使用pytorch自己构建网络模型实战

写在前面
前段时间在Git上下载了yolov5的代码,经过调试,最后运行成功。但是发现对网络训练的步骤其实很不熟悉,于是乎最近看了看基于pytorch的深度学习——通过学习,对pytorch的框架有了较清晰的认识,也可以自己来构建一些模型来进行训练。如果你也发现自己只知道在Git上克隆别人的代码,但是自己对程序的结构不了解,那么下面的内容可能会帮到你!!!
这部分内容主要是根据B站视频总结而来,视频中给出了pytorch从安装到最后训练模型的完整教程,本篇文章主要总结神经网络的完整的模型训练套路,希望通过本篇文章可以让你对网络训练步骤有一个清晰的认识。
本次内容用到的数据集是CIFAR10,使用这个数据的原因是这个数据比较轻量,基本上所有的电脑都可以跑。CIFAR10数据集里是一些32X32大小的图片,这些图片都有一个自己所属的类别(如airplane、cat等),如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JhhptIJW-1642689614772)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220115193632769.png)]](https://img-blog.csdnimg.cn/0554fef09fd64b5da4a20ebc13a61811.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
注意:这个数据集不需另外要从网页下载,程序中可以调整代码参数进行下载
我们先来了解一下我们需要进行的工作及实现的功能:我们首先需要下载数据集,然后通过数据来训练模型,并在测试集上进行测试,这时候我们可以保存我们训练好的模型。最后通过我们训练的模型来判断一些图片的类别(从网络上下载一些图片,判断它是猫是狗或是其他的类型【当然这个数据集只有10种类型,如上图所示的10种】)
下面我们就来一步步的介绍!!!【代码我分流程分部分介绍,完整代码放在文末自取】
完整网络模型训练步骤
1、准备数据集
很显然,没有数据一切都是空谈,那么第一步就是准备我们需要的数据集CIFAR10。
#1、准备数据集
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(), download=Ture)
test_dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(), download=Ture)
第一个参数“./data”是指定下载数据集保存的位置,第二个参数train=True/Flase是指下载的数据是训练集数据还是测试集数据【True表示训练集,Flase表示测试集】,第三个参数是图片的一个转化,要将图片格式转化为tensor类型,第四个参数download为True表示你没有这个数据,这时候会自动下载数据,为Flase表示有这个数据,不会再进行下载【注意:这个参数设置成True且你有数据集,那同样不会进行数据下载,故这个参数一直设置成True就好了】。
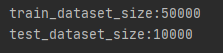
我们可以打印数据集的长度来看一下这个数据集的大小,可以发现训练集有5000张图片,测试集有1000张图片。
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print("train_dataset_size:{}".format(train_dataset_size))
print("test_dataset_size:{}".format(test_dataset_size))
2、加载数据集
#2、加载数据集
train_dataset_loader = DataLoader(dataset=train_dataset, batch_size=64)
test_dataset_loader = DataLoader(dataset=test_dataset, batch_size=64)
在得到数据集后,我们还要对数据集进行加载,加载数据集就类似于打包,比如这里的第二个参数设置的是batch_size=64,则表示把dataset中的64个数据打包一起放入dataloader中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XRslrX7g-1642689614781)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220116130740049.png)]](https://img-blog.csdnimg.cn/487e832c1ddc4c5f82b879c7832f04bb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
3、搭建神经网络✨✨✨
