Python好题整理第一期:快来看看 你掌握了多少吧~


📢📢📢📣📣📣
🌻🌻🌻Hello,大家好我叫是Dream呀,一个有趣的Python博主,多多关照😜😜😜
🏅🏅🏅Python领域优质创作者,欢迎大家找我合作学习(文末有VX 想进学习交流群or学习资料 欢迎+++)
💕入门须知:这片乐园从不缺乏天才,努力才是你的最终入场券!🚀🚀🚀
💓最后,愿我们都能在看不到的地方闪闪发光,一起加油进步🍺🍺🍺
🍉🍉🍉“一万次悲伤,依然会有Dream,我一直在最温暖的地方等你”,唱的就是我!哈哈哈~🌈🌈🌈
🌟🌟🌟✨✨✨
前言:Python好题整理是根据【Python训练营】以及其他文章中的好题进行整理打造的,可以说是经典中的经典,一套顶十套!
【Python训练营】 是针对Python语言学习所打造的一场刷题狂欢party! 对基础知识把握不牢固的话,欢迎参考此套课程:Python公开课 搭配使用最佳嗷~喜欢的话就抓紧订阅起来吧!
🍋🍋🍋如果对学习没有自制力或者没有一起学习交流的动力,欢迎私信或者在文末添加我的VX,我会拉你进学习交流群,我们一起交流学习,报团打卡
@TOC
Qusetion1:杨辉三角形👻
问题描述
杨辉三角形又称Pascal三角形,它的第i+1行是(a+b)i的展开式的系数。
它的一个重要性质是:三角形中的每个数字等于它两肩上的数字相加。
下面给出了杨辉三角形的前4行:
1
1 1
1 2 1
1 3 3 1
给出n,输出它的前n行。
输入格式
输入包含一个数n。
输出格式
输出杨辉三角形的前n行。每一行从这一行的第一个数开始依次输出,中间使用一个空格分隔。请不要在前面输出多余的空格。
样例输入
4
样例输出
1
1 1
1 2 1
1 3 3 1
思路分析及源码分享💦
1.首先,这道题的话,我们就可以采用创建列表的形式来存储我们的数据;因为我们要输出n行数据,所以说我们需要采用二元列表,即列表中的元素也是列表:nums = [[0]*n for i in range(n)]。
这样的输出结果举一个例子 print([[0]*5 for i in range(5)]):[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
2. 要如何去得到每个列表中对应的数据呢,首先我们观察给一下杨辉三角形
1
1 1
1 2 1
1 3 3 1
我们得到如下规律:
- 我们的第一行一定是个1,第一列都是1,最后一列也是1,这是我们得到的最直观的表面结论
- 其次利用数学方法,我们得知:每一行的的数据都是上一行其对应的数据和前一项加和的结果,即:第四行的第二个数据3是,第三行的第二个数据2和第二行的第一个数据1加和的结果;上一项中没有的数据就是0。
3.得到如上规律,我们便可以进行代码主体布置:
for i in range(n):
for j in range(n):
if j ==0:
nums[i][j] = 1
else:
nums[i][j] = nums[i-1][j]+nums[i-1][j-1]
双循环进行数据赋值,首先就是我们的第一列都是1,也就是说只有j=1,那么此项数据就是1,如果j不是1的话,就利用我们得到的第二条规律进行计算nums[i][j] = nums[i-1][j]+nums[i-1][j-1]。这里的话不免有很多人问,这不就一个数据吗,可以得到其他的众多数据吗?答案是一定可以,我们通过第一行的1,我们就可以逐步计算出第二行的1 1,那么通过第二行的1 1,我们又可以得到第三行的1 2 1,如此循环往复下去,一定就可以慢慢的推出每一项。
4.既然得到了我们的数据,那样要怎么输出呢,不会要将列表输出吧,可是其中还一定有我们并没有进行赋值的[0]元素呀。那么这里要告诉的是,输出要挨步输出,每计算完一步就要输出我们得到的值:
if j ==0:
...
else:
...
