CRM and Credit Risk介绍

1 CRM
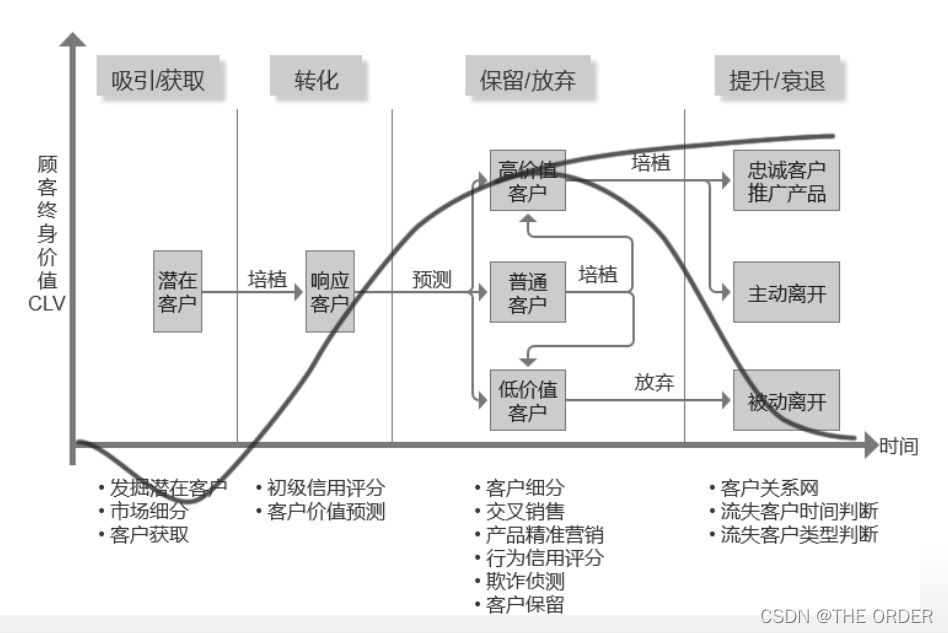
客户生命周期
客户生命周期(customer life cycle)的概念来自客户关系管理(CRM: Customer Relationship Management)的实践中,用来描述客户在接受不同产品或者服务的时候所要经历的阶段.包括考虑阶段,购买阶段,购买后的行为阶段(这个阶段会引入客户持久度、忠诚度以及拥护度等概念)
顾客终身价值(CLV:Customer Lifetime Value)的概念,是指客户在未来整个客户生命周期中产生的总价值,CLV可以作为衡量客户关系水平的一个指标
顾客在不同的阶段会产生不同的价值,转化期之前企业投入营销成本,顾客产生的价值是负的,随着顾客和企业关系的稳固和成熟,产生的价值越来越多,也就是说越晚流失客户对于一个企业来说产生的损失越少.所以企业应该关注选取适当客户,减少客户的流失率,采取保留客户的策略以及交叉销售的策略.同样的在保留/放弃阶段企业应该对客户做出选择性保留,以达到收益最大化
客户关系管理(CRM:Customer Relationship Management)是指企业在面对长期的客户关系的过程中提升企业成功的管理方式