加载好数据后,就可以搭建神经网络了,我们可以百度CIFAR10 model,可以出现很多CIFAR10的网络模型,如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mqVuMzfY-1642689614784)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220115202041866.png)]](https://img-blog.csdnimg.cn/f4479b82510e48a2b8e2787b8782f7d3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
我们可以根据上图来搭建网络模型,如下:
#3、搭建神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, input):
input = self.model1(input)
return input
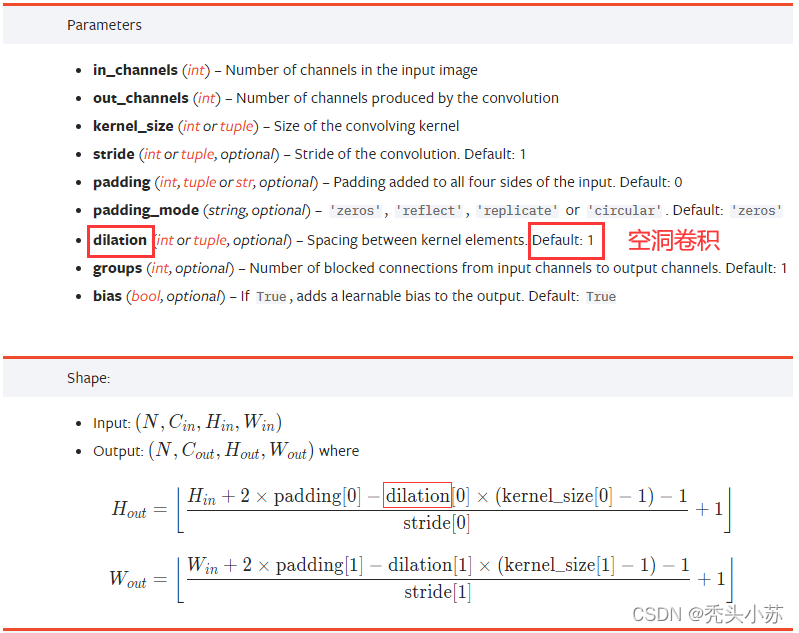
这部分代码完全是根据上图中的模型一步步写的,具有一一对应的关系,只是在卷积中的padding需要我们根据前后输入输出的尺寸进行计算,最后发现三步卷积padding都为2,这里给出pytorch官网的相关计算公式:
4、创建网络模型
这步只要一行代码,其实就是实列化了一个对象。
#4、创建网络模型
net = Net()
我们可以打印出来看一看我们自己创建的网络模型,如下图。可以看出和前文的结构是一致的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UAI2Oc40-1642689614786)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220115203748647.png)]](https://img-blog.csdnimg.cn/6b3bb169f9514d11b4da85bbeddfd724.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
到这里我们已经创建好了自己的模型,这个模型输入是3x32x32的图片【可以认为就是一个3x32x32的张量】,输出是1x10的向量。每当我们创建好一个模型后,应该检测一下模型的输入输出是否是我们所期待的,若不是则即使调整模型。我们可以用以下代码来检测输出是否符合要求。
net = Net()
input = torch.ones((64, 3, 32, 32)) #64为batch_size,3x32x32表示张量尺寸
output = net(input)
print(output.shape)

可以看出输出是符合要求的,64是输入的batch_size,相当于输入64张图片。
5、设置损失函数、优化器
设置损失函数、优化器这些都是神经网络的一些基础知识,不知道的自行补充。当然这里的损失函数和优化器可以和我不同,感兴趣的也可以改变这些来看看我们最后训练的效果会不会发生变化【我测试了几个,对于本例效果差别不大】
#5、设置损失函数、优化器
#损失函数
loss_fun = nn.CrossEntropyLoss() #交叉熵
loss_fun = loss_fun.to(device)
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(net.parameters(), learning_rate) #SGD:梯度下降算法
6、设置网络训练中的一些参数
这部分主要是用来记录一些训练测试的次数及网络训练轮数。
#6、设置网络训练中的一些参数
total_train_step = 0 #记录总计训练次数
total_test_step = 0 #记录总计测试次数
epoch = 10 #设计训练轮数
7、开始训练网络✨✨✨
进行网络训练时,我们首先会通过自己构建的网络得到输出,然后比较输出和真实值,计算出损失,最后通过反向传播,调整网络中参数的值。对于反向传播不理解的可以参考我的这篇文章:BP神经网络
#7、开始进行训练
for i in range(epoch):
print("---第{}轮训练开始---".format(i+1))
net.train() #开始训练,不是必须的,在网络中有BN,dropout时需要
for data in train_dataset_loader:
imgs, targets = data
targets = targets.to(device)
outputs = net(imgs)
#比较输出与真实值,计算Loss
loss = loss_fun(outputs, targets)
#反向传播,调整参数
optimizer.zero_grad() #每次让梯度重置
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("---第{}次训练结束, Loss:{})".format(total_train_step, loss.item()))
8、开始测试网络✨✨✨
对网络进行测试过程和训练是类似的,不同的是测试过程不需要通过反向传播来更新参数。
#8、开始进行测试,测试不需要进行反向传播
net.eval() #开始测试,不是必须的,在网络中有BN,dropout时需要
