yolo原理系列——yolov1--yolov5详细解释

yolo系列原理
先唠唠
这部分主要讲述yolo系列各个版本的的原理,这部分会把yolov1到yolov5的原理进行详细的阐述。首先我们先来看深度学习的两种经典的检测方法:
-
Two-stage(两阶段):代表-- Fsater-rcnn Mask-rcnn系列
-
One-stage(单阶段):代表-- Yolo系列
两阶段和单阶段有什么样的区别呢,我们从整体上理解:单节段的就是一步到位,我们输入一个图像,经过一系列传化,最终会得到一个输出结果;双阶段相较于单节段多了一些中间步骤,输入一个原始图像,我们会先得到一些中间值,最后才输出结果,更形象的表述为,我们要选择一个人当代表,代表安徽省踢球,那么双阶段就类似与我先在安徽各个市找一些好苗子,最后再从这些好苗子中选择一个最优秀的。具体可以参照下图:

既然两种检测方式有所区别,那自然会讨论他们的优缺点:
-
One-stage
- 优势:速度非常快,适合做实时检测任务
- 劣势:效果通常不会太好
-
Two-stage
- 优势:效果通常比较好
- 劣势:速度较慢,不适合做实时检测任务
其实他们的优缺点我们也很好理解,单阶段检测的没有中间过程,那速度肯定是相当哇塞了,但从效果来说,就相对差一点。我们可以看一下他们的对比(以单阶段的yolo和双阶段的Faster-rcnn为代表)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MeXFwySh-1642432549733)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107163513421.png)]](https://img-blog.csdnimg.cn/392252b87d5c47e8868d721635753a0c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
从上图可以看出,YOLO的mAP要低于Fast-rcnn,但是FPS却远高于Fast-rcnn。【FPS表示一个网络的检测速度,越大速度越快,mAP表示模型综合检测的效果,越大效果越好】
🎈🎈🎈🎈🎈🎈🎈🎈
上面提到了一个术语:mAP。它表示的是一个综合检测的效果,因为表示模型效果的参数有很多,像IOU、precision、recall(好吧,这三是不是也不知道🤐🤐🤐)下面先来介绍这三个参数:
-
IOU
IOU其实很好理解,其表示(真实值和预测值的交集)占(真实值和预测值的并集)的比列,这也即是IOU的计算公式,如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z5OPnUTi-1642432549734)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107165215737.png)]](https://res-hd.hc-cdn.cn/ecology/9.3.209/v2_resources/ydcomm/libs/images/loading.gif)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z5OPnUTi-1642432549734)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107165215737.png)]](https://img-blog.csdnimg.cn/96dd9d9c583f42f293bfee023cb243c9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_14,color_FFFFFF,t_70,g_se,x_16#pic_center)
哎!!!?不是很好理解嘛…通俗点讲,IOU就表示真实值和预测值重叠的部分多不多,重叠多IOU就大,检测效果就好!!!可以再参照下图进行理解:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MnCygC4a-1642432549736)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107165753941.png)]](https://img-blog.csdnimg.cn/323ccdcf88844b8eac74a9953a756e25.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_18,color_FFFFFF,t_70,g_se,x_16#pic_centerr)
- precision(精度) && recall(召回率)
我们先来看他们的公式(好吧,我承认开始肯定看不懂😜😜😜)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JNd5vMeN-1642432549739)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107171113924.png)]](https://img-blog.csdnimg.cn/c73e3db368724092875b1b4c8ab3154e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_15,color_FFFFFF,t_70,g_se,x_16#pic_center)
我们通过一个例子来解释上诉公式中TP、FP、FN的含义,进而解释precision和recall。
已知:班级共100人,其中男生80人,女生20人
目标:找出所有女生
结果:从班级中选择了50人才找出20个女生,也即错误的把30名男生也挑选出来了
我们先来看看TP、FP、FN中三个英文字母T、F、P、N的含义,可能会便于你理解
- T——Ture 正确的判断
- F——False 错误的判断
- P——Positives 正类(表示需要检测目标,例子中就是指女生)
- N——Negatives 负类
知道了这些字母的含义,就很好解释 这三个哥们了。
