R 银行信用卡风控评分数据分析

【摘要】 R 银行信用卡风控评分数据分析
1 初始环境准备
读取数据与预览
rm(list=ls())
#setwd("./case")
#install.packages("xlsx")
library(openxlsx)
dat<-read.xlsx("credit.xlsx",1)
View(dat)
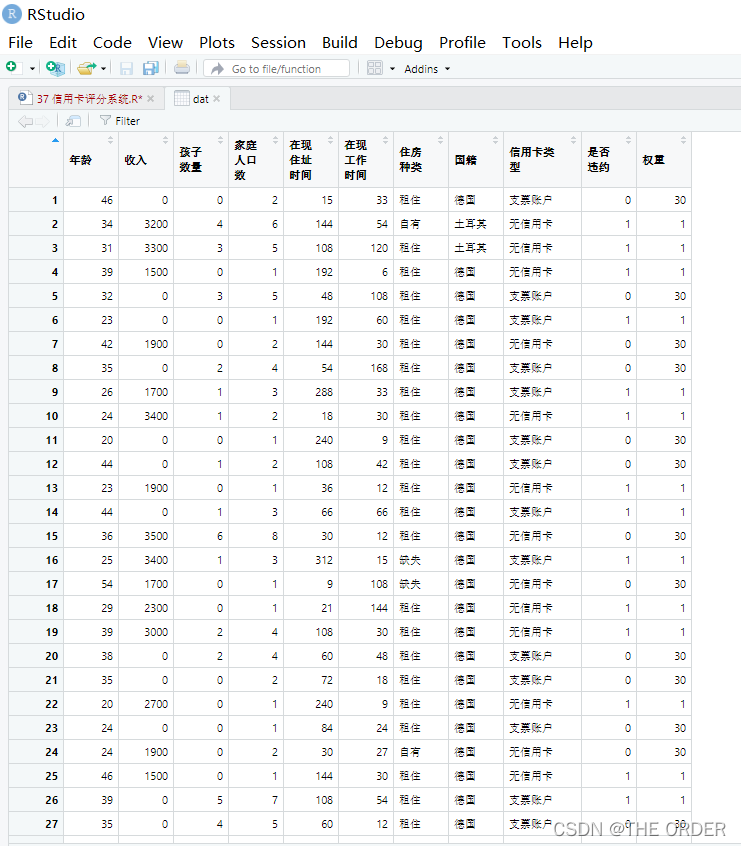
2数据预览与处理
数据预览,发现最大值999的异常值,偏离平均值
class(dat)
#describe data
summary(dat)
sum(is.na(dat))
异常值处理,使用na填充
#Outlier filling
dat[,1:6]<-sapply(dat[,1:6],function(x) {x[x==999]<-NA;return(x)} )
nrow(dat)
ncol(dat)
summary(dat[,11])
#Understand data deletion invalid variables
dat<-dat[,-11]
将字符型变量character转化为因子变量factor
#Change string variable type to classification variable
dat1<-dat
sapply(dat1,class)
ch=names(which(sapply(dat1,is.character)))#find the character type variance
dat1[,ch]=as.data.frame(lapply(dat1[,ch], as.factor))
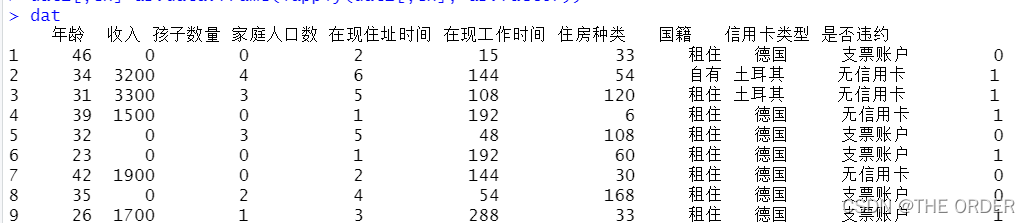
观察数据发现家庭人口数和家庭孩子数密切相关,存在多重共线性,于是产生标识变量代替这二个变量
