C++学习系列笔记(八)

1、STL映射类
STL map和multimap的内部结构看起来像棵二叉树。这意味着在map或multimap中插入元素时将进行排序。要使用STL map或multimap类,需要包含头文件<map>:#include<map>
实例化map
-
#include<map>
-
using namespace std;
-
……
-
map <keyType, valueType, Predicate=std::less<keyType>> mapObject;
-
multimap <keyType, valueType, Predicate=std::less<keyType>> mmapObject;
第三个模板参数是可选的。因此,将整数映射到字符串的map或multimap类似于下面这样:
-
std::map<int,string>mapIntToString;
-
std::multimap<int,string> mmapIntToString;
在map或multimap插入元素
要在这两种容器中插入元素,都可使用成员函数insert:mapIntToString.insert(make_pair(-1,"Minus One"));
也可直接使用std::pair来指定要插入的键和值:mapIntToString.insert(pait<int,string>(1000,"One Thousand"));
在map或multimap查找元素
find()总是返回一个迭代器,核实find()操作成功总是明智的,为此可将返回的迭代器与end()进行比较:multimap<int,string>::const_iterator iPairFound=mapIntToString.find(key);
如果您使用的编译器遵循C++11标准,可使用关键字auto来简化迭代器声明:auto iPairFound = mapIntToString.find(key);
multimap容器可能包含多个键相同的键-值对,因此需要找到与指定键对应的所有值。为此,可使用multimap::count()确定有多少个值与指定的键对应,再对迭代器递增,以访问这些相邻的值:
删除元素
map和multimap提供了成员函数erase(),该函数删除容器中的元素。调用erase函数时将键作为参数,这将删除包含指定键的所有键-值对:
mapObject.erase(key);
erase函数的另一种版本接受迭代器作为参数,并删除迭代器指向的元素:
mapObject.erase(iElement);
还可使用迭代器指定边界,从而将指定范围内的所有元素都从map或multimap中删除:
mapObject.erase(iLowerBound,iUpperBound);
提供自定义的排序谓词
要提供不同的排序标准,可编写一个二元谓词——实现了operator()的类或结构:
-
template<typename KeyType>
-
struct Predicate
-
{
-
bool operator() (const KeyType& key1,const KeyType& key2)
-
{
-
//your sort priority logic here;
-
}
-
};
基于散列表的STL键-值对容器std::unordered_map
要使用这个模板类,需要包含头文件#include<unordered_map>
unordered_map的平均插入和删除时间是固定的,查找元素的时间也是固定的。
Index = HashFunction(Key,TableSize);
使用find()根据键查找元素时,将使用HashFunction()计算元素的位置,并返回该位置的值,就像数组返回其存储的元素那样。
从使用的角度看,这两种容器与std::map和std::multimap差别不大,可以类似的方式执行实例化、插入和查找。然而,一个重要的特点是,unordered_map包含一个散列函数,用于计算排列顺序:
unorder_map<int,string>::hasher HFn=UmapIntToString.hash_function();
要获悉键对应的索引,可调用该散列函数,并将键传递给它:
size_t HashingValue1000=HFn(1000);
典型代码:
输出:
2、理解函数对象
一元函数:接受一个参数的函数,如f(x)。如果一元函数返回一个布尔值,则该函数称为谓词。
二元函数:接受两个参数的函数,如 f(x, y)。如果二元函数返回一个布尔值,则该函数称为二元谓词。
2、lambda表达式
可将lambda表达式视为包含公有operator()的匿名结构(或类)。
定义·lambda表达式
lambda表达式的定义必须以方括号([])打头。这些括号告诉编译器,接下来是一个lambda表达式。方括号的后面是一个参数列表,该参数列表与不使用lambda表达式时提供给operator()的参数列表相同。
2.1、一元函数对应的lambda表达式