客户是企业的重要资产,开发一个新客户的成本普遍高于保留一个老客户的成本,所以与高价值客户保持长期稳定的关系是企业获得持续竞争优势的关键
客户关系管理的目标是协助企业的销售管理,运用市场营销工具,向客户提供创新优质的个性化服务,提升老客户的满意度和忠诚度,以增加企业的经营效益,并辅以相应的数据挖掘技术和数据库营销技术来协调企业与客户间的关系交互
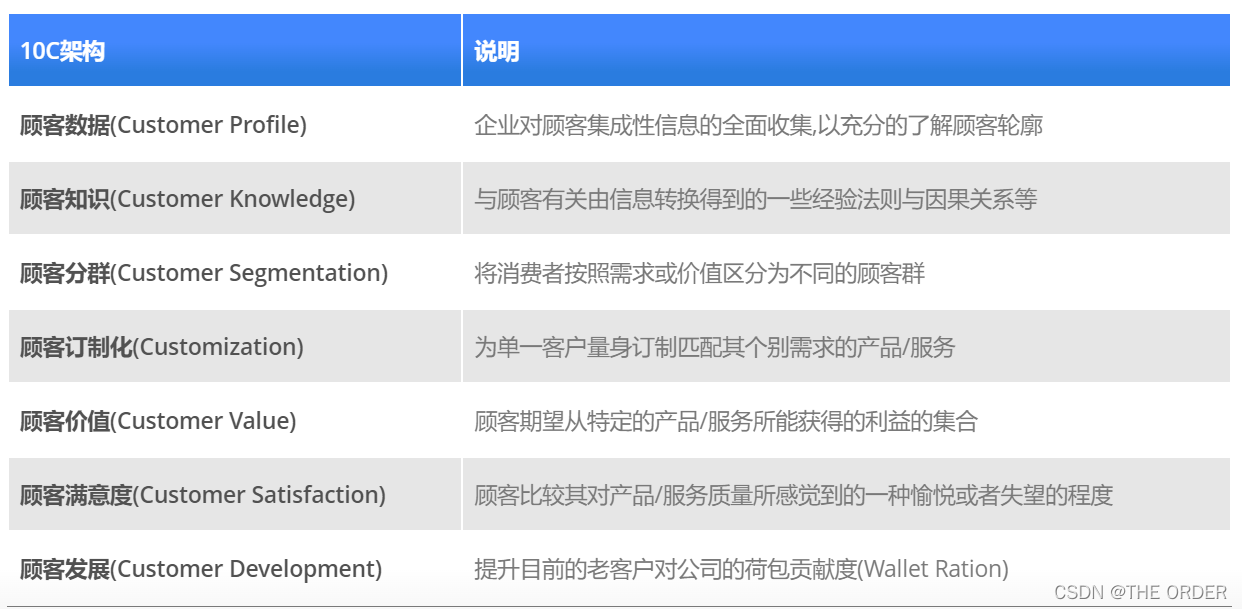
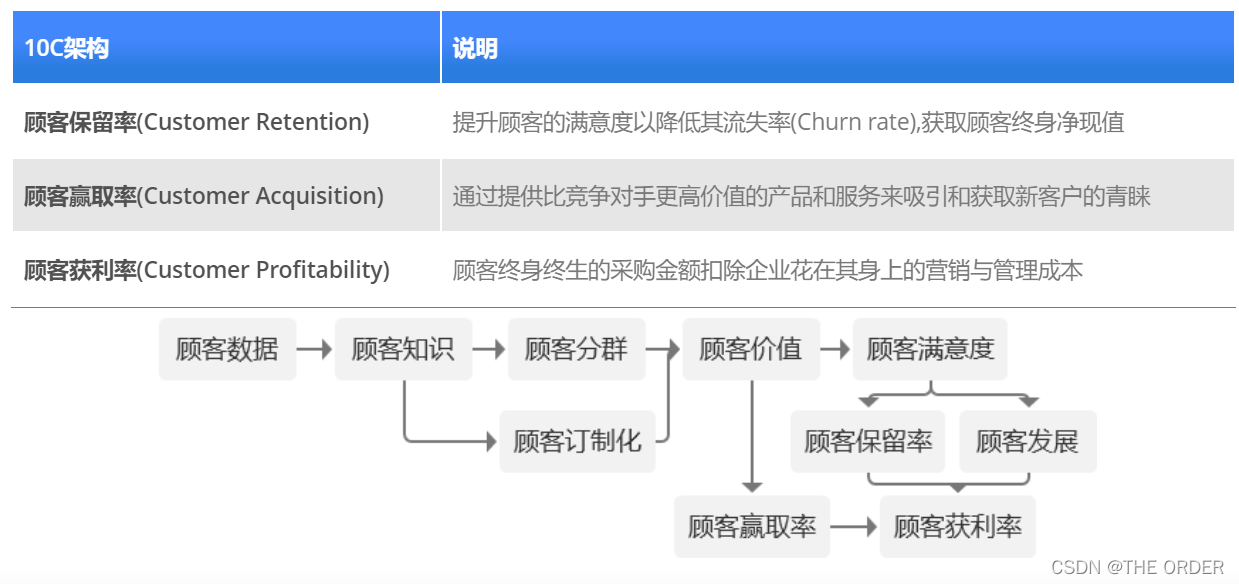
2 CRM手段和目的(10C架构)
3 客户信息
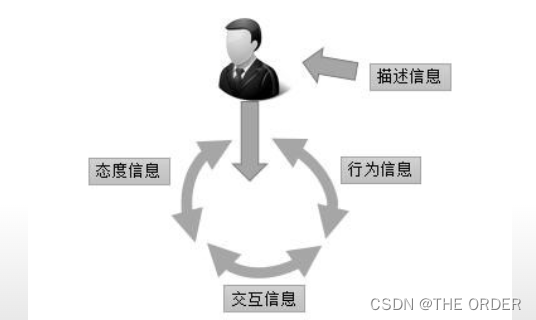
客户信息的收集主要用于客户分析,客户分析的目标是找到一个单一准确的视角来制定策略,从而最优化的获取和保留客户,定义高价值客户
描述信息:客户的基本属性信息,包括人口统计学的信息诸如性别,年龄,地理位置和收入;也包括自我描述类信息,对于产品的偏好和评价信息.从这些数据中可以细分出关于客户的有用的特征和分类,例如早期采用者(在产品介绍期和成长期采用新产品,对后面的采用者影响很大),性价比追求者或特定的顾客角色.这些信息可以来自买卖信息,注册记录,调查,回访,情景访谈.这类信息一般易采集,但是质量难以保证