dat1[,4]<-dat1[,4]-dat1[,3]
table(dat1[,4])
dat1[,4]<-factor(dat1[,4],levels=c(1,2),labels=c("其他","已婚"))
colnames(dat1)<-c("age","income","child","marital","dur_live",
"dur_work","housetype","nation","cardtype","loan")
summary(dat1)
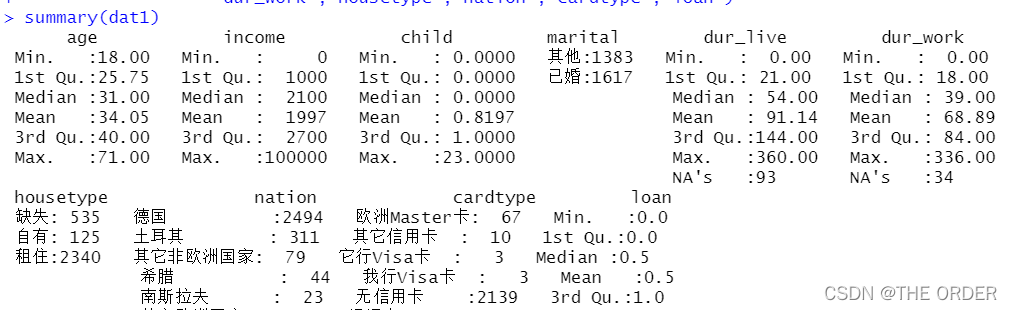
3 描述性统计
相关包准备
#install.packages("smbinning")
#install.packages("prettyR")
library(smbinning)
library(prettyR)
library(mvtnorm)
library(kernlab)
盖帽法
异常值可以使用盖帽法处理,使用1%和99%分位数替换异常值
##盖帽法函数 去除异常用99%和1%点分别代替异常值
block<-function(x,lower=T,upper=T){
if(lower){
q1<-quantile(x,0.01)
x[x<=q1]<-q1
}
if(upper){
q99<-quantile(x,0.99)
x[x>q99]<-q99
}
return(x)
}
数据集中1是不违约,0是违约,进行反转设定,使1变为违约,0为不违约
#Odds ratio conversion for later IV calculation
dat1$loan<-as.numeric(!as.logical(dat1$loan))
描述数据分类统计
违约和不违约的人群的区别