if nums[i][j] != 0:
print(nums[i][j],end=' ')
print()
在这里,我们将每一步得到的值进行不换行输出,end=’ ’ 表示将数据进行不换行输出,‘ ’中间有一个空格的意思是将数据中间进行空格处理,也可以将空格换成逗号,那就是用逗号分隔数据。nums[i][j] != 0的作用便是要处理,我们多余出来的没有赋值的[0]元素,这里要特别注意,每输出完一行的数据时我们需要进行换行处理,print()这个换行符我们要加在第二个循环之后,表示结束这个循环进行换行处理。
AC代码:
# @Time : 2022/3/29 10:20
# @Author : 是Dream呀
# @File : 6.杨辉三角形.py
n = int(input())
nums = [[0]*n for i in range(n)] # [0, 0, 0, 0......]
for i in range(n):
for j in range(n):
if j ==0:
nums[i][j] = 1
else:
nums[i][j] = nums[i-1][j]+nums[i-1][j-1]
if nums[i][j] != 0:
print(nums[i][j],end=' ')
print()
Qusetion2:查找整数👻
问题描述
给出一个包含n个整数的数列,问整数a在数列中的第一次出现是第几个。
输入格式
第一行包含一个整数n。
第二行包含n个非负整数,为给定的数列,数列中的每个数都不大于10000。
第三行包含一个整数a,为待查找的数。
输出格式
如果a在数列中出现了,输出它第一次出现的位置(位置从1开始编号),否则输出-1。
样例输入
6
1 9 4 8 3 9
9
样例输出
2
思路分析及源码分享🚀
方法一: 常规法
以列表形式输入我们的数据,然后依次遍历列表中的数据,设置一个count来记录我们遍历循环的次数,如果出现元素与我们的寻找的元素大小一致那就输出此数据,同时break此程序
n = int(input())
list1 = list(map(int,input().split()))
a = int(input())
count = 0
for i in list1:
count += 1
if i == a:
print(count)
break
else:
print(-1)
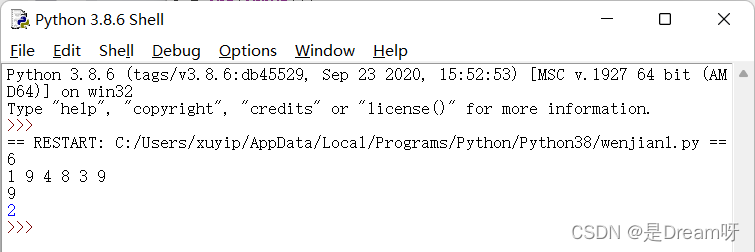
方法二:index()函数法
列表中支持index()操作,list.index(2)表示列表中出现的第一个2的索引值,因为索引是从0开始的,所以要用index()的话,需要我们在输出的结果后+1 :list1.index(a)+1
AC代码:
n = int(input())
list1 = list(map(int,input().split()))
a = int(input())
if a in list1:
print(list1.index(a)+1)
else:
print(-1)
Qusetion3:龟兔赛跑预测👻
话说这个世界上有各种各样的兔子和乌龟,但是 研究发现,所有的兔子和乌龟都有一个共同的特点——喜欢赛跑。于是世界上各个角落都不断在发生着乌龟和兔子的比赛,小华对此很感兴趣,于是决定研究不同兔 子和乌龟的赛跑。他发现,兔子虽然跑比乌龟快,但它们有众所周知的毛病——骄傲且懒惰,于是在与乌龟的比赛中,一旦任一秒结束后兔子发现自己领先t米或以 上,它们就会停下来休息s秒。对于不同的兔子,t,s的数值是不同的,但是所有的乌龟却是一致——它们不到终点决不停止。
然而有些比赛相当漫长,全程观看会耗费大量时间,而小华发现只要在每场比赛开始后记录下兔子和乌龟的数据——兔子的速度v1(表示每秒兔子能跑v1 米),乌龟的速度v2,以及兔子对应的t,s值,以及赛道的长度l——就能预测出比赛的结果。但是小华很懒,不想通过手工计算推测出比赛的结果,于是他找 到了你——清华大学计算机系的高才生——请求帮助,请你写一个程序,对于输入的一场比赛的数据v1,v2,t,s,l,预测该场比赛的结果。
输入
输入只有一行,包含用空格隔开的五个正整数v1,v2,t,s,l,其中(v1,v2< =100;t< =300;s< =10;l< =10000且为v1,v2的公倍数)
输出
输出包含两行,第一行输出比赛结果——一个大写字母“T”或“R”或“D”,分别表示乌龟获胜,兔子获胜,或者两者同时到达终点。
第二行输出一个正整数,表示获胜者(或者双方同时)到达终点所耗费的时间(秒数)。
思路分析及源码分享🌏
1.首先设v1,v2表示乌龟和兔子的速度;t表示兔子领先的距离;s是兔子领先t米后,休息的时间;l是跑道的长度。然后再设s1表示乌龟已跑距离;s2表示兔子已跑的距离;time表示当前已过去的时间。