行为信息:客户的行为信息,即客户在使用产品和服务的时候表现出来的一般的模式;包括购买行为,注册,浏览以及使用不同的设备等.例如经调查发现一些特定产品分类(消费性电子产品,家具)的顾客,晚上倾向于使用平板电脑购买,而白天倾向于使用台式机购买.行为信息的特点在于实时采集,需要整合汇总
交互信息:客户和网站的交互信息,包含网站或者软件的点击信息,导航路径以及浏览行为.主要用途在于网站或软件实用性能测试,例如通过模拟真实的交互得到点击间隔对应的等级.收集数据的途径有:A/B测试,谷歌分析师(Google Analytics),实验室收集等
态度信息:客户偏感性的信息,例如偏好,选择,愿望,品牌认可度及情怀等;可以通过调查问卷,特定关注群体的调查以及使用性测试等获得.一些知名的调查问卷公司常用来量化行为和交互信息对态度信息的影响.这些态度可能会影响描述信息中的量化的某些自我描述信息
4 Credit Risk
FICO信用评分考虑因素

分类:偿还历史35%,信用账户数30%,信用年限15%,新开账户10%,信用类型10%
评分的分类依据是基于一般个体中各个分类的重要性,对于特定的群体(例如刚开始使用信用卡的人群),每个分类的重要性可能会不同
5 信用评分卡
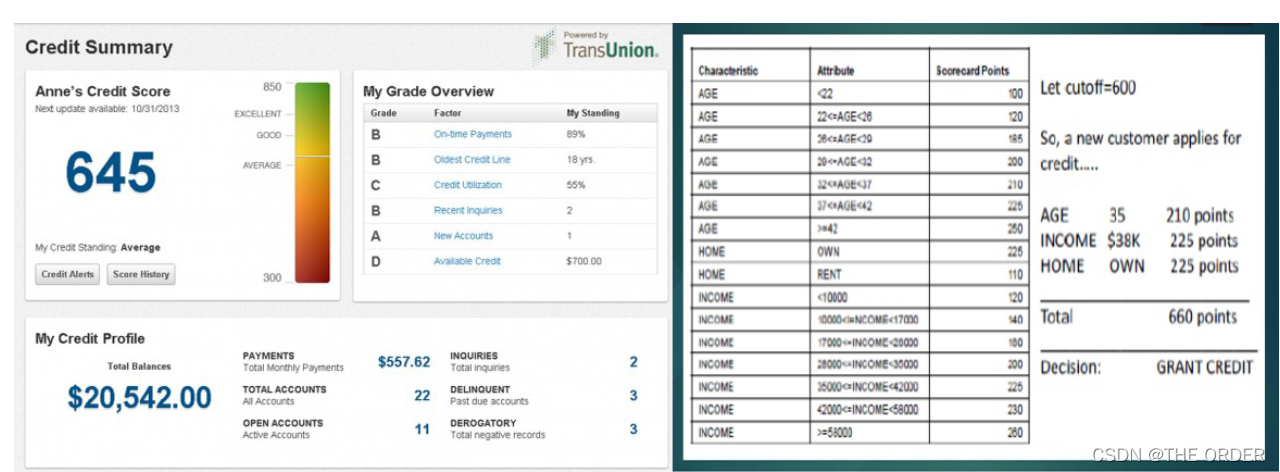
作用:1.决策类:是否放贷,是否同意信用卡申请;2.数额类:放贷额度,信用卡额度