#data classification ,discretization of continuous variables
##age
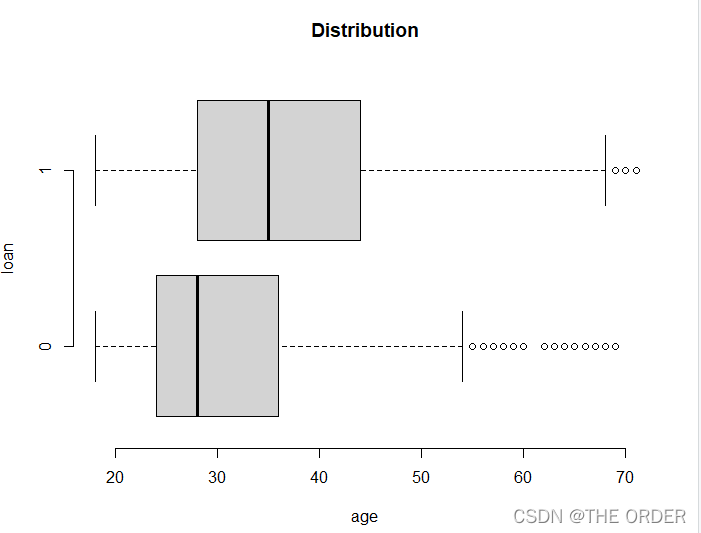
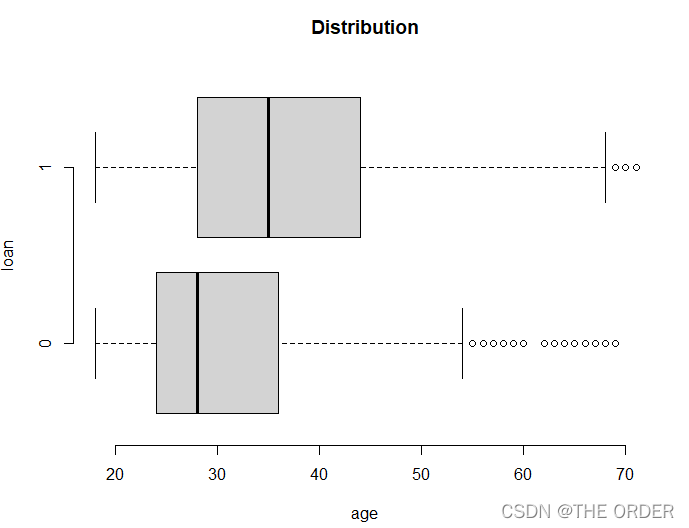
boxplot(age~loan,data=dat1,horizontal=T, frame=F,
col="lightgray",main="Distribution")
age<-smbinning(dat1,"loan","age")
age$ivtable
违约与否的年龄箱线图
分箱后的IV图
age<-smbinning(dat1,"loan","age")
age$ivtable
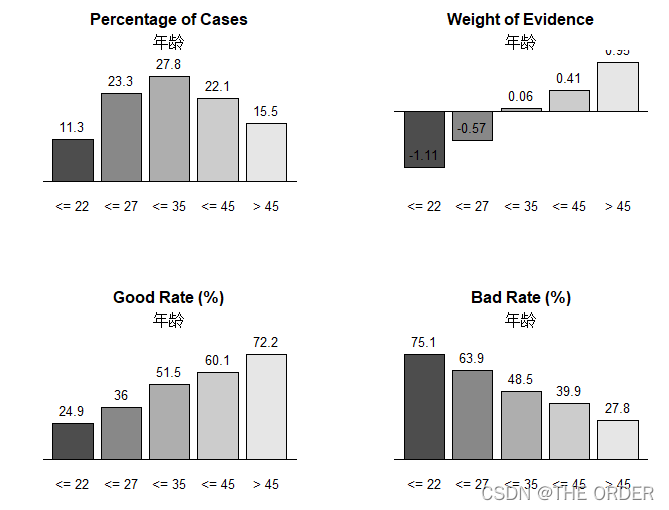
对年龄进行分箱后,查看百分比,weight,good,bad rate,后面的描述性统计大致如此,可以秦楚看出不同年龄层次的区别
par(mfrow=c(2,2))
smbinning.plot(age,option="dist",sub="年龄")
smbinning.plot(age,option="WoE",sub="年龄")
smbinning.plot(age,option="goodrate",sub="年龄")
smbinning.plot(age,option="badrate",sub="年龄"
将IV结果添加到一个向量中
par(mfrow=c(1,1))
age$iv
#Add Iv value to vector
cred_iv<-c("年龄"=age$iv)

关于收入,明显存在异常值,使用盖帽法
##income
boxplot(income~loan,data=dat1,horizontal=T, frame=F,
col="lightgray",main="Distribution")
