详细且通俗讲解轻量级神经网络——MobileNets【V1、V2、V3】

轻量级神经网络——MobileNets
MobileNetV1
深度可分离卷积
之前,总结了一些深度学习的经典网络模型,如LeNet、VGG、GooogleNet等等,详情转移至这篇博客:深度学习经典网络模型汇总。链接博文中的网络模型其实已经达到了相当不错的效果,但是存在一个的问题,就是这些模型非常庞大,参数较多,计算量较大,在一些实际的场景如移动或嵌入式设备中很难被应用。这时候就出现了可以针对这些移动场景的轻量级的网络——MobileNets。【移动的网络,是不是很轻🎈🎈🎈】
那么MobileNet网络主要的做了什么呢,下面跟着我一起来看看🍋🍋🍋
我们先来看一下论文中的描述,如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sVIb4LTZ-1645335379559)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218144041762.png)]](https://img-blog.csdnimg.cn/2bae56c2442942779a2c6c992e5e1085.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
再来重复下这句话:MobileNet模型是基于深度可分离卷积,这是一种分解卷积的形式。这种形式将标准卷积分解为一个深度卷积【这里翻译成逐深度卷积可能更好,后文中深度卷积即指逐深度卷积】**和一个称为逐点卷积的1x1的卷积。**读到这句话,你可能会有点懵,不知道分解卷积是怎么操作的,但是我们先可以思考一下进行这样的分解有什么用?可能很多小伙伴已经想到了,既然这里讲的是MobileNet,而MobileNet有是轻量级的网络,那这步操作十有八九就是通过这样的分解可以让我们的模型更加轻量,模型参数更少!!!