- TP——Ture Positives(表示判断正确,把正类判断成正类,例子中也就是表示把女生判断成了女生)
- FP——False Positives(表示判断错误,把负类判断成正类,例子中也就是表示把男生判断成了女生)
- FN——False Negatives(表示判断错误,把正类判断成负类,例子中也就是表示把女生判断成了男生)
- TN——True Negatives(表示判断正确,把负类判断成负类,例子中也就是表示把男生判断成了男生)【公式中没用到这个】
上面的几个可能会有点绕,但静下心来研究研究,会发现很简单。这里我就当上面的都看懂了,下面我们就可以计算例子中的TP、FP、FN、TN的值了。
- TP=20 【把正类判断成正类,即找到的20个女生】
- FP=30 【把负类判断成正类,即错误选出的30个男生】
- FN=0 【把正类判断成负类,这里为0】
- TN=50 【把负类判断成负类,即没有选出来的50个男生】
好,现在就都求出了TP、FP、FN,则precision和recall都可以计算出来了。
读到这里,我想你就明白了precision和recall是怎么计算出来的了,但是对于precison和recall为什么用这样的式子表示呢,可能还存在一定的疑惑,先对两个公式进行描述。
-
precision(精度)
首先,精度表示分类的准确性,它等于将(正类分类正确)与(正类分类正确和错误)的比列。对于例子来说precision=20/(20+30)=2/5。 -
recall(召回率,也叫查全率)
召回率的含义是表示(正类分类正确)与(正类分类正确和把正类判断成负类)的比值。对例子来说recall=20/(20+0)=1。通俗点说,recall表示的就是一些没有检测到的物体的比例,比如一张图片有10个目标需要检测,一种方法你检测到了10种目标,那你的召回率就好;而另一种方法只检测到了8个图片,那么你的召回率就不好。
知道了precision和recall,这两个指标都可以表示检测的效果,为了综合表示检测效果,产生了mAP。首先先介绍什么是AP?AP事实上指的是,我们取不同的置信度,可以获得不同的Precision和不同的Recall,当我们取置信度足够密集的时候,就可以获得非常多的Precision和Recall。利用不同的Precision和Recall的点的组合,画出来的曲线下面的面积即为AP的大小。如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0MVYQMnm-1642432549748)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107200931166.png)]](https://img-blog.csdnimg.cn/f3b3e2806341443cbf5762ffc1b18669.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。计算方法就是把所有类的AP值取平均。比如有两类,类A的AP值是0.6,类B的AP值是0.4,那么mAP=(0.6+0.4)/2=0.5。
yolo-v1
整体架构
yolo的英文全称为You only look once,听起来好🤙🏼的样子。这也反应了yolo检测的速度很快,适合做实时检测任务。我们先来看yolo-v1的整体网络架构,如下图所示:

从上图可以看出yolo-v1:
- 网络输入:448×448×3的彩色图片。
- 卷积层:由若干卷积层和最大池化层(池化层未画出)组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
具体实现
从上文我们可以得知,yolo-v1的输入是448×448×3的彩色图片,我们会将每一张图片平均的分成7x7个网格,每个网格分别负责预测中心点落在该网格内的目标。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8GIWI5Ie-1642432549751)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220107215115346.png)]](https://img-blog.csdnimg.cn/9a13d962e832456197094d21698a5785.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_19,color_FFFFFF,t_70,g_se,x_16#pic_center)
具体实现过程如下:
- 将一幅图像分成 S×S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。【yolo-v1分成的是7x7大小的网格】
- 每个网格要预测 B 个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。【yolo-v1要预测的是2个bbox】
- 每个网格还要预测一个类别信息,记为 C 个类。【yolo-v1预测的类别有20种,像猫,狗,汽车等】
- 总的来说,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。【对于yolo-v1,网络输出即是一个7x7x30的张量】
如果你之前已经对yolo算法有了一定的了解,看了上面的内容,大概已经知道yolo-v1的核心思想了。但是呢,如果你第一次看yolo或者对yolo原理不是很熟悉的话,那估计还是有点懵逼。下面从网络的架构出发,详细的介绍yolo-v1的细节。

再次贴出这张图,我们从这张网络架构图进行分析。
-
输入层
输入层是448×448×3的彩色图片,在yolo-v1中要求图片大小是448x448的,这是因为在yolo-v1网络最后接了两个全连接层,全连接层是要求固定大小的向量作为输入的【因为全连接层中权重矩阵W和偏置矩阵b的维度是不变的】,因此要求原始图像也需要一致的图片大小。
-
卷积层
卷积层就是一层一层的卷积,这一部分倒也没什么好说的,对cnn不熟悉的可以看此篇文章。介绍一下,这是July的创始人写的,我觉得他的机器学习的文章写的真是太好了,用很抽象的语言来解释一些算法,读了之后会让你茅厕顿开——哦,原来是这么回事!!!
