Python基础——PyCharm版本——第八章、文件I/O(XML)

【摘要】 🤵🤗Python_Base:Chapter eighth🤗🤵前言XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。XML(Extensible Markup Language,可扩展标记语言)与JSON数据格式类似,用于提供数据表述格式,适用于不同应用程序间的数据交换。 XML是一套定义语义标记的规则,同时也是用于定义...

🤵🤗Python_Base:Chapter eighth🤗🤵
前言
XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。
XML(Extensible Markup Language,可扩展标记语言)与JSON数据格式类似,用于提供数据表述格式,适用于不同应用程序间的数据交换。 XML是一套定义语义标记的规则,同时也是用于定义其他标识语言的元标识语言。 Python有三种解析XML的方式,分别为SAX、DOM以及ElementTree。
现阶段主要是对XML做读取操作:
XML结构示例:
<?xml version="1.0" encoding="utf-8" ?>
<users>
<user>
<id>1</id>
<userName>admin</userName>
<passWord>123456</passWord>
<introduce>管理员</introduce>
</user>
<user>
<id>2</id>
<userName>likes</userName>
<passWord>123456</passWord>
<introduce>爱好</introduce>
</user>
<user>
<id>2</id>
<userName>王语嫣</userName>
<passWord>123456</passWord>
<introduce>琅嬛福地,神仙姐姐。</introduce>
</user>
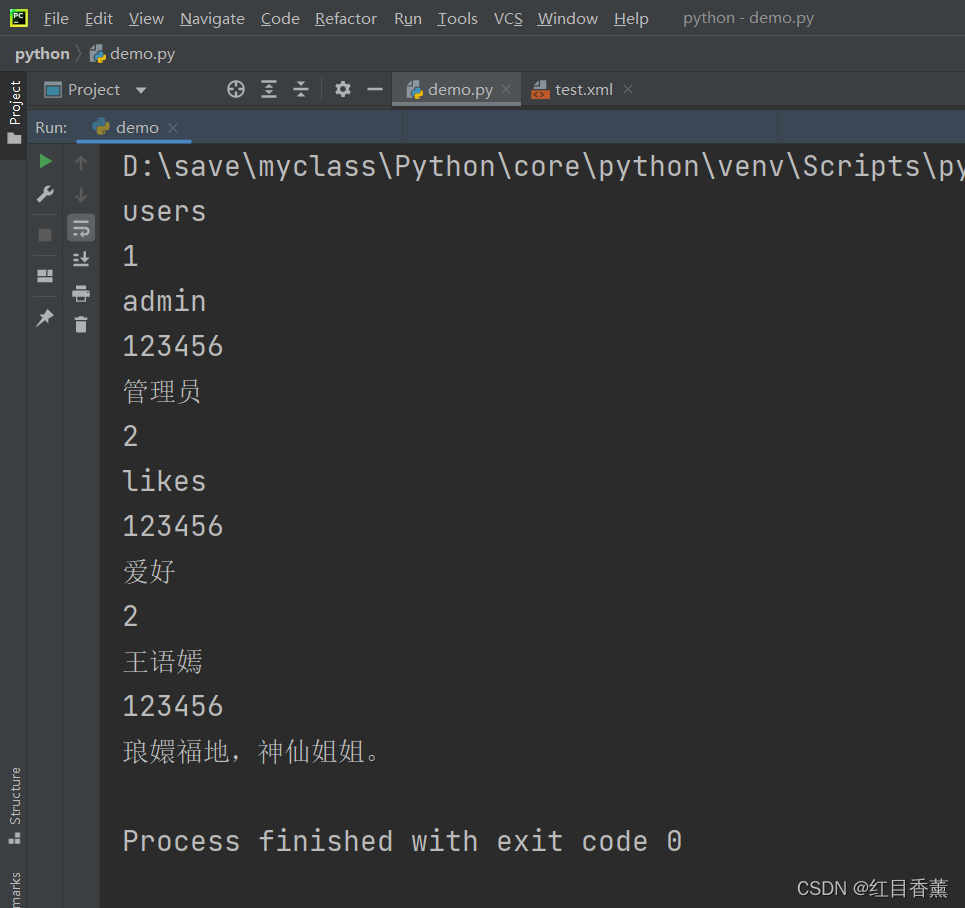
</users>读取示例:
from xml.dom import minidom as getDom
# 获取xml操作文件信息
dom = getDom.parse("test.xml")
# 获取dom元素
root = dom.documentElement
# 根节点名称
print(root.nodeName)
# 根据dom元素获取根节点下所有的一级子节点
lists = root.getElementsByTagName("user")
# 遍历一级子节点的过程中便可以获取数据
for u in lists:
print(u.getElementsByTagName("id")[0].firstChild.data)
print(u.getElementsByTagName("userName")[0].firstChild.data)
print(u.getElementsByTagName("passWord")[0].firstChild.data)
print(u.getElementsByTagName("introduce")[0].firstChild.data)
![]()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)