2.借助while循环,当两者的路程s1和s2小于我们的跑道长度的话,我们就继续我们的while循环,每次以一个单位的时间进行路程的累加和时间的计算。
3.(s2 - s1) >= t and s1 < l and s2 < l:这里兔子满足长度需求进行休息t时间,此时也要加上路程限制,很可能就是之前的+1使其超过路程要求。
4.当兔子进入休息时,我们可以遍历休息的时间来计算乌龟走过的路程,然后再判断乌龟的路程是否超过跑道长度的限制。
if s1 >= l:
# 因为此处只是乌龟的路程会增加,因此只需要判断乌龟的路程是不是超出限制,
# 此处不是=号,而是>=号,因为乌龟的速度也不确定,
# 每次一个单位时间的距离也不能刚刚达到路程大小。
break
最后只需要比较超过循环限制后的乌龟走的路程多还是兔子走过的路程多,然后输出对应的值。
AC代码:
# @Time : 2022/4/5 14:59
# @Author : 是Dream呀
# @File : 13 龟兔赛跑.py
v1, v2, t, s, l = map(int,input().split()) # v1,v2表示乌龟和兔子的速度;t表示兔子领先的距离;s是兔子领先t米后,休息的时间;l是跑道的长度。
s1, s2, time = 0, 0, 0 # s1表示乌龟已跑距离;s2表示兔子已跑的距离;time表示当前已过去的时间
while s1 < l and s2 < l:
s1 += v1
s2 += v2
time += 1
if (s2 - s1) >= t and s1 < l and s2 < l: # 这里兔子满足长度需求进行休息t时间,此时也要加上路程限制,很可能就是之前的+1使其超过路程要求;
for i in range(s): # 这里采用for循环遍历时间,每次遍历一个单位的时间。
s1 += v1
time += 1
if s1 >= l: # 因为此处只是乌龟的路程会增加,因此只需要判断乌龟的路程是不是超出限制,此处不是=号,而是>=号,因为乌龟的速度也不确定,每次一个单位时间的距离也不能刚刚达到路程大小。
break
if s1 > s2:
print('T')
elif s2 > s1:
print('R')
else:
print('D')
print(time)
Qusetion4:Huffuman树👻
题目描述
Huffman树在编码中有着广泛的应用。在这里,我们只关心Huffman树的构造过程。
给出一列数{pi}={p0, p1, …, pn-1},用这列数构造Huffman树的过程如下:
找到{pi}中最小的两个数,设为pa和pb,将pa和pb从{pi}中删除掉,然后将它们的和加入到{pi}中。这个过程的费用记为pa + pb。
重复步骤1,直到{pi}中只剩下一个数。
在上面的操作过程中,把所有的费用相加,就得到了构造Huffman树的总费用。
本题任务:对于给定的一个数列,现在请你求出用该数列构造Huffman树的总费用。
例如,对于数列{pi}={5, 3, 8, 2, 9},Huffman树的构造过程如下:
找到{5, 3, 8, 2, 9}中最小的两个数,分别是2和3,从{pi}中删除它们并将和5加入,得到{5, 8, 9, 5},费用为5。
找到{5, 8, 9, 5}中最小的两个数,分别是5和5,从{pi}中删除它们并将和10加入,得到{8, 9, 10},费用为10。
找到{8, 9, 10}中最小的两个数,分别是8和9,从{pi}中删除它们并将和17加入,得到{10, 17},费用为17。
找到{10, 17}中最小的两个数,分别是10和17,从{pi}中删除它们并将和27加入,得到{27},费用为27。
现在,数列中只剩下一个数27,构造过程结束,总费用为5+10+17+27=59。
输入
输入的第一行包含一个正整数n(n< =100)。
接下来是n个正整数,表示p0, p1, …, pn-1,每个数不超过1000。
输出
输出用这些数构造Huffman树的总费用。
思路分析及源码分享🍻
列表形式存储数据,然后对列表进行排序处理,这里可以借助pop()函数进行求解,直接依次数的值取最后的两个数的值。但是正常默认排序是由小到大,这里我们需要让reverse = True来进行由大到小排序。
AC代码:
# @Time : 2022/3/31 15:40
# @Author : 是Dream呀
# @File : 12.Huffuman树.py
n = int(input())
list1 = list(map(int,input().split()))
a = len(list1)
list2 = []
for i in range(1,a):