-
全连接层
全连接层有两层,enmm…其实也没什么好讲的,不明白的可以看上面推荐的文章。但是我们可以来看一下后一个全连接层的维度,1470x1,看着是不是有点奇怪,之前好像几乎没有看到这种维度的输出,为什么设计这样的维度呢?我们在下面的网络输出中进行介绍。
-
输出层
上文提到,最后的全连接层有一个1470x1的输出,这样的维度有什么用呢?其实呢,这是为网络输出准备的,我们的输出要求是7x7x30的张量,刚好是1470,所以全连接层的1470x1的输出经过reshape就可以得到7x7x30的网络输出。我们再来看这个7x7x30网络输出,为什么是这个维度的呢?下面来介绍:
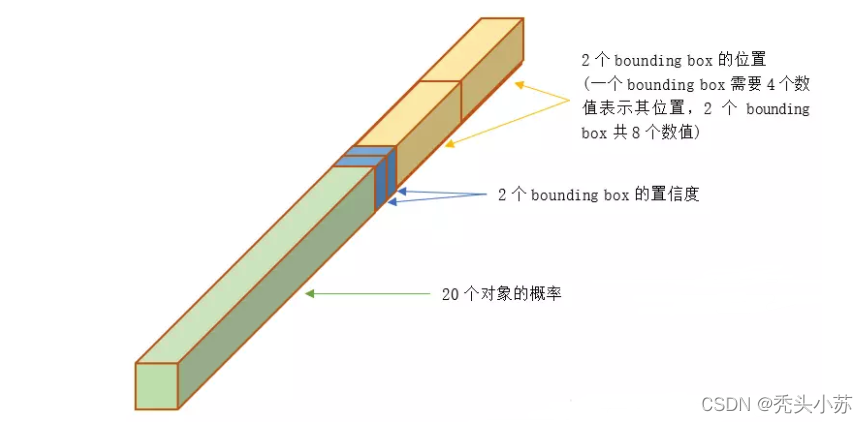
yolo-v1的输入图像被划分为 7x7 的网格(grid),输出张量中的 7x7 就对应着输入图像的 7x7 网格。或者我们把 7x7x30 的张量看作49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。每个网格对应一个30维的向量,这30维的向量中包含哪些信息呢?如下图所示:
-
20个对象的概率
20个对象的概率表示yolo-v1支持20种不同的对象(如猫、狗、汽车等),这里20个对象的概率就是指对应网格中存在任一种对象的概率。
-
2个bbox的置信度
bbox的置信度Confidence表示它是否包含对象且位置准确的程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象或者即便有对象也存在较大的位置偏差。
-
2个bbox的位置
一个bbox的位置需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,宽度,高度),2个bounding box共需要8个数值来表示其位置。
-
损失函数
损失函数主要由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lur7iLtX-1642432549752)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108131822788.png)]](https://img-blog.csdnimg.cn/95a95d93a73343ea85c9e33267184b6d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UBFGQlI2-1642432549755)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220110141642628.png)]](https://img-blog.csdnimg.cn/2f29560568e94d89864f014f6861bd52.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
yolo-v1的优点及局限
-
优点
- 检测速度快
- 迁移能力强
-
缺点
- 输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成此固定分辨率;
- 占比小的目标检测效果不好:虽然每个格子可以预测 2 个 bounding box,但是最终只选择只选择 IOU 最高的bbox作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
