VGGnet论文解读及代码实现

# Title文章标题
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
# Summary
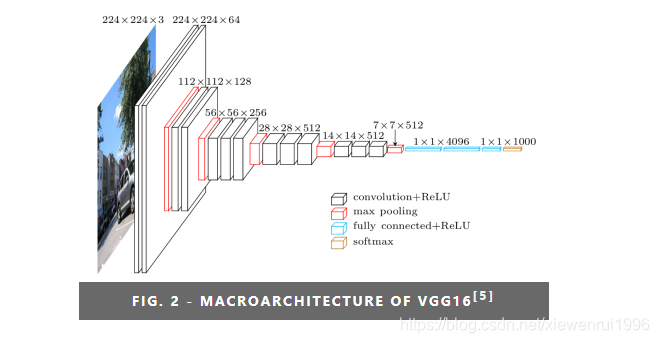
网络架构如下图:

卷积神经网络的输入是一个固定大小的224×224 RGB图像。做的唯一预处理是从每个像素中减去在训练集上计算的RGB平均值。图像通过一堆卷积(conv.)层传递,我们使用带有非常小的接受域的过滤器:3×3(这是捕捉左/右、上/下、中间概念的最小大小)。在其中一种配置中,我们还使用了1×1的卷积滤波器,它可以看作是输入通道的线性变换(其次是非线性)。卷积步幅固定为1像素;凹凸层输入的空间填充是卷积后保持空间分辨率,即3×3凹凸层的填充为1像素。空间池化由五个最大池化层执行,它们遵循一些对流层(不是所有对流层都遵循最大池化)。最大池是在一个2×2像素的窗口上执行的,步长为2。
如上图所示,vggnet不单单的使用卷积层,而是组合成了“卷积组”,即一个卷积组包括2-4个3x3卷积层(a stack of 3x3 conv),有的层也有1x1卷积层,因此网络更深,网络使用2x2的max pooling,在full-image测试时候把最后的全连接层(fully-connected)改为全卷积层(fully-convolutional net),重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,另外VGGNet卷积层有一个显著的特点:特征图的空间分辨率单调递减,特征图的通道数单调递增,这是为了更好地将HxWx3(1)的图像转换为1x1xC的输出,之后的GoogLeNet与Resnet都是如此。另外上图后面4个VGG训练时参数都是通过pre-trained 网络A进行初始赋值。
VGGNet由5个卷积层和3个全连接层构成。卷积层一般是3x3的卷积,结果表明比1x1卷积效果要好。
VGGNet三个全连接层为:
- FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
- FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
- FC1000(最后接SoftMax1000分类),FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
训练细节
batch_size=256,momentum=0.9,权值衰减使用L2正则化,L2=0.0005。第一、二层的全连接层droupout=0.5.lr初始化为0.01,后面改为0.001。我们从均值为0和方差为的正态分布中采样权重。偏置初始化为零。
为了获得固定大小的224×224 ConvNet输入图像,它们从归一化的训练图像中被随机裁剪(每个图像每次SGD迭代进行一次裁剪)。为了进一步增强训练集,裁剪图像经过了随机水平翻转和随机RGB颜色偏移。S=256或384,对图片进行尺度抖动比增强数据集有助于捕获多尺度图像统计信息,提高检测正确率。
测试
最后三个全连接层首先被转换成卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层)。然后将所得到的全卷积网络应用于整个(未裁剪)图像上。结果是类得分图的通道数等于类别的数量,以及取决于输入图像大小的可变空间分辨率。最后,为了获得图像的类别分数的固定大小的向量,类得分图在空间上平均(和池化)。我们还通过水平翻转图像来增强测试集;将原始图像和翻转图像的soft-max类后验进行平均,以获得图像的最终分数。
结果
把模型D和模型E融合在图像的检测上表现更好,更能提高检测的正确率。
实现代码
vgg19_keras(vgg19架构)
import keras
import numpy as np
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, AveragePooling2D
from keras.initializers import he_normal
from keras import optimizers
from keras.callbacks import LearningRateScheduler, TensorBoard
from keras.layers.normalization import BatchNormalization
from keras.utils.data_utils import get_file
num_classes = 10
batch_size = 128
epochs = 200
iterations = 391
dropout = 0.5
weight_decay = 0.0001
log_filepath = r'./vgg19_retrain_logs/'
from keras import backend as K
if('tensorflow' == K.backend()):
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
def scheduler(epoch):
if epoch < 80:
return 0.1
if epoch < 160:
return 0.01
return 0.001
WEIGHTS_PATH = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels.h5'
filepath = get_file('vgg19_weights_tf_dim_ordering_tf_kernels.h5', WEIGHTS_PATH, cache_subdir='models')
# data loading
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# data preprocessing
x_train[:,:,:,0] = (x_train[:,:,:,0]-123.680)
x_train[:,:,:,1] = (x_train[:,:,:,1]-116.779)
x_train[:,:,:,2] = (x_train[:,:,:,2]-103.939)
x_test[:,:,:,0] = (x_test[:,:,:,0]-123.680)
x_test[:,:,:,1] = (x_test[:,:,:,1]-116.779)
x_test[:,:,:,2] = (x_test[:,:,:,2]-103.939)
# build model
model = Sequential()
# Block 1
model.add(Conv2D(64, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block1_conv1', input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block1_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool'))
# Block 2
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block2_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block2_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool'))
