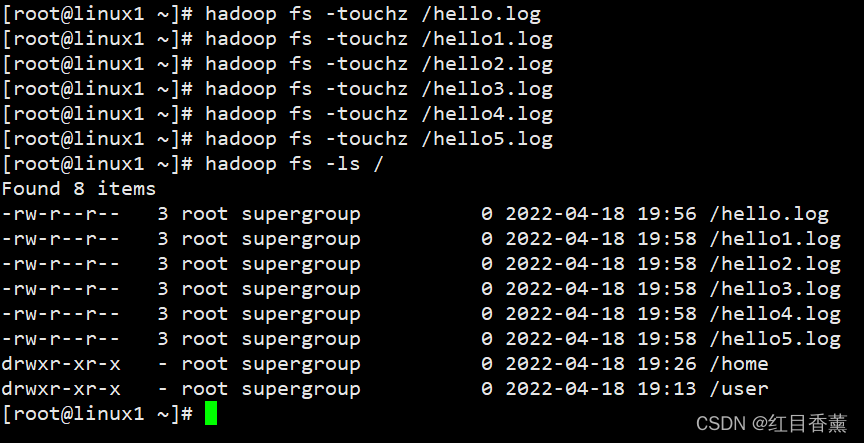
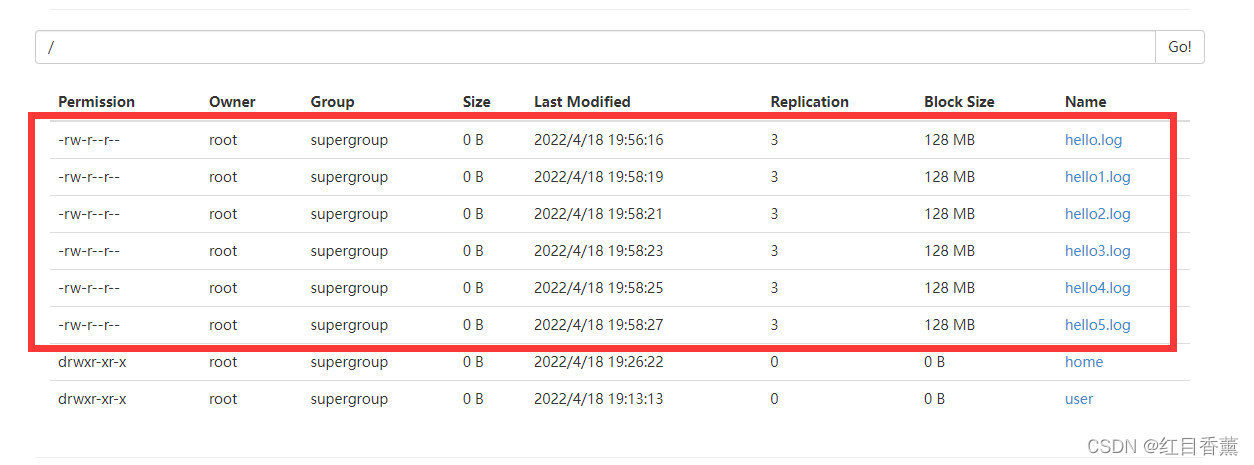
touchz:创建一个 0 字节的空文件
hadoop fs -touchz /hello1.log
hadoop fs -touchz /hello2.log
hadoop fs -touchz /hello3.log
hadoop fs -touchz /hello4.log
hadoop fs -touchz /hello5.log
![]()
![]()
chown:改变文件的拥有者
vi test.sh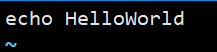
![]()
hadoop fs -put test.sh /home/test.sh
hadoop fs -ls /home/

![]()
修改用户,可以看到从【root】改为【hadoop】
hadoop fs -chown hadoop /home/test.sh
hadoop fs -ls /home/

![]()
tail :将文件尾部 1K 字节的内容输出
hadoop fs -tail /home/test.sh
![]()
rm -r:删除指定的文件
hadoop fs -rm /home/test.sh
![]()
删除后已经无法再次查看文件了。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)