- yolo-v1多标签任务不好完成
- yolo-v1有较大的定位误差
yolo-v2
yolo-v2和yolo-v1的整体思想还是基本一致的,但是也做了很多改进,具体如下图:可以发现再进行这些改进之后,网络的mAP指数基本都有所增加,最后yolo-v2的mAP达到了78.6,而yolo-v1只要63.4。下面将对这些改变进行讲述。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v5wEqZFT-1642432549756)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108133446404.png)]](https://img-blog.csdnimg.cn/60c9663f24814dca90a52a2dd9ba9e1d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
batch normalization(归一化 )
v2版本舍弃了droupout(在全连接层,v2没有使用全连接层),卷积后全部加入batch normalization(BN)。什么是BN呢,其实就是归一化,在网络的每一层输入都会做归一化的操作,这样会使收敛更加容易,从上图可以看出,网络加入BN后,网络的mAP提升了将近2个百分点,可见效果十分显著。现在看来,几乎所有的卷积网络都会有batch normalization这一步骤。
BN为什么这么强呢?我举个通俗的例子,现在我市要为小王同学🤖🤖🤖打造一个三年的造星计划,最终目标就是三年后让小王成为我市顶级足球运动员,可是现在一下定一个三年的目标可有点远,我们要一年对小王进行一次全面检测,看看他哪些地方做得不好,给出调整,这样才能尽可能的得到一个高水平的小王。那么BN其实就类似做了每年对小王做检测这样的事,在网络中我们一个卷积后都会对其进行BN操作,这样就会让网络效果更加好,也更容易收敛。
hi-res calssifier(高分辨率分类器)
前面谈及v1版本的时候,说v1输入的是448*448大小的图片,但这是在测试时使用的图片大小,而v1在训练时用的图片大小时224*224d的,这样可能会导致模型前后不一致,影响效果。于是v2在训练时额外又加了10次448*448的微调,这样也使得v2的mAP提升了约4个百分点。
new network
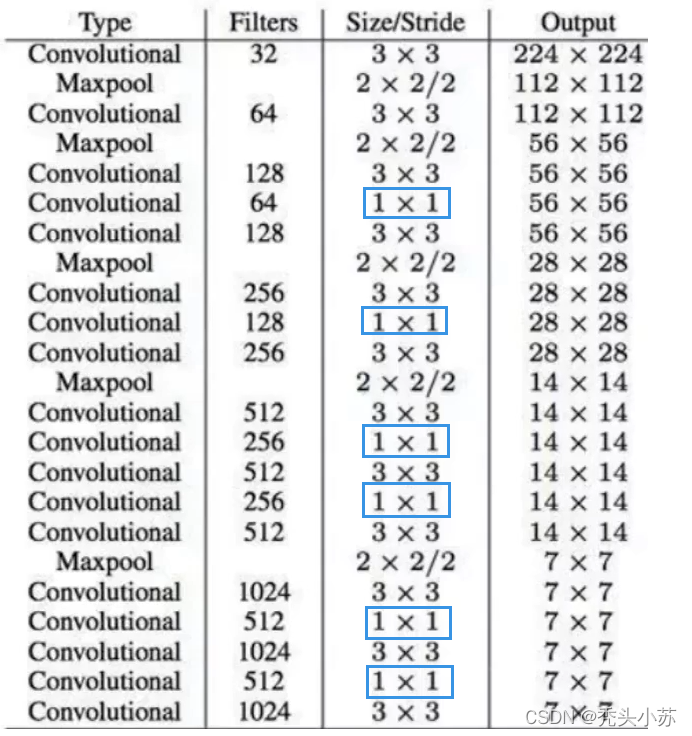
v2中网络结构发生了改变,采用DarkNet19网络(有19个卷积层)。可以看出网络中没有全连接层,进行了5次降采样,网络的实际输入为416*416,在该网络中采用了很多卷积核为1*1的卷积,这样省了很多的参数。
anchor boxes(先验框)
在v1版本当中,我们说到每个网格要预测 2 个bbox。但是呢,这往往会出现一些问题:就是某个网格中物体较多时,会检测不到所有的物体,即出现漏检的情况,这也就导致recall(召回率,查全率)比较低。那么在v2中呢,我们选择每个网格要预测 5 个bbox,采用这种方法来减少recall低的情况。
