Flink处理函数实战之一:深入了解ProcessFunction的状态(Flink-1.10)

【摘要】 深入了解ProcessFunction的状态操作
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
关于ProcessFunction状态的疑惑
- 学习Flink的ProcessFunction过程中,官方文档中涉及状态处理的时候,不止一次提到只适用于keyed stream的元素,如下图红框所示:

- 之前写过一些flink应用,keyed stream常用但不是必须用的,所以产生了疑问:
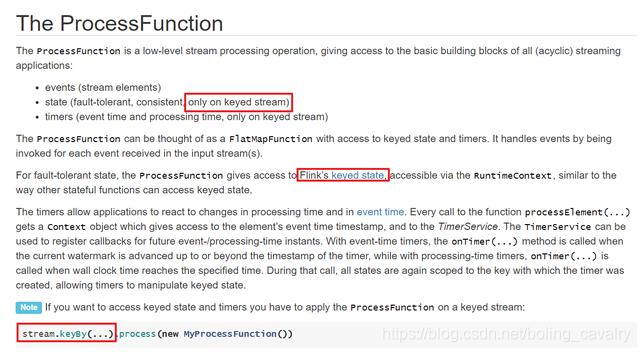
- 为何只有keyed stream的元素能读写状态?
- 每个key对应的状态是如何操作的?
Flink的"状态"
- 先去回顾Flink"状态"的知识点:
- 官方文档说就两种状态:keyed state和operator state:
- 如上图,keyed stream的元素是具有key的特征,与ProcessFunction的操作状态时要求匹配,其他steam的元素由于没有key的特征,所以也就没有状态一说了;
- 另一种状态是Operator State,如下图,这是和多并行度计算时的算子实例绑定的,例如当前算子消费kafka的某个分区的最新offset,而ProcessFunction是用来处理stream元素的,不会涉及到Operator State:


官方demo
- 为了学习ProcessFunction就去看官方demo,地址是:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/process_function.html ,简单说说这个demo的功能:
- 数据源在不间断的产生单词,每个单词对应一个Tuple2<String,String>的实例;
- 数据源被keyBy方法转成KeyedStream,key是Tuple2实例的f0字段;
- 一个KeyedProcessFunction的子类CountWithTimeoutFunction,被用来处理KeyedStream的每个元素,处理的逻辑:为每个key维护一个状态,状态的内容是这个key的出现次数和最后一次出现时间;
- 如果那个key连续一分钟没有出现,KeyedProcessFunction就向下游发送这个元素;
- 以上就是官方demo的功能,本来是想通过demo来加深认识,结果看完不但没有明白,反而更晕了,下图是我对demo代码的疑惑:
- 从上图可见我的疑惑,这里再复述一下:

- 入参value是Tuple2类型,假设其f0字段等于aaa,那么processElement方法的作用,就是取出aaa的状态,更新后保存;
- 从代码上看,state.value()返回了aaa的状态,这个value方法并没有将aaa作为入参,那怎么做到返回aaa的状态呢?如果下一个入参value的f0字段等于bbb了,这个state.value()能返回bbb的状态吗?
- 对更新状态的代码state.update(current)也是同样的疑惑;
- 然后又产生了新的疑惑:成员变量state难道是一直在变?每执行一次processElement,都会变成该key对应的state实例?
先反思为何会有上述疑惑
- 上述疑惑产生的原因,应该是受到平时使用HashMap的影响,HashMap获取值就是在调用get方法时指定key,设置值也是在put时指定key,所以看到state.value()方法没有用key做入参就不习惯了
- 要消除这种不适应,要做的第一件事就是提醒自己:processElement是在框架内运行的,很多数据在之前已经由框架准备好了;
- 接下来要做的,就是把框架准备数据的逻辑看一遍,除了弄明白自己的问题,由于ProcessFunction属于最低阶抽象(如下图的最下方位置),看懂了这些,其实也是在了解DataStream/DataSet API的设计思路:

