python数据分析基础001-利用pandas玩转excel表格(5)

🐚作者简介:苏凉(专注于网络爬虫,数据分析)
🐳博客主页:苏凉的博客
👑名言警句:海阔凭鱼跃,天高任鸟飞。
📰要是觉得博主文章写的不错的话,还望大家三连支持一下呀!!!
👉关注✨点赞👍收藏📂

🍺前言
在数据分析中我们可以利用pandas对excel表格进行操作,包括对excel的创建,修改和读取等等。接下来我们一起来学习如何利用pandas对excel表格操作吧!!
🔅(一)读取其他文件
接下来我们读取三类文件==csv== ==tsv== ==txt==文件,值得注意的是读取这三类文件时使用的都是同一个方法,即pd.read_csv(file),在读取时为excel表时需注意分隔符,使用参数sep=’'来分隔。接下来我们一起看看在excel和pandas种如何操作的吧!
💨1.excel读取其他文件
从excel中导入外部数据

💦1.1 导入csv文件
导入csv文件时,分隔符选择逗号即可。

💦1.2 导入tsv文件
导入tsv文件,分隔符选择tab键

💦1.3 导入txt文本文件
导入txt文件时,注意文本里是以什么符号分隔的,自定义分隔符。

💨2.pandas读取其他文件
在pandas中为无论是读取csv文件还是tsv文件亦或者txt文件,都是用read_csv()的方法读取,另外加上sep()参数来分隔。
💦2.1 读取csv文件
import pandas as pd
# 导入csv文件
test1 = pd.read_csv('./excel/test12.csv',index_col="ID")
df1 = pd.DataFrame(test1)
print(df1)
💦2.2 读取tsv文件
tab键用 ==\t== 来表示
import pandas as pd
# 导入tsv文件
test3 = pd.read_csv("./excel/test11.tsv",sep='\t')
df3 = pd.DataFrame(test3)
print(df3)
💦2.3 读取txt文件
import pandas as pd
# 导入txt文件
test2 = pd.read_csv("./excel/test13.txt",sep='|')
df2 = pd.DataFrame(test2)
print(df2)
结果:

🔅(二)数据透视表
在excel中存在多种数据,且分为很多类型,这时使用数据透视表就会很方便也很直观的为我们分析出各种我们想要的数据了。
实例:将下列数据绘制成一个透视表,并绘制出按总类分每年的销售额!

💨1.在excel中制作透视表
需要按照年份来分,则我们需要将date列拆分,把年份拆分出来。随后在数据栏下选择数据透视表,选择区域即可。
随后将各部分数据拖动到各区域即可。


结果:
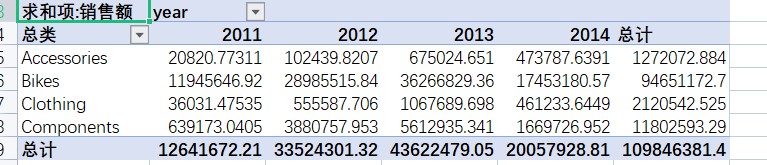
这样就在excel中完成了数据透视表的制作。
那么在pandas中要怎么实现这一效果呢?
💨2.在pandas中绘制透视表
绘制透视表的函数为:df.pivot_lable(index,columns,values),最后将数据求和即可。
import pandas as pd
import numpy as np
pd.options.display.max_columns =999
test = pd.read_excel('./excel/test14.xlsx')
df = pd.DataFrame(test)
# 将年份取出并新建一个列名为年份的列
df['year'] = pd.DatetimeIndex(df['Date']).year
# 绘制透视表
table = df.pivot_table(index='总类',columns='year',values='销售额',aggfunc=np.sum)
df1 = pd.DataFrame(table)
df1['总计'] = df1[[2011,2012,2013,2014]].sum(axis=1)
print(df1)
结果:

除此之外还可以利用groupby函数来绘制数据表。这里将总类和年份分组求销售总额和销售数量。
import pandas as pd
import numpy as np
pd.options.display.max_columns =999
test = pd.read_excel('./excel/test14.xlsx')
df = pd.DataFrame(test)
# 将年份取出并新建一个列名为年份的列
df['year'] = pd.DatetimeIndex(df['Date']).year
# groupby方法
group = df.groupby(['总类','year'])
s= group['销售额'].sum()
c = group['ID'].count()
table = pd.DataFrame({'sum':s,'total':c})
print(table)
结果:

🍻结语
今天的内容就到这里啦,希望看到此文的小伙伴能有所收获,觉得不错的话还望三连支持一波啊,关注我,咱们下期再见!!


- 点赞
- 收藏
- 关注作者
评论(0)