# Block 3
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block3_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block3_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block3_conv3'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block3_conv4'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool'))
# Block 4
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block4_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block4_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block4_conv3'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block4_conv4'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool'))
# Block 5
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block5_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block5_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block5_conv3'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='block5_conv4'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool'))
# model modification for cifar-10
model.add(Flatten(name='flatten'))
model.add(Dense(4096, use_bias = True, kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='fc_cifa10'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(4096, kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='fc2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(10, kernel_regularizer=keras.regularizers.l2(weight_decay), kernel_initializer=he_normal(), name='predictions_cifa10'))
model.add(BatchNormalization())
model.add(Activation('softmax'))
# load pretrained weight from VGG19 by name
model.load_weights(filepath, by_name=True)
# -------- optimizer setting -------- #
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.125,height_shift_range=0.125,fill_mode='constant',cval=0.)
datagen.fit(x_train) #将数据生成器用于某些示例数据。它基于一组样本数据,计算与数据转换相关的内部数据统计。
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size), #生成增强后的数据
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
model.save('retrain.h5')vgg19预测
import keras
from keras.applications.vgg19 import VGG19
from keras.applications.vgg19 import preprocess_input, decode_predictions
from PIL import Image
import numpy as np
import os.path
# Using ImageNet pre_trained weights to predict image's class(1000 class)
# ImageNet -- http://www.image-net.org/
# make sure your package pillow is the latest version
model = VGG19(weights='imagenet') # load keras ImageNet pre_trained model
while True:
img_path = input('Please input picture file to predict ( input Q to exit ): ')
if img_path == 'Q':
break
if not os.path.exists(img_path):
print("file not exist!")
continue
try:
img = Image.open(img_path)
ori_w,ori_h = img.size
new_w = 224.0;
new_h = 224.0;
if ori_w > ori_h:
bs = 224.0 / ori_h;
new_w = ori_w * bs
weight = int(new_w)
height = int(new_h)
img = img.resize( (weight, height), Image.BILINEAR )
region = ( weight / 2 - 112, 0, weight / 2 + 112, height)
img = img.crop( region )
else:
bs = 224.0 / ori_w;
new_h = ori_h * bs
weight = int(new_w)
height = int(new_h)
img = img.resize( (weight, height), Image.BILINEAR )
region = ( 0, height / 2 - 112 , weight, height / 2 + 112 )
img = img.crop( region )
x = np.asarray( img, dtype = 'float32' )
x[:, :, 0] = x[:, :, 0] - 123.680
x[:, :, 1] = x[:, :, 1] - 116.779
x[:, :, 2] = x[:, :, 2] - 103.939
x = np.expand_dims(x, axis=0)
results = model.predict(x)
print('Predicted:', decode_predictions(results, top=5)[0])
except Exception as e:
pass
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/103877679

- 点赞
- 收藏
- 关注作者
评论(0)