下图显示了加了先验框后的效果,可以看出,mAP反而减少了【变化不大,可以认为几乎没变】,但网络的recall却增加了7个百分点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0u8Ergv1-1642432549760)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108162234752.png)]](https://img-blog.csdnimg.cn/3b2296c721a3485abdfd522e229dee5c.png#pic_center)
dimension priors(维度聚类)
在上文说到在v2版本中每个网格要预测 5 个bbox,但是这5个bbox的大小不是随便给的,而是通过原始图片聚类得到的,将原始图像中物体框通过K-means算法聚成5类,然后取这五类的平均值作为bbox的大小。这样得出的bbox的大小更符合实际情况,检测效果更好。
location prediction
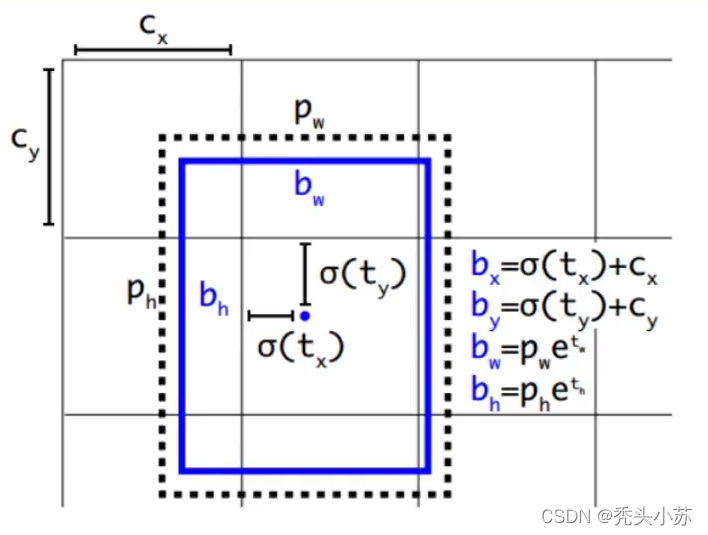
在yolo-v1中,是通过预测 bounding box 与 ground truth 的位置偏移值t~x~,t~y~,间接得到bounding box的位置。其公式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1JnhJlW7-1642432549762)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108164513774.png)]](https://img-blog.csdnimg.cn/a2bf213fbd32449783d8c93cee873b32.png#pic_center)
个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性。
因此 YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标( C ~x~ , C ~y~ )的相对偏移量,同时为了将bounding box的中心点约束在当前网格中,使用 sigmoid 函数将t~x~,t~y~归一化处理,将值约束在0-1,这使得模型训练更稳定。
passthrough
这部分要涉及感受野的知识,不做解释,不知道的可以查阅相关资料。但还是要给出感受野的相关性质和结论:我们在卷积中往往期待用一些小的卷积核来代替大的卷积核【他们的感受野相同,但使用小卷积核所需的网络参数较少】。卷积网络中,越是后面的卷积层其感受野就越大,这样就更容易看到原始图片的全局信息,但是这样对于原始图片中小物体的检测就变得困难,这时候我们就希望同时获得一些感受野稍微小一点的特征图(卷积层越往前感受野越小),这样就可以检测到小目标。具体做法如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CCZwRieY-1642432549765)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108191818723.png)]](https://img-blog.csdnimg.cn/5ef9841254824f79981de492129ff539.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
可以看出,v2把上一层卷积中的特征图插成了4份,然后再和最后一层的特征图叠加得到最后的输出,这样的结果就同时有了感受野大的和感受野小的特征图,这样对图片的大目标和小目标都会有一个不错的检测效果。
multi-scale