的确是这样的,相关描述再原论文中也有体现,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-evs6whrn-1645335379561)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218145214477.png)]](https://img-blog.csdnimg.cn/5783ab684e2244b99ea663fcf56e5e9e.png#pic_center)
下面就来详细的介绍MobileNet的深度可分离卷积,按照论文上的描述,深度可分离卷积应该由两个部分组成,即深度卷积和逐点卷积。用下图直观进行表示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tl06qXs1-1645335379565)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218150056365.png)]](https://img-blog.csdnimg.cn/bb7b90fef94b4abb9f8374094c854f7f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
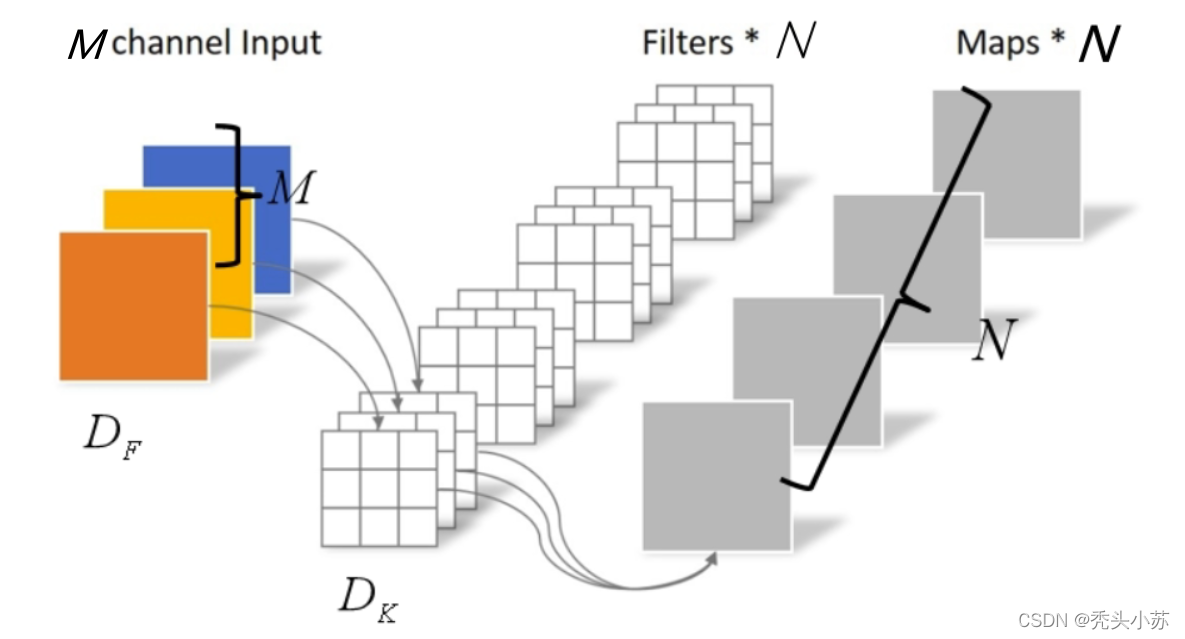
在谈及深度可分离卷积之前,我们先来温习一下标准卷积是怎么操作的。下图中我们可以看到我们的输入是1个DF x DF 大小的图片,有M个通道,卷积核大小为M x DK x DK ,有N个卷积核,那么经过卷积后输出特征图的大小为DF x DF,个数为N。【这里假设卷积后输入输出尺寸不变】
【标准的卷积操作这里再做几点说明,方便后面理解深度可分离卷积。首先我们的输入通道是3,那么我们卷积核的尺度必须也有一个维度为3。其次,卷积核的个数为N,则输出的特征图的个数为N】