[ ](Type paraName){ //lambda expression here; }
务必使用const来限定输入参数,在输入参数为引用时尤其如此。
通过捕获列表接受状态变量的lambda表达式
用户能够指定数字
-
int Divisor = 2;
-
auto iElement = find_if (begin of range, end of range, [Divisor] (int dividen) {return (dividen % Divisor) == 0;});
除数是一个状态变量,因此状态变量类似于C++11之前的函数对象类中的成员。您可以将状态传递给lambda表达式,并根据状态的性质相应地使用它。
lambda表达式的通用语法
lambda 表达式总是以方括号打头,并可接受多个状态变量,为此可在捕获列表([…])中指定这些状态变量,并用逗号分隔:
[ StateVar1, StateVar2] (Type& param) {//code here;}
如果要在lambda表达式中修改这些状态变量,可添加关键字multable:
[ StateVar1, StateVar2] (Type& param) mutable {//code here;}
这样,便可在lambda表达式中修改捕获列表([])中指定的变量,但离开lambda表达式后,这些修改将无效。要确保在lambda表达式内部对状态变量的修改在其外部也有效,应按引用传递它们:
[ &StateVar1, &StateVar2] (Type& param) {//code here;}
lambda表达式还可接受多个输入参数,为此可用逗号分隔它们:
[StateVar1, StateVar2 ] (Type1& var1, Type2& var2){//code here;}
2.2、二元函数对应的lambda表达式
二元函数接受两个参数,还可返回一个值。与之等价的lambda表达式如下:
[……](Type1& param1Name, Type2& param2Name) { //code here; }
2.3、二元谓词对应的lambda表达式
返回true或false,可帮助决策的二元函数被称为二元谓词。这种谓词可用于std::sort()等排序算法中,这些算法对容器中的两个值调用二元谓词,以确定将哪个放在前面。与二元谓词等价的lambda表达式的通用语法如下:
[……] (Type1& param1Name, Type2& param2Name) {//return bool expression;}
第七章 STL算法
STL算法分两大类:非变序算法与变序算法。
不改变容器中元素的顺序和内容的算法称为非变序算法。
变序算法改变其操作的序列的元素顺序或内容。
第八章 自适应容器
标准模板库(STL)提供了一些这样的容器,即使用其他容器模拟栈和队列的行为。这种内部使用一种容器但呈现另一种容器的行为特征的容器称为自适应容器。主要有三种类型:stack,queue,priority_queue。
STL stack是一个模板类,要使用它,必须包含头文件<stack>。它是一个泛型类,允许在顶部插入和删除元素,而不允许访问中间的元素。从这种角度看,std::stack的行为很像一叠盘子。
实例化stack
-
#include<stack>
-
#include<vector>
-
int main()
-
{
-
using namespace std;
-
stack<int> stackInts;
-
stack<double> stackkDoubles;
-
stack<double, vector<double>stackDoublesInVector;
-
stack<int>stackIntsCopy(stackInts);
-
return 0;
-
}
使用STL位标志
位是存储设置与标志的高效方法。标准模板库(STL)提供了可帮助组织与操作位信息的类。
bitset类
要使用bitset,必须包含头文件#include<bitset>
实例化这个模板:
bitset<4> fourBits;
实例化一个字符串
bitset<5> FiveBits("10101");
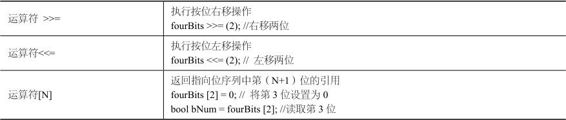
bitset的成员方法

STL bitset的缺点之一是不能动态地调整长度。仅当在编辑阶段知道序列将存储多少位时才能使用bitset。
vector<bool> 可动态的添加标志
vector<bool>是对std::vector的部分具体化,用于存储布尔数据。这个类可动态地调整长度,因此程序员无需在编译阶段知道要存储的布尔标志数。
实例化:
vector<bool> vecBool(10, true);
即它最初包含10个布尔元素,且每个元素都被初始化为 1 (即true)
第九章 理解智能指针
智能指针类重载了解除引用运算符(*')和成员选择运算符(->),让程序员可以像使用常规指针那样使用它们.