跟踪源码
- 如下图,让我们从一个断点的堆栈开始吧,这是在执行上面demo中的processElement方法之前的一个断点,可见根源是个线程的run方法,也就是KeyedProcessFunction对应的算子执行任务的线程:
- 上面的堆栈不必每一层都细看,只关注重要的部分,下图这段很重要:StreamTask.run方法中,有个无限循环(猜测是每次执行processInput方法都处理KeyedStream的一个元素):
- 如下图,StreamOneInputProcessor.processInput方法取出KeyedStream的一个元素,调用processElement方法,并将此元素作为入参,再结合上一幅图可以看出:在编写KeyedProcessFunction子类的时候,KeyedStream的每个元素都会作为入参,在调用你重写的processElement方法时传进去;这一点,在做ProcessFunction和KeyedProcessFunction开发时都是要格外注意的:
- 接下来到了最关键的地方了,下图红框中的streamOperator.setKeyContextElement1(record)会解答我前面的疑惑,一定要进去看个清楚,(后面的黄线上的代码,您应该猜到了,里面其实就是调用demo中的processElement方法)
- 下图中,AbstractStreamOperator.setKeyContextElement给出了答案:对于KeyedStream的每个元素,都会在这里算出key,再调用setCurrentKey保存这个key:
- 展开setCurrentKey,如下图,发现key的保存和当前状态的存储策略(StateBackend)有关,我这里是默认策略HeapKeyedStateBackend:
- 最终,根据当前元素得到的key会在StateBackend的keyContext对象中找地方保存,StateBackend的具体实现和Flink设置有关,我这里是保存到了InternalKeyContextImpl实例的currentKey变量中:
- 代码读到这里,对我前面的疑惑,您应该能推测出答案了:state.value()里面会通过StateBackend的keyContext取出刚才保存的key,接下来就能像HashMap那样根据key查出该key的状态了,接下来是愉快的印证我们推测的过程;
- 在state.value()代码位置打断点一次看个明白,如下图,果然,state里面有StateBackend的keyContext对象的引用,访问刚才保存的key就不成问题了:
- 展开state.value()方法如下,简单明了,直接拿keyContext保存的key作为入参去取对应的状态:
- 再展开上面的get方法,可见最终是从stateMap中取得的,而这个stateMap的具体实现是CopyOnWriteStateMap类型的实例:
- 代码读到这里,只剩最后一处需要印证了:更新状态的state.update(current)方法,应该也是以StateBackend的keyContext中的key作为自己的key,再将入参的current作为value,更新到stateMap中,来吧,一起印证这个推测;
- 展开方法,看到的是stateTable.put方法(前面刚看过stateTable的get方法,稳了):
- stateTable.put方法里面和前面的get方法一样,直接拿keyContext保存的key作为自己的key:
- 最终是调用了stateMap.put方法,将数据保存在CopyOnWriteStateMap实例中:
- 得益于Flink代码自身规范、清晰的设计和实现,再加上IDEA强大的debug功能,整个阅读和分析过程十分顺利,这其中的收获会逐渐在今后深入学习DataStreamAPI的过程中见效;












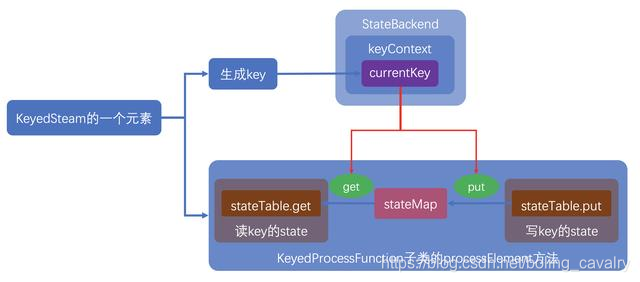
- 最后,根据上面的分析过程绘制了一幅简陋的流程图,希望能帮助您加快理解:
欢迎关注华为云博客:程序员欣宸

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)