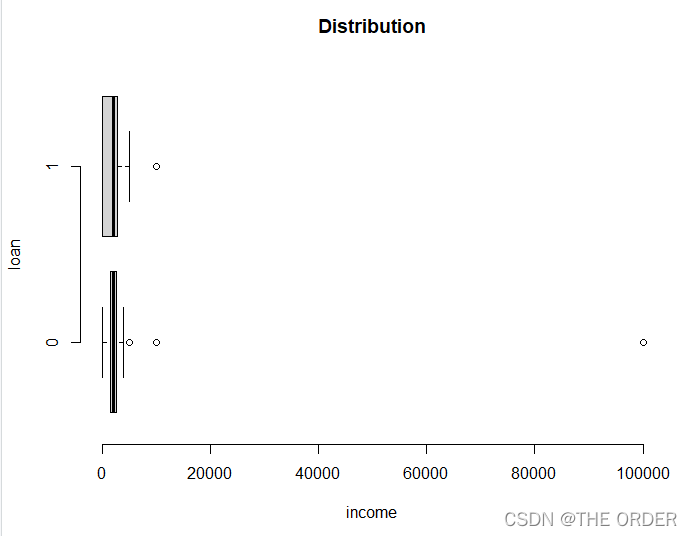
盖帽法填充
dat1$income<-block(dat1$income)
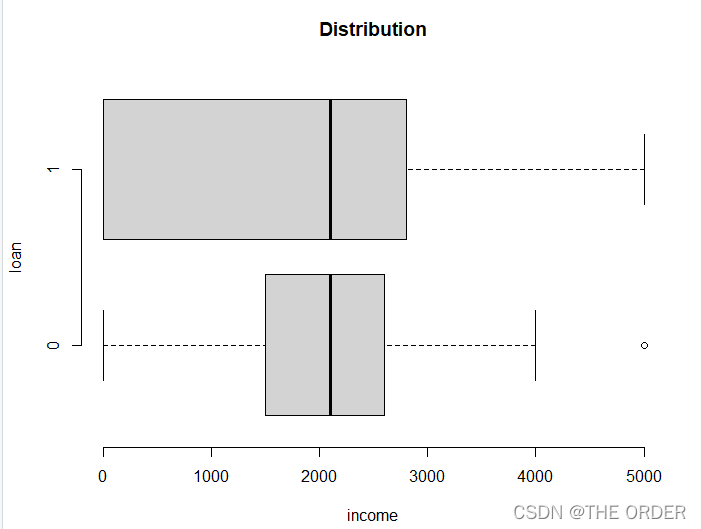
填充后明显变正常了
boxplot(income~loan,data=dat1,horizontal=T, frame=F,
col="lightgray",main="Distribution")
```
IV值测量,同上age
income<-smbinning(dat1,"loan","income")
income$ivtable
smbinning.plot(income,option="WoE",sub="收入")
income$iv
cred_iv<-c(cred_iv,"收入"=income$iv)
child 统计
##child
boxplot(child~loan,data=dat1,horizontal=T, frame=F,
col="lightgray",main="Distribution")
child<-smbinning(dat1,"loan","child")
child$ivtable
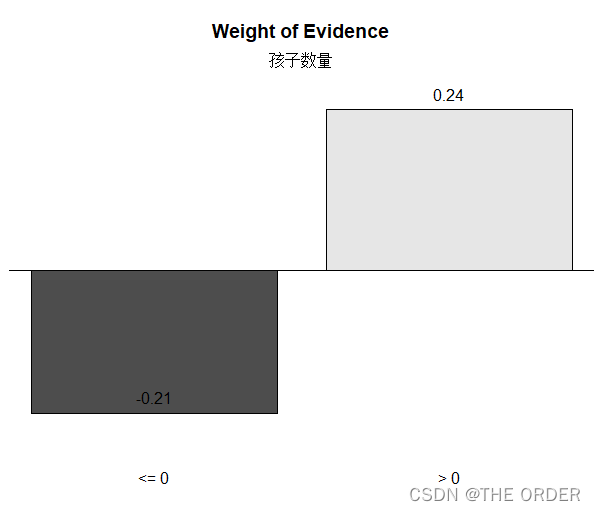
smbinning.plot(child,option="WoE",sub="孩子数量")
child$iv
cred_iv<-c(cred_iv,"孩子数量"=child$iv)
##marital
xtab(~marital+loan,data=dat1,chisq=T)
marital<-smbinning.factor(dat1,"loan","marital")
marital$ivtable
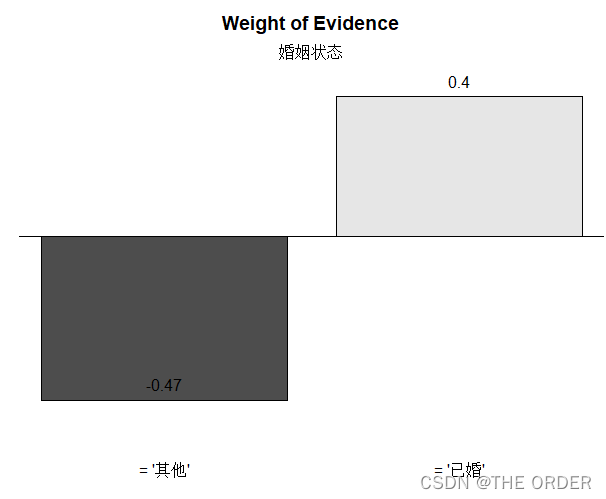