with torch.no_grad(): #这句表示测试不需要进行反向传播,即不需要梯度变化【可以不加】
total_test_loss = 0 #测试损失
total_test_accuracy = 0 #测试集准确率
for data in test_dataset_loader:
imgs, targets = data
outputs = net(imgs)
#计算测试损失
loss = loss_fun(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_test_accuracy = total_test_accuracy + accuracy
print("第{}轮测试的总损失为:{}".format(i+1, total_test_loss))
print("第{}轮测试的准确率为:{}".format(i+1, total_test_accuracy/test_dataset_size))
9、保存模型
将每一个epoch的模型都保存下来,为后面物体识别准备模型。
#9、保存模型
torch.save(net, "./self_model_{}".pth.format(i+1))
print("模型已保存")
检测训练模型的效果
介绍到这里,完整的自建网络模型训练步骤我们就讲完了,接下来来看看我们用之前保存的模型来检测一些我们从网络上下载的图片,代码如下:
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "./imgs/airplane.png" #网络下载的图片放置地址
image = Image.open(image_path)
image = image.convert('RGB') #将图片转化为RGB三通道图片,有的图片有4个通道(多了个透明度)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
model = torch.load("net_29.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output.argmax(1))
网络下载图片如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ISZI17Z3-1642689614787)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220115212701582.png)]](https://img-blog.csdnimg.cn/07b09b94fed44cd0948061e68421339c.png#pic_center)
输出结果如下:
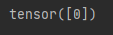
0表示的就是airplane【可以从官网中10种类型顺序得出,从上到下是0-9】。
我们可以在来测试一张狗的图片,从官网可知,输出5为狗,原始图片和输出图片如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pBNuh9wh-1642689614789)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220115213545415.png)]](https://img-blog.csdnimg.cn/528bb8f513474eb5bad9c8de93d2bd43.png#pic_center)
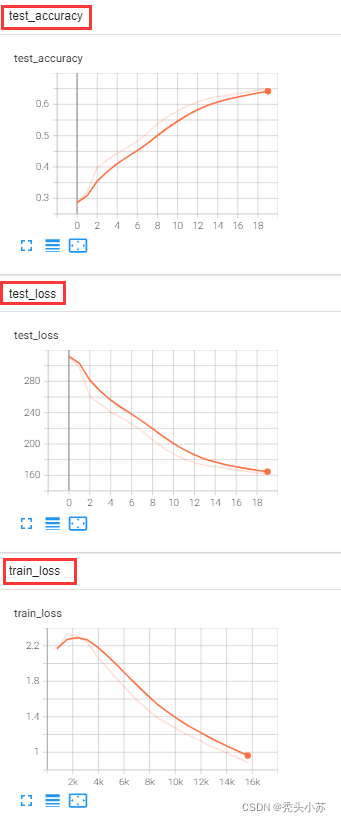
这里我们可以来看一下模型的检测损失和正确率(设置的epoch=20),准确率大概在65%左右。【这里是在Google Colab上用GPU训练的,单用CPU训练速度还是很慢】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BufuPb3A-1642689614791)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220115234213182.png)]](https://img-blog.csdnimg.cn/445d7747de31478781ca2efddbcd911f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_14,color_FFFFFF,t_70,g_se,x_16#pic_center)
模型的准确率似乎就停留在65%上下,我尝试增大epoch到30,但是准确率基本一致。同时我也用3x3的小卷积核代替5x5的卷积核、用卷积代替池化,用卷积代替全连接层等方式进行训练,但是效果都不显著,当然这里我只训练了30个epoch,增大epoch效果可能会好,但耗时会比较多,这部分主要是学习训练模型的思路,感兴趣可以尝试各种方式看能否改进模型效果。
下图是用Tensorboard画的损失和准确率的曲线图,上文的代码中只关注模型的训练步骤,没有设计tensorboard的讲解,在文末源代码中会包含这部分内容。
咻咻咻咻~~duang~~点个赞呗

- 点赞
- 收藏
- 关注作者
评论(0)