Google Earth Engine(GEE)——TFRecord 和地球引擎

TFRecord 是一种二进制格式,用于高效编码tf.Example protos 的长序列 。TFRecord 文件很容易被 TensorFlow 通过这里和 这里tf.data描述的包 加载 。本页介绍了 Earth Engine 如何在 或和 TFRecord 格式之间进行转换。 ee.FeatureCollectionee.Image
将数据导出到 TFRecord
您可以将表格 ( ee.FeatureCollection) 或图像 ( ee.Image) 导出到 Google Drive 或 Cloud Storage 中的 TFRecord 文件。导出的配置取决于您要导出的内容,如下所述。从 Earth Engine 导出到 TFRecord 的所有数字都被强制转换为浮点类型。
导出表
导出ee.FeatureCollection到TFRecord文件时,ee.Feature 表中的每条tf.train.Example 与TFRecord文件中的每条 (即每条记录)有1:1的对应关系 。的每个属性都ee.Feature被编码为 tf.train.Feature 带有对应于数字或ee.Array存储在属性中的浮点数列表。如果在属性中导出带有数组的表,则需要在读取时告诉 TensorFlow 数组的形状。导出到 TFRecord 文件的表将始终使用 GZIP 压缩类型进行压缩。对于每次导出,您总是会得到一个 TFRecord 文件。
以下示例演示了从标量属性('B2'、...、'B7'、'landcover')的导出表中解析数据。请注意,浮点列表的维度是 [1],类型是tf.float32:
-
dataset = tf.data.TFRecordDataset(exportedFilePath)
-
-
featuresDict = {
-
'B2': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32),
-
'B3': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32),
-
'B4': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32),
-
'B5': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32),
-
'B6': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32),
-
'B7': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32),
-
'landcover': tf.io.FixedLenFeature(shape=[1], dtype=tf.float32)
-
}
-
-
parsedDataset = dataset.map(lambda example: tf.io.parse_single_example(example, featuresDict))
请注意,此示例说明了读取标量特征(即shape=[1])。如果您要导出 2D 或 3D 阵列(例如图像补丁),那么您将在解析时指定补丁的形状,例如shape=[16, 16]16x16 像素补丁。
导出图像
导出图像时,数据按通道、高度、宽度 (CHW) 排序。导出可以拆分为多个 TFRecord 文件,每个文件包含一个或多个大小patchSize为 的补丁,这是用户在导出中指定的。以字节为单位的文件大小由用户在maxFileSize参数中指定。每个补丁和tf.train.Example 生成的 TFRecord 文件中的每个补丁之间有 1:1 的对应关系 。图像的每个波段都作为一个单独的存储 tf.train.Feature 在 each 中tf.train.Example,其中存储在每个特征中的浮点列表的长度是补丁宽度 * 高度。如本例所示,扁平化列表可以拆分为多个单独的像素 . 或者可以像本例一样恢复导出补丁的形状。
为了帮助减少边缘效应,导出的补丁可以重叠。具体来说,您可以指定kernelSize将导致大小的图块:
[patchSize[0] + kernelSize[0], patchSize[1] + kernelSize[1]]
每个瓦片与相邻瓦片重叠[kernelSize[0]/2, kernelSize[1]/2]。结果,以大小块kernelSize的边缘像素为中心的大小内核patchSize包含完全有效的数据。空间中补丁的空间排列如图 1 所示,其中 Padding Dimension 对应于内核与相邻图像重叠的部分:
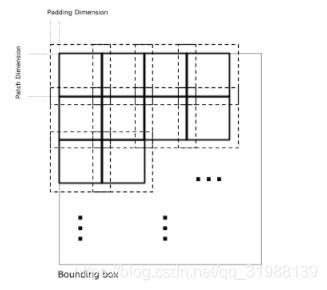
如何导出图像补丁。填充维度是 kernelSize/2。
formatOptions
的patchSize,maxFileSize和kernelSize参数传递给ee.Export(JavaScript的),或者ee.batch.Export 通过(Python)的调用formatOptions字典,其中键是传递给其他参数的名称Export。formatOptions 导出为 TFRecord 格式的图像可能有:
| assets | 描述 | 类型 |
|---|---|---|
patchDimensions |
在导出区域上平铺的尺寸,只覆盖边界框中的每个像素一次(除非补丁尺寸没有均匀划分边界框,在这种情况下,沿最大 x/y 边缘的边界平铺将被丢弃)。尺寸必须 > 0。 | 数组<int>[2]。 |
kernelSize |
如果指定,图块将被正负边距尺寸缓冲,导致相邻块之间重叠。如果指定,则必须提供两个维度(分别为 X 和 Y)。 | 数组<int>[2]。默认值:[1, 1] |
compressed |
如果为 true,则使用 gzip 压缩 .tfrecord 文件并附加“.gz”后缀 | 布尔值。默认值:真 |
maxFileSize |
导出的 .tfrecord(压缩前)的最大大小(以字节为单位)。较小的文件大小将导致更大的分片(从而产生更多的输出文件)。 | 国际。默认值:1 GiB |
defaultValue |
在部分或完全屏蔽的像素的每个波段中设置的值,以及在由阵列波段制成的输出 3D 特征中的每个值设置的值,其中源像素的阵列长度小于特征值的深度(即,对应特征深度为 3 的阵列带中长度为 2 的阵列像素的索引 3 处的值)。整数类型带的小数部分被删除,并被限制在带类型的范围内。默认为 0。 | 国际。默认值:0 |
tensorDepths |
从输入数组带的名称映射到它们创建的 3D 张量的深度。数组将被截断,或用默认值填充以适应指定的形状。对于每个阵列波段,这必须有一个相应的条目。 | 数组<int>[]。默认: [] |
sequenceData |
如果为 true,则每个像素都作为 SequenceExample 输出,将标量带映射到上下文并将数组带映射到示例的序列。SequenceExamples 以每个补丁中像素的行优先顺序输出,然后按文件序列中区域补丁的行优先顺序输出。 | 布尔值。默认值:假 |
collapseBands |
如果为 true,则所有波段将组合成一个 3D 张量,采用图像中第一个波段的名称。所有波段都被提升为字节,int64s,然后根据所有波段中该序列中最远的类型按该顺序浮动。只要指定了 tensor_depths 就允许使用数组波段。 | 布尔值。默认值:假 |
maskedThreshold |
补丁中被屏蔽像素的最大允许比例。超过此限额的补丁将被删除而不是写入文件。如果此字段设置为 1 以外的任何值,则不会生成 JSON sidecar。默认为 1。 | 漂浮。默认值:1 |
TFRecord“混音器”文件
当您导出到 TFRecord 时,Earth Engine 将使用您的 TFRecord 文件生成一个名为“混音器”的边车。这是一个简单的 JSON 文件,用于定义补丁的空间排列(即地理配准)。如下一节所述,上传对图像所做的预测需要此文件。
导出时间序列
支持将图像导出到示例和序列示例。当您导出到示例时,导出区域被切割成补丁,这些补丁按行优先顺序导出到一定数量的 .tfrecord 文件中,每个频段都有自己的特征(除非您指定collapseBands)。当您导出到 SequenceExamples 时,每个像素的 SequenceExample 将被导出,这些 SequenceExample 在补丁中按行优先顺序,然后按原始导出区域中补丁的行优先顺序(如果您不确定,请始终假设在某些情况下事情将按行优先顺序排列)。注意:图像的任何标量带将被打包到 SequenceExample 的上下文中,而数组带将成为实际的序列数据。
阵列波段
当图像导出为 TFRecord 格式时,阵列波段是可导出的。数组带区的导出提供了一种填充 SequenceExamples 的“FeatureLists”的方法,以及一种在导出到常规示例时创建 3D 张量的方法。有关如何管理阵列带的长度/深度的信息,请参阅collapseBands和/或 tensorDepths在上表中。注意:使用collapseBands 和导出到 SequenceExamples(因此设置参数sequenceData)将导致所有波段折叠为每个像素的单个时间序列。
将 TFRecords 上传到 Earth Engine
您可以将表格(仅限命令行)和图像作为 TFRecord 文件上传到 Earth Engine。对于表格,前面描述的 1:1 关系 适用于相反的方向(即tf.train.Example-> ee.Feature)。
上传图像
如果您对导出的影像生成预测,请在上传预测(作为 TFRecord 文件)以获取地理配准影像时提供混合器。请注意,补丁的重叠部分(图 1 中的填充维度)将被丢弃以导致导出区域的连续覆盖。预测应tf.train.Example按照与您最初导出的图像示例(甚至在任意数量的文件之间)具有相同数量和顺序的序列进行排列 。
文章来源: blog.csdn.net,作者:此星光明2021年博客之星云计算Top3,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31988139/article/details/119838527

- 点赞
- 收藏
- 关注作者
评论(0)