smbinning.plot(marital,option="WoE",sub="婚姻状态")
marital$iv
cred_iv<-c(cred_iv,"婚姻状态"=marital$iv)
##dur_live
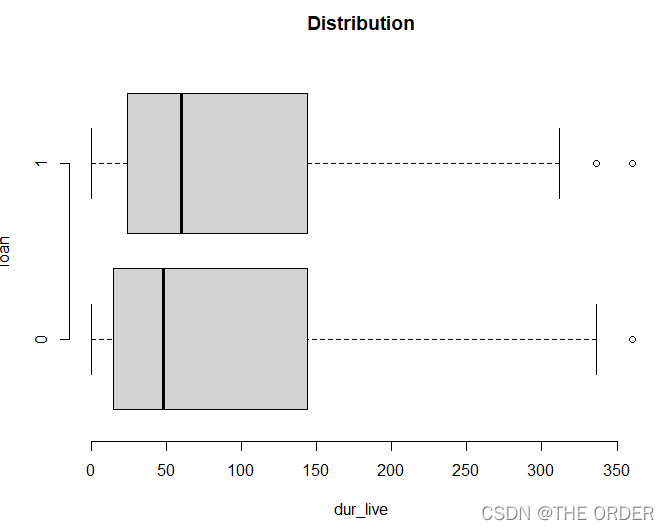
boxplot(dur_live~loan,data=dat1,horizontal=T,
frame=F, col="lightgray",main="Distribution")
t.test(dur_live~loan,data=dat1)
dur_live<-smbinning(dat1,"loan","dur_live")
dur_live
观察得到dur_live变量对违约分布区别不大,使用t检验,不能拒绝二者同分布

dur_work变量统计
##dur_work
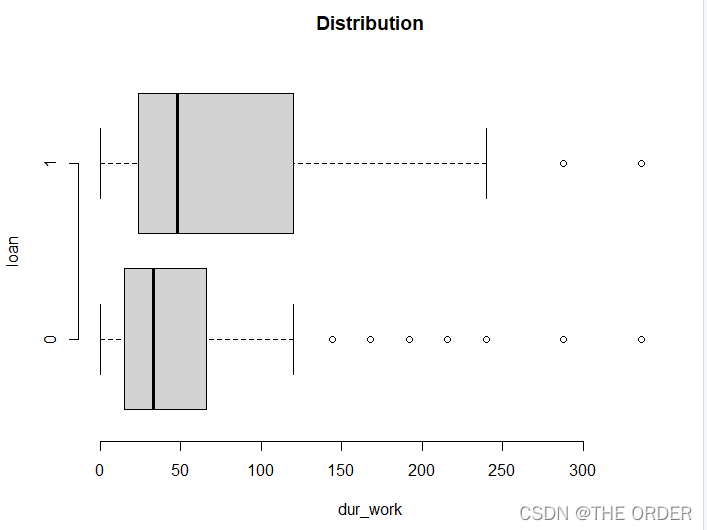
boxplot(dur_work~loan,data=dat1,horizontal=T,
frame=F, col="lightgray",main="Distribution")
t.test(dur_work~loan,data=dat1)
dur_work<-smbinning(dat1,"loan","dur_work")
dur_work$ivtable
smbinning.plot(dur_work,option="WoE",sub="在现工作时间")
dur_work$iv
cred_iv<-c(cred_iv,"在现工作时间"=dur_work$iv)
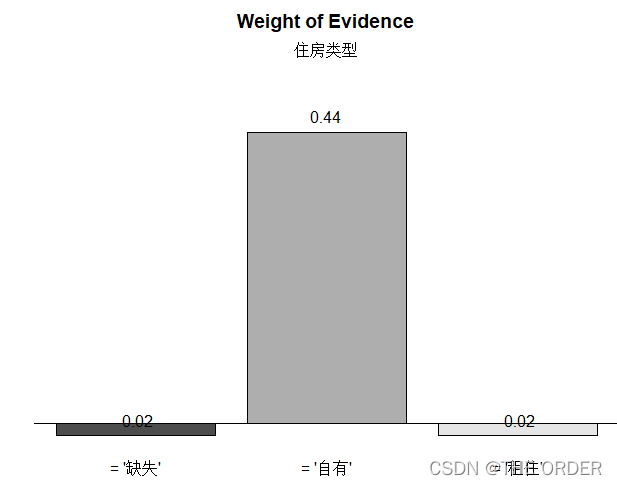
housetype描述统计
##housetype