list1.sort(reverse = True) # sort()函数直接a.sort()就可以用,不用前面再复制一个变量;而sorted()函数的函数的话前面还需要重新定义一个变量。
a1 = list1.pop()
a2 = list1.pop()
list1.append(a1+a2)
list2.append(a1+a2)
print(sum(list2))
Qusetion5:2n皇后问题👻

思路分析及源码分享🚩
两种思路
思路一:同时放黑皇后和白皇后
思路二:放完黑皇后以后,再放白皇后
第一种解法(耗时较长)
同时考虑黑皇后和白皇后
考虑index行,分三步:
1.在index行放置黑皇后
2.在index行放置白皇后
3.递归,在index+1重复上述操作 递归结束条件 index == n
from collections import defaultdict
n = int(input())
board = []
for i in range(n):
board.append(input().split())
col1 = defaultdict(bool)
dia11 = defaultdict(bool)
dia21 = defaultdict(bool)
col2 = defaultdict(bool)
dia12 = defaultdict(bool)
dia22 = defaultdict(bool)
count = 0
def dfs(index):
global count
if n <= 0:
return 0
if index == n:
count += 1
return
# 在第index行放置黑皇后
for j in range(n):
if not col1[j] and not dia11[index + j] and not dia21[index - j] \
and board[index][j] == "1":
col1[j] = True
dia11[index + j] = True
dia21[index - j] = True
board[index][j] = "0"
for k in range(n):
if not col2[k] and not dia12[index + k] and not dia22[index - k] \
and board[index][k] == "1":
col2[k] = True
dia12[index + k] = True
dia22[index - k] = True
board[index][k] = "0"
dfs(index + 1)
col2[k] = False
dia12[index + k] = False
dia22[index - k] = False
board[index][k] = "1"
col1[j] = False
dia11[index + j] = False
dia21[index - j] = False
board[index][j] = "1"
return 0
dfs(0)
print(count)
第二种解法(耗时短)
1.先在index放置黑皇后
2.递归,在index+1行放置黑皇后
3.递归到底,index == n ,这个时候说明黑皇后已经全部放置完毕(一种情况),这个时候再开始第二次dfs2(0),这个时候是放置白皇后,白皇后也放置完毕以后,一个解就找到了。
AC代码:
from collections import defaultdict
n = int(input())
board = []
for i in range(n):
board.append(input().split())
col1 = defaultdict(bool)
dia11 = defaultdict(bool)
dia21 = defaultdict(bool)
col2 = defaultdict(bool)
dia12 = defaultdict(bool)
dia22 = defaultdict(bool)
count = 0
def dfs2(index):
global count
if index == n:
count += 1
return
# 在第index行放置黑皇后
for j in range(n):
if not col2[j] and not dia12[index + j] and not dia22[index - j] \
and board[index][j] == "1":
col2[j] = True
dia12[index + j] = True
dia22[index - j] = True
board[index][j] = "0"
dfs2(index + 1)
col2[j] = False
dia12[index + j] = False