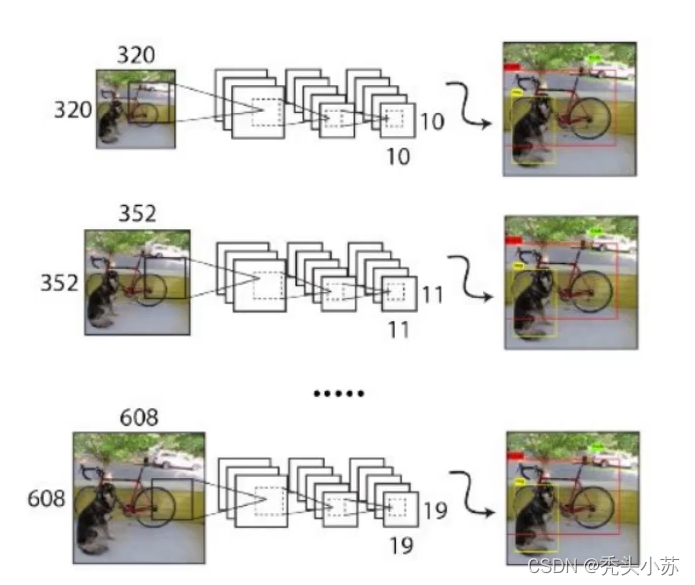
v2版本相较于v1版本而言,没有了全连接层,都是卷积层,这使得网络可以适应多种不同尺度的输入。和v1训练时网络输入的图像尺寸固定不变不同,v2每隔几次迭代后就会微调网络的输入尺寸。这样可以让检测的能力更加全面。通常最小的图像尺寸为320x320,最大的图片尺寸为608x608。
yolo-v3
我们先来看一下v3和其他网络模型的对比!!!看到这张图我不自觉的笑了,这个作者也太有意思了,把v3都画到第二象限了(原点是50)【跨象限碾压😬😬😬】这就足以看出v3的强大了!!!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FkdmQxW9-1642432549766)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108204744846.png)]](https://img-blog.csdnimg.cn/c0f627ba28b949e2b7934295da91e5a9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
多scale
在阐述yolo-v2的改进时,我们谈到使用passthrough可以让我们更有效的检测小目标物体,但其实这样的效果还不是很好。yolo-v3又进行了改进,它采用了多scale的先验框来进行检测。如图所示,我们对不同感受野的网络输出结果采用不同的先验框,设计了三种规模的先验框,每种规模又有三种bbox,也就是一共9种先验框。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1mom9scl-1642432549768)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108204111682.png)]](https://img-blog.csdnimg.cn/3ec1e6735076491ebcef49c9c57da7ad.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
resnet(残差网络)
resnet(残差网络),这个大家应该都很熟悉了吧,因为是我们中国人先提出的。在深度神经网络训练中,从经验来看,随着网络深度的增加,模型理论上可以取得更好的结果。但是实验却发现,深度神经网络中存在着退化问题,人们就以为神经网络就只能做到这里了。但是后来提出一种网络:resnet。其实这种网络原理很好理解,就类似做一个if语句,每加一层后我都进行一个判断,如果结果是好的我就保留,不好的就舍弃。现在基本上resnet已经成为了网络模型的标配。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZnC3bjhb-1642432549770)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220108210239790.png)]](https://img-blog.csdnimg.cn/47b492eb8a51436ab33ec391da6e7b5a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_16,color_FFFFFF,t_70,g_se,x_16#pic_center)