xtab(~housetype+loan,data=dat1,chisq=T)
housetype<-smbinning.factor(dat1,"loan","housetype")
housetype$ivtable
smbinning.plot(housetype,option="WoE",sub="住房类型")
housetype$iv
cred_iv<-c(cred_iv,"住房种类"=housetype$iv)
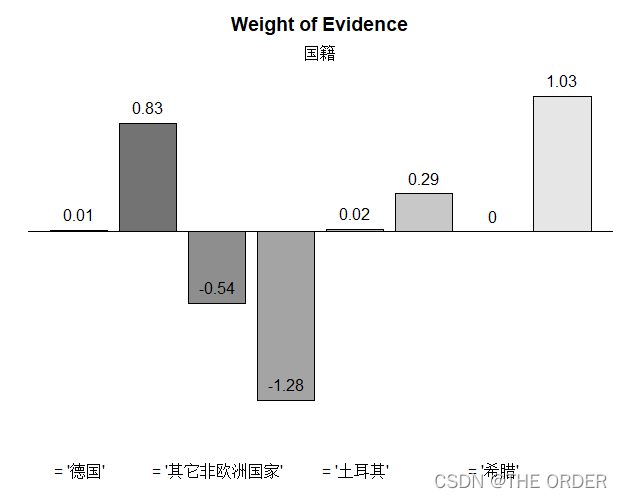
##nation
xtab(~nation+loan,data=dat1,chisq=T)
nation<-smbinning.factor(dat1,"loan","nation")
nation$ivtable
smbinning.plot(nation,option="WoE",sub="国籍")
nation$iv
cred_iv<-c(cred_iv,"国籍"=nation$iv)
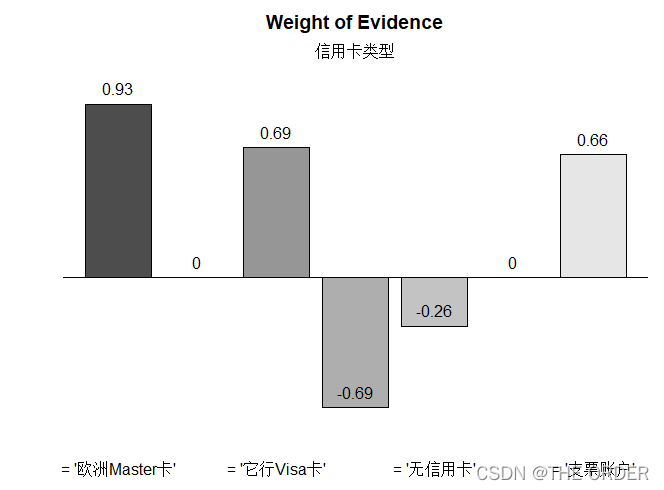
cardtype描述统计
##cardtype
xtab(~cardtype+loan,data=dat1,chisq=T)
cardtype<-smbinning.factor(dat1,"loan","cardtype")
cardtype$ivtable
smbinning.plot(cardtype,option="WoE",sub="信用卡类型")
cardtype$iv
cred_iv<-c(cred_iv,"信用卡类型"=cardtype$iv)
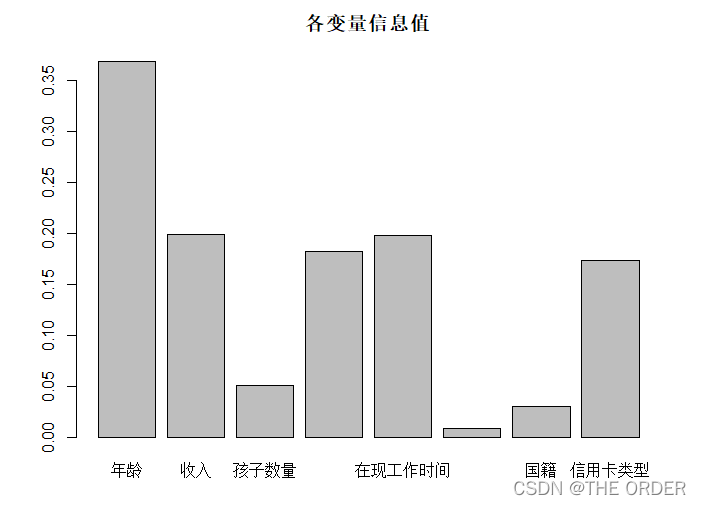
总体变量IV值程度
#Drawing shows the amount of information
