Python基础——PyCharm版本——第八章、文件I/O(核心3、csv和excel解析)

【摘要】 🤵🤗Python_Base:Chapter eighth🤗🤵CSV前言CSV(Comma-Separated Values,中文逗号分隔值或字符分隔值)是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用,也应用于程序之间转移表格数据。CSV并不是一种单一的、定义明确的格式,泛指具有以下特征的任何文件: 纯文本,使用某个字符集,如ASCII、Unicode、EBCDIC...

🤵🤗Python_Base:Chapter eighth🤗🤵
CSV前言
CSV(Comma-Separated Values,中文逗号分隔值或字符分隔值)是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用,也应用于程序之间转移表格数据。
CSV并不是一种单一的、定义明确的格式,泛指具有以下特征的任何文件: 纯文本,使用某个字符集,如ASCII、Unicode、EBCDIC或GB2312。 由记录组成(典型的是每行一条记录)。 每条记录被分隔符分隔为字段(典型分隔符有逗号、分号或制表符;有时分隔符可以包括可选的空格)。 每条记录都有同样的字段序列。
数据格式
1 王语嫣 16 琅嬛福地,神仙姐姐
2 小龙女 17 终南山下,活死人墓,神雕侠侣,绝世江湖
3 赵灵儿 15 灵蛇岛,逍遥哥哥的小太妹
![]()
读取操作: (编码格式,通常使用utf-8,如果文件编码不符会报错)
import csv
# 文件获取
file = open('test.csv', 'r', encoding="utf-8")
# 内容读取
list1 = csv.reader(file)
# 信息遍历
for line in list1:
for item in line:
print(item, end=" ")
print()
写入操作:
import csv
# 文件获取
file = open('test.csv', 'w+', encoding="utf-8")
# 写入操作
writer = csv.writer(file)
# 按照行写入
writer.writerow(['1', '王语嫣', '16', "琅嬛福地,神仙姐姐"])
data = [('2','小龙女', '17', '终南山下,活死人墓,神雕侠侣,绝世江湖'),
('3','赵灵儿', '15', '灵蛇岛,逍遥哥哥的小太妹')]
# 写入多行记录
writer.writerows(data)
# 刷新文件
file.flush()
# 关闭文件流
file.close()
EXCEL前言
Python读写Excel文档需要安装和使用xlrd模块,Excel文件写入需要使用xlwt模块。
写入XLS
这里用到的包是:【import xlwt】
需要进行下载:【pip install xlwt】
import xlwt
# 创建内容的样式对象,包括字体样式以及数字的格式
wb = xlwt.Workbook()
ws = wb.add_sheet('Sheet1') # 添加一个sheet
# 需要将中文通过u""的形式转换为unicode编码
data = [[u"编号", u"姓名", u"年龄", u"简介"],
[1, u"王语嫣", 16, u"琅嬛福地,神仙姐姐"],
[2, u"小龙女", 17, u"活死人墓,冰山美人"],
[3, u"赵灵儿", 31, u"灵蛇岛上,戚戚艾艾"]
]
for i in range(0, data.__len__()): # 循环遍历每一行
for j in range(0, data[i].__len__()): # 循环遍历第i行的每一列
ws.write(i, j, data[i][j])
wb.save("test.xls")



能确定生成了【test.xls】文件,这里别写【xlsx】,因为【xlwt】不支持【xlsx】操作。
读取XLS
这里用到的包是:【import xlrd】
需要进行下载:【pip install xlrd】

![]()
测试表格(刚刚通过【xlwt】生成):
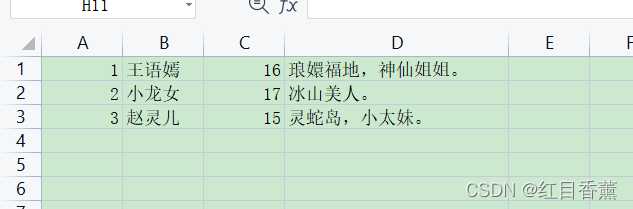
![]()
import xlrd
workbook = xlrd.open_workbook('test.xls') # 打开Excel文件读取数据
print(workbook.sheet_names()) # 获取所有sheet
# sheet2 = workbook.sheet_names()[0] #第一种方式,根据下标获取
sheet = workbook.sheet_by_index(0) # 第二种方式,根据sheet索引获取sheet对象,索引从0开始
sheet = workbook.sheet_by_name('Sheet1') # 第三种方式,根据sheet名称获取sheet对象
print(sheet.name, sheet.nrows, sheet.ncols) # sheet的名称、行数和列数
# 获取整行和整列的值(数组)
rows = sheet.row_values(2) # 获取第三行内容
cols = sheet.col_values(2) # 获取第三列内容
print(str(rows), '\n', cols)
# 获取单元格内容
print(sheet.cell(1, 0).value, end=" ")
print(sheet.cell_value(1, 0), end=" ")
print(sheet.row(1)[0].value, end=" ")
print(sheet.cell(1, 0).ctype) # 获取单元格内容的数据类型
print("\n--------------------------------------\n")
# 遍历
for row in sheet:
print(row[0], row[1], row[2], row[3])

![]()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)