dia22[index - j] = False
board[index][j] = "1"
return 0
def dfs1(index):
if n <= 0:
return 0
if index == n:
dfs2(0)
return
# 在第index行放置黑皇后
for j in range(n):
if not col1[j] and not dia11[index + j] and not dia21[index - j] \
and board[index][j] == "1":
col1[j] = True
dia11[index + j] = True
dia21[index - j] = True
board[index][j] = "0"
dfs1(index + 1)
col1[j] = False
dia11[index + j] = False
dia21[index - j] = False
board[index][j] = "1"
return 0
dfs1(0)
print(count)
Qusetion6:矩阵乘法👻
思路分析及源码分享🌏
1.快速幂
def fastpow(base,n)
ans=1
while(n):
ifn&1:
ans*=base
base*=base
n>>=1
return ans
2矩阵乘法
AC代码:
def multi(matrix_a,matrix_b):
#对于a*b和b*c的矩阵,得到的规模是a*c
matrix_result=[[0 for _ in range(len(matrix_b[0]))] for _ in range(len(matrix_a))]
for i in range(len(matrix_a)):
for j in range(len(matrix_b[0])):
#这里len(matrix_b)也可以换成len(matrix_a[0])
for k in range(len(matrix_b)):
matrix_result[i][j]+=matrix_a[i][k]*matrix_b[k][j]
return matrix_result
Qusetion7:阶乘计算👻
题目描述
输入一个正整数n,输出n!的值。
其中n!=123*…*n。
算法描述
n!可能很大,而计算机能表示的整数范围有限,需要使用高精度计算的方法。使用一个数组A来表示一个大整数a,A[0]表示a的个位,A[1]表示a的十位,依次类推。
将a乘以一个整数k变为将数组A的每一个元素都乘以k,请注意处理相应的进位。
首先将a设为1,然后乘2,乘3,当乘到n时,即得到了n!的值。
输入
输入包含一个正整数n,n< =1000。
输出
输出n!的准确值。
思路分析及源码分享🚀
方法一:常规法
for 循环依次遍历每个数,然后进行相乘:
n=int(input())
ans=1
for i in range(1,n+1):
ans*=i
print(ans)
方法二:factorial函数法
直接调用math库中的 factorial() 函数直接运算。
AC代码:
#主页有蓝桥杯真题免费下载
import math
print(math.factorial(int(input())))
#math.factorial(x) 返回x的阶乘
#>>> math.factorial(5)
#120
Qusetion8:特殊的数字👻
问题描述
153是一个非常特殊的数,它等于它的每位数字的立方和,即153=111+555+333。编程求所有满足这种条件的三位十进制数。
输出格式
按从小到大的顺序输出满足条件的三位十进制数,每个数占一行。
思路分析及源码分享💦
这个题就是可以借用Python中自带的函数pow()进行求解
pow(x,y)表示求解x的y次幂
pow(x,y,z)表示求解x的y次幂对z取余后的结果
print(pow(2,3)) # 2的3次方是多少
# 8
print(pow(2,3,5)) # 2的3次方是8,然后8再对5进行取余处理
# 3
AC代码:
for i in range(100,1000):
a=list(str(i))
if i==pow(int(a[0]),3)+pow(int(a[1]),3)+pow(int(a[2]),3):
print(i)

🌟
The best time to plant a tree is ten years ago, followed by now!🌟
🌲🌲🌲 最后,作者很感谢能够阅读到这里的读者。如果看完觉得好的话,还请轻轻点一下赞或者分享给更多的人,你们的鼓励就是作者继续行文的动力。
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了,我们下期再见~



- 点赞
- 收藏
- 关注作者
评论(0)