barplot(cred_iv,main="各变量信息值")
4 属性分箱
#quantity after adding classification
dat2<-dat1
dat2<-smbinning.gen(dat2,age,"glage")
dat2<-smbinning.gen(dat2,income,"glincome")
dat2<-smbinning.gen(dat2,child,"glchild")
dat2<-smbinning.factor.gen(dat2,marital,"glmarital")
dat2<-smbinning.gen(dat2,dur_work,"gldur_work")
dat2<-smbinning.factor.gen(dat2,housetype,"glhousetype")
dat2<-smbinning.factor.gen(dat2,nation,"glnation")
dat2<-smbinning.factor.gen(dat2,cardtype,"glcardtype")
View(dat2)

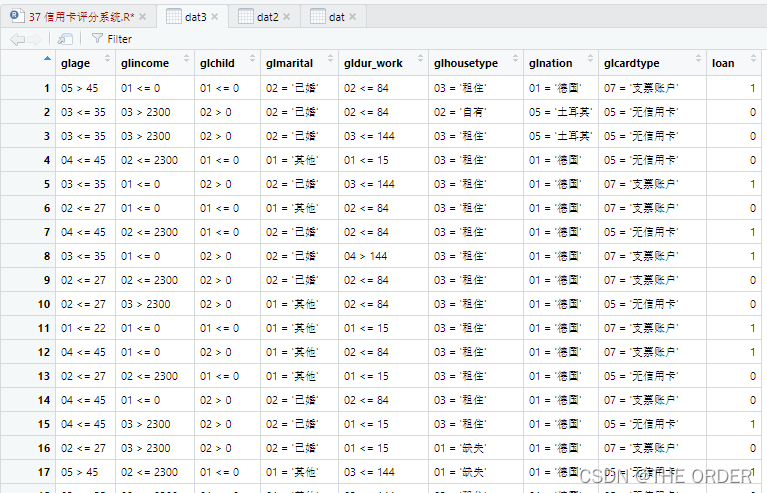
dat3<-dat2[,c(11:18,10)]
View(dat3)
生成分箱后的数据级,将用户属性转化为区间数据
5 logistic建模
具体打分理论参考
模型生成
#Creat logistic regression
cred_mod<-glm(loan~. ,data=dat3,family=binomial())
summary(cred_mod)

6 打分系统
依照打分公式发现,信用最高评分和最低评分分别为797,362
#Scoring card system
cre_scal<-smbinning.scaling(cred_mod,pdo=45,score=800,odds=50)