智能指针的分类实际上就是内存资源管理策略的分类,可分为如下几类:
9.1、深复制
-
template<typename T>
-
class deepcopy_smart_pointer
-
{
-
private:
-
T* m_pObject;
-
#复制构造函数
-
deepcopy_smart_pointer (const deepcopy_smart_pointer& source)
-
{
-
//Clone是一个虚函数
-
m_pObject=source->Clone();
-
}
-
}
9.2、写时复制机制
写时复制机制(Copy on Write,COW)试图对深复制智能指针的性能进行优化,它共享指针,直到首次写入对象。首次调用非const函数时,COW指针通常为该非const函数操作的对象创建一个副本,而其他指针实例仍共享源对象。
实现const和非const版本的运算符*'和->,是实现COW指针功能的关键。非const版本用于创建副本。
9.3、引用计数智能指针
引用计数是一种记录对象的用户数量的机制。当计数降低到零后,便将对象释放。因此,引用计数提供了一种优良的机制,使得可共享对象而无法对其进行复制。
9.4、破坏性复制
std::auto_ptr是最流行(也可以说是最臭名昭著,取决于您如何看)的破坏性复制指针。被传递给函数或复制给另一个指针后,这种智能指针就没有用了。即源指针也被销毁了。C++11 摒弃了std::auto_ptr,您应使用std::unque_ptr,这种指针不能按值传递,而只能按引用传递,因为其复制构造函数和复制赋值运算符都是私有的。要使用std:unique_ptr,必须包含头文件<memory>。
-
#include<iostream>
-
#include<algorithm>
-
#include<vector>
-
#include<memory>
-
using namespace std;
-
class Fish
-
{
-
public:
-
Fish() { cout << "Fish:constructed!" << endl; }
-
~Fish() { cout << "Fish:Destructed!" << endl; }
-
void swim()const
-
{
-
cout << "Fish swim in the water" << endl;
-
}
-
};
-
void MakeFishSwim(const unique_ptr<Fish>& inFish)
-
{
-
inFish->swim();
-
}
-
int main()
-
{
-
unique_ptr<Fish> smartFish(new Fish);
-
smartFish->swim();
-
MakeFishSwim(smartFish);
-
unique_ptr<Fish> copySmartFish;
-
//copySmartFish = smartFish; //unique_ptr复制赋值运算符是私有的
-
return 0;
-
}
第九章 处理文件
C++使用std:fstream处理文件。要使用std::fstream类或其基类,需要包含头文件<fstream>
使用open()和close()打开和关闭文件
-
fstream myFile;
-
myFile.open("HelloFile.txt",ios_base::in|ios_base::out|ios_base::trunc);
-
if(myFile.is_open())
-
{
-
//do reading or writing;
-
myFile.close();
-
}
open()接受两个参数:第一个是要打开的文件的路径和名称(如果没有提供路径,将假定为应用程序的当前目录设置),第二个是文件的打开模式。在上述代码中,指定了模式 ios_base::trunc(即便指定的文件存在,也重新创建它)、ios_base::in(可读取文件)和ios_base::out(可写入文件)。
如果只想打开文件进行读取,可使用下述代码:
fstream myFile("HelloFile.txt",ios_base::in);
可在下述各种模式下打开文件流。
• ios_base::app:附加到现有文件末尾,而不是覆盖它。
• ios_base::ate:切换到文件末尾,但可在文件的任何地方写入数据。
• ios_base::trunc:导致现有文件被覆盖,这是默认设置。
• ios_base::binary:创建二进制文件(默认为文本文件)。
• ios_base::in:以只读方式打开文件。
• ios_base::out:以只写方式打开文件。
也可以使用open()创建文件夹并使用运算符<<写入文本
-
#include<iostream>
-
#include<algorithm>
-
#include<string>
-
#include<fstream>
-
using namespace std;
-
int main()
-
{
-
ofstream myFile;
-
myFile.open("HelloFile.txt", ios_base::out);
-
if(myFile.is_open())
-
{
-
cout << "File open sucessful" << endl;
-
myFile << "my first test file!" << endl;
-
myFile << "Hello,File!";
-
cout << "File will close now" << endl;
-
myFile.close();
-
}
-
return 0;
-
}
输出:
-
File open sucessful
-
File will close now
在目录下创建了一个TXT文档,内容为:my first test file!
Hello,File!
使用stringstream进行字符串转化
C++中的stringstream类是最有用的工具之一,让您能够执行众多的转换操作。要包含头文件#include<sstream>
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/100584807

- 点赞
- 收藏
- 关注作者
评论(0)