多标签分类
yolo-v3在类别预测方面将yolo-v2的单标签分类改进为多标签分类,在网络结构中将yolo-v2中用于分类的softmax层修改为逻辑分类器。在yolo-v2中,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。然而在一些复杂的场景中,单一目标可能从属于多个类别。
比如在一个交通场景中,某目标的种类既属于汽车也属于卡车,如果用softmax进行分类,softmax会假设这个目标只属于一个类别,这个目标只会被认定为汽车或卡车,这种分类方法就称为单标签分类。如果网络输出认定这个目标既是汽车也是卡车,这就被称为多标签分类。
为实现多标签分类就需要用逻辑分类器来对每个类别都进行二分类。逻辑分类器主要用到了sigmoid函数,它可以把输出约束在0到1,如果某一特征图的输出经过该函数处理后的值大于设定阈值,那么就认定该目标框所对应的目标属于该类。
网络架构
相比于 YOLOv2 的 骨干网络,YOLOv3 进行了较大的改进。借助残差网络的思想,YOLOv3 将原来的 darknet-19 改进为darknet-53。Darknet-53主要由1×1和3×3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。卷积层、批量归一化层以及Leaky ReLU共同组成Darknet-53中的基本卷积单元DBL。因为在Darknet-53中共包含53个这样的DBL,所以称其为Darknet-53。
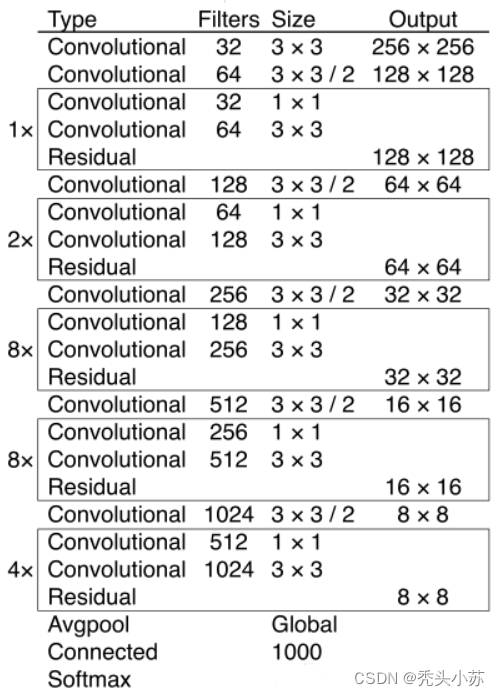
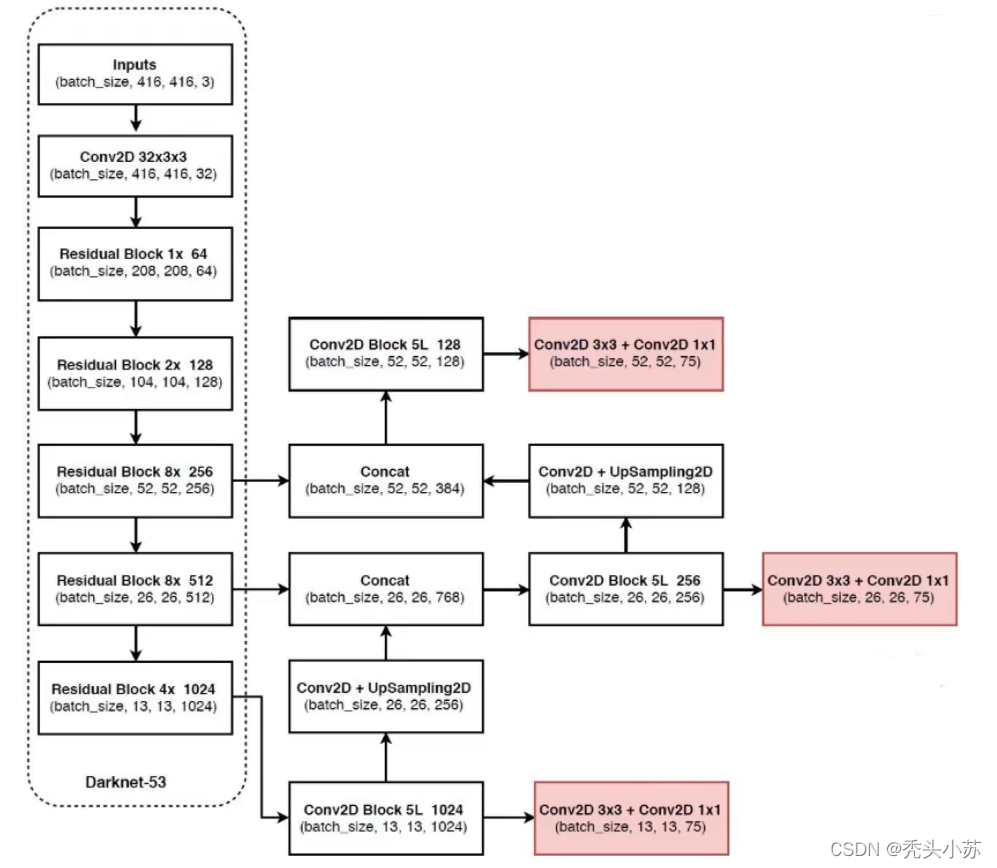
yolo-v4
v3和v4两个版本的作者发生了变化。当时前三个版本的作者redmon在推特上发表了一个声明:大致是说因为yolo-v3已经被用在一些军事上,这是他不想看到的,因此他表示退出CV界。这也从侧面反映了yolo-v3性能的强大。2020年,Alexey Bochkovskiy等人接手了yolo系列,yolo-v4油然而生。
yolo-v4对深度学习中一些常用Tricks进行了大量的测试,最终选择了这些有用的Tricks:WRC、CSP、CmBN、SAT、 Mish activation、Mosaic data augmentation、CmBN、DropBlock regularization 和 CIoU loss。
正是v4中采用了很多的技巧,这些都是近先年各种先进的算法,我没有认真读过这些算法,对这些也不是特别清楚,所以这里不对yolo-v4做整理(整理可能会有很多描述不准确的地方🤡)但是呢,我也在网上看了很多文章,这里我觉得这一篇写得非常清楚,也都把这些用到的算法出处贴了出来,感兴趣的可以自己研读。链接如下:yolo-v4
上面的链接中没有给出原yolo-v4论文,这里附上链接:论文
yolo-v5
呼,终于到v5了,上面的写内容不多,但也花费了2天多的时间😭😭😭终于感觉要到头了🚀🚀🚀
果然不能偷懒,上面的yolo-v4没有自己写,现在的v5好像也不想自己写了。但是“自己的事情自己做”这句话涌上心头,因此我决定还是放上链接吧🙈🙈🙈(真不是自己懒,这个人写的太好了,图文并茂,我认为以我现在的知识储备写不出来,因此还是借用他人的叭!!!到时候需要再看的时候也好直接找到好文章)
链接如下:yolo-v5
咻咻咻咻~~duang~~点个赞呗

- 点赞
- 收藏
- 关注作者
评论(0)