优点:1.便于业务人员傻瓜式操作;2.便于监管部门监管(防止性别种族的歧视);3.易监控和调整
6 商业理解
定义目标变量,即定义好坏客户:拖欠还贷按照拖欠期长短可以分为:拖欠少于30天(1个月),31-60天(2个月),61-90天(3个月);拖欠180天以上基本认为是坏账
扩大市场占有率:容忍度高,可以把"坏"的拖欠期定义的长些,比如3个月以上
稳定发展业务,扩大利润:减少坏账发生,"坏"的拖欠期定义的短些(比如1个月以上)
拖欠一个月和拖欠两个月的客户信用情况认为差异比较大,在数据允许的情况下(1-2月客户占比不大),可将1-2月客户数据删除
获取数据:1. 通过办理前(贷前)填写资料得到的申请评分;2. 办理后(贷中)表现的行为特征产生的行为得分.
多个模型:不同产品,不同群体,均应对应特定的信用评分模型
7 建模流程和统计量
建立评分模型基本流程
输入变量的分箱
建模,一般使用logistic回归建立模型
指定业务参数将logistic回归系数转化为评分
模型检验
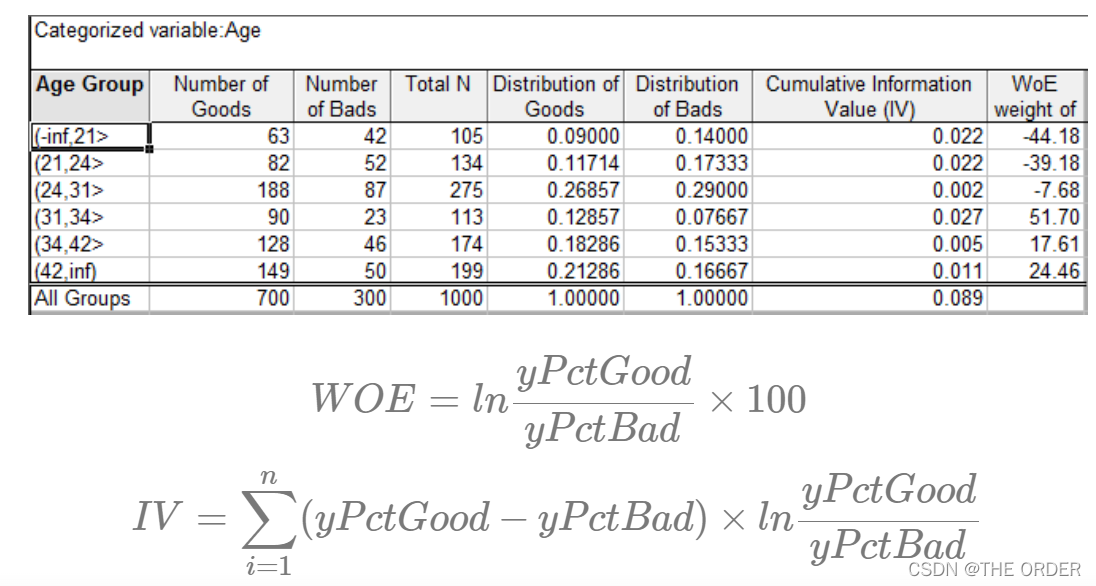
WOE(Weight of Evidence):证据权重,与违约比例同方向变动,可以看到不同分箱的重要性
IV(information Value):信息值,表示变量的重要性.