cre_scal$logitscaled
cre_scal$minmaxscore
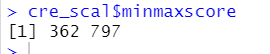
违约过与否的箱线图
#Score each item
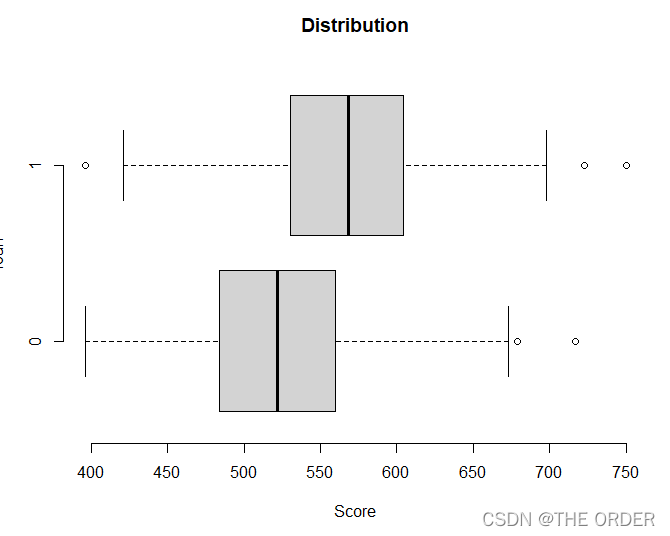
dat4<-smbinning.scoring.gen(smbscaled=cre_scal, dataset=dat3)
boxplot(Score~loan,data=dat4,horizontal=T, frame=F,
col="lightgray",main="Distribution")
生成打分指标
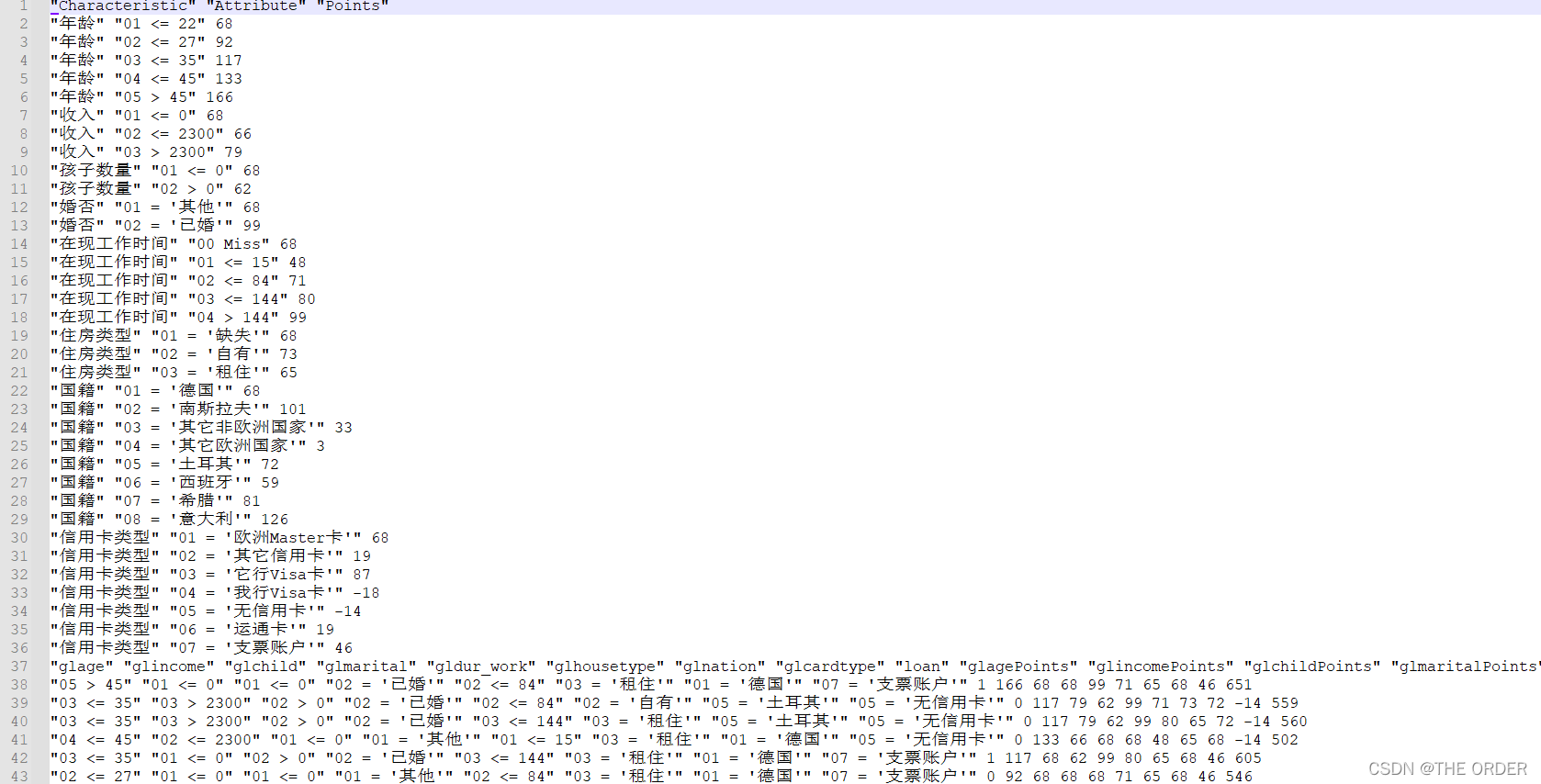
#Standardized scoring table
scaledcard<-cre_scal$logitscaled[[1]][-1,c(1,2,6)]
scaledcard[,1]<-c(rep("年龄",5),rep("收入",3),rep("孩子数量",2),
rep("婚否",2),rep("在现工作时间",5),
rep("住房类型",3),rep("国籍",8),rep("信用卡类型",7))
scaledcard
7 写入csv文件
ncol(dat4)
dat5=dat4[,10:18]
#write the results
write.table(scaledcard,"card.csv",row.names = F)
write.table(dat4,"card.csv",row.names = F,append = T)
?write.csv
输出文件给业务人员

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)