IV<0.02,对预测几乎无帮助;0.02≤IV<0.1,具有一定帮助
0.1≤IV<0.3,对预测有较大帮助;IV≥0.3,具有很大帮助
8 WOE和IV
WOE分箱原则
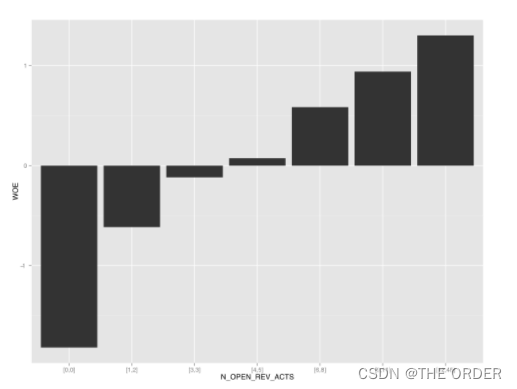
分箱数适中,不宜过多过少
各个分箱内记录数合理
分箱应该体现出明显的趋势特性
相邻分箱的差异不宜过大
9 生成信用评分模型
评分需要控制在一定范围内(例如0-1000)
对于特定分数,好客户和坏客户有一定的比例关系,即优比(odds),odds=xPctGoodxPctBad,例如800分时比值是50:1
增加一定评分值时优比增加一倍,例如增加45分,odds增加一倍(从50:1到100:1)
Score=Offset+Factor×ln(odds)Score+pdf=Offset+Factor×ln(2×odds)
pdo:points to double the odds
初始化: 例如Score=800对应odds=50,pdo=45.
即可算出对应的Offset和Factor
10 各分类评分
Logistic逻辑回归得到的回归方程左边Logit§=ln(odds),代入上页的信用评分方程式:
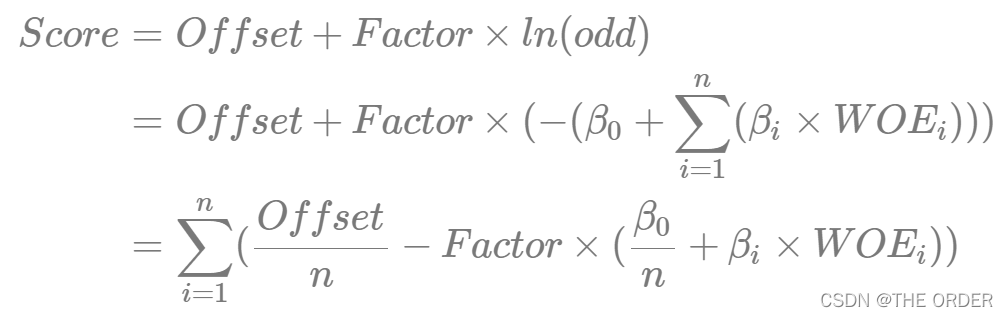

- 点赞
- 收藏
- 关注作者
评论(0)