介绍了标准的卷积后,下面来谈谈深度可分离卷积。我们分别来介绍深度卷积和逐点卷积。
1、深度卷积✨✨✨
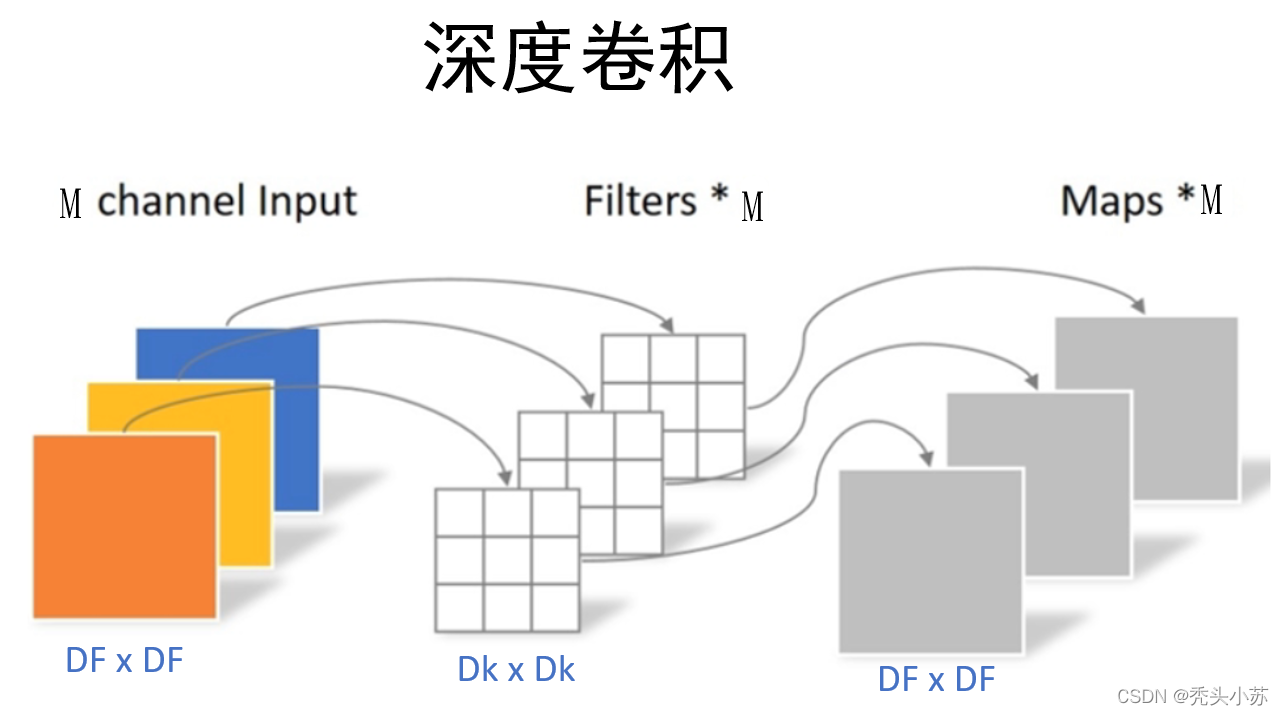
深度卷积与标准卷积的区别在于深度卷积的卷积核为单通道模式,需要对输入的每一个通道进行卷积,这样就会得到和输入特征图通道数一致的输出特征图。通过下图进行理解:可以看出,我们输入特征图的通道上为3,由于采用的卷积核是单通道模式,所以必须要三个这样的单通道卷积核才可以和输入图像完全一一对应的卷积,这样就得到了输出的特征图,输出特征图的个数为3。可以发现深度卷积的输入特征图通道数=卷积核个数=输出特征图个数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8XXltTx4-1645335379569)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218153442814.png)]](https://img-blog.csdnimg.cn/ca986ccd6ef04bc28071db412dc49afc.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
这里我们再用一个具体点的例子巩固一下深度卷积,下图中输入12×12×3的特征图,卷积核大小为5×5×1,卷积核个数为3,得到了8×8×3的输出特征图。同样的,可以发现输入特征图通道数=卷积核个数=输出特征图个数。
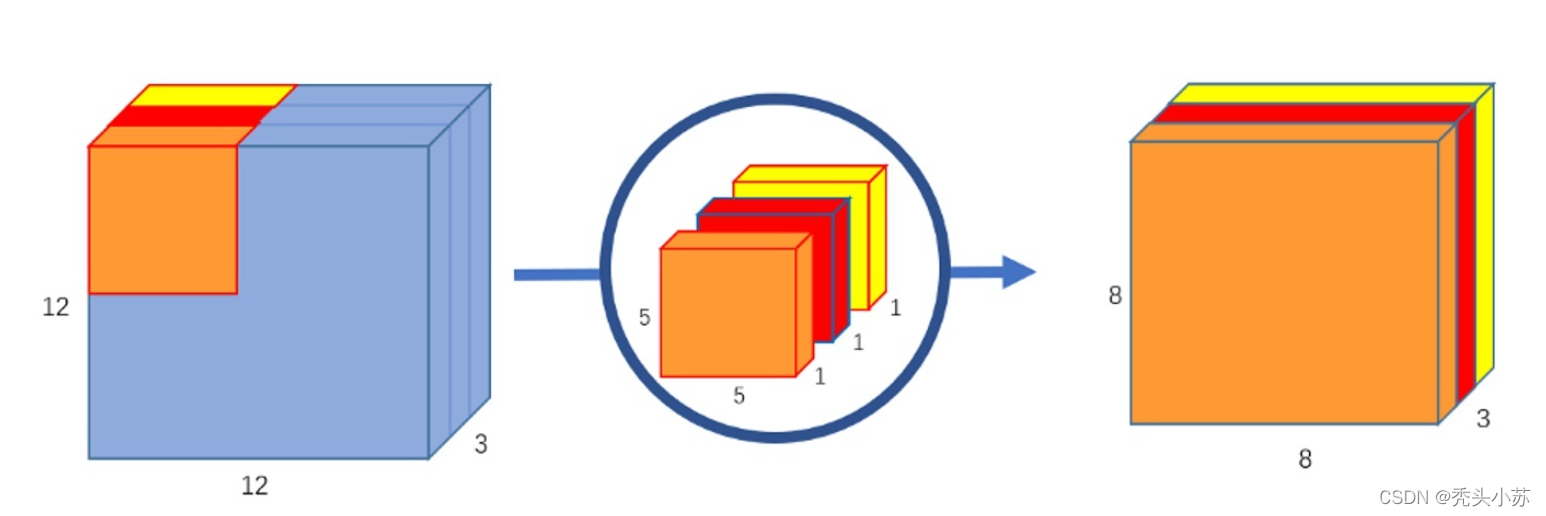
来源于知乎R.JD
2、逐点卷积✨✨✨
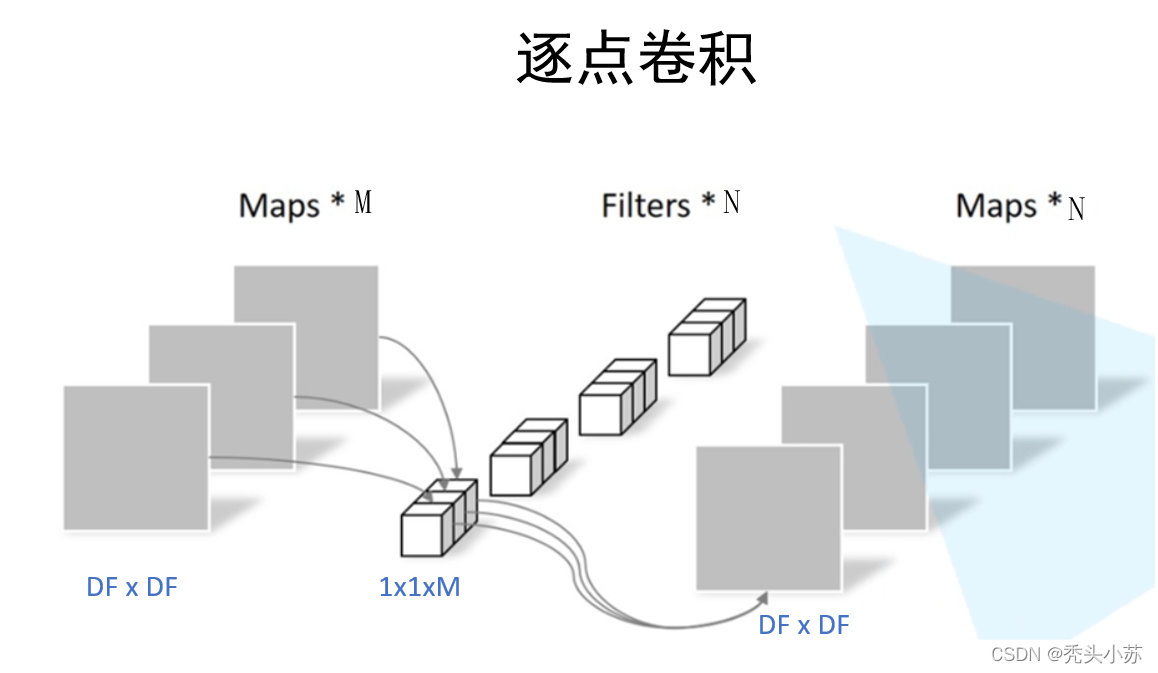
通过上一步的深度卷积,我们得到了特征图。但是我们发现输入特征图通道数=卷积核个数=输出特征图个数,这样一来,就会导致输出的特征图的个数太少了【或者可以说输出特征图的通道数太少了,上图可以看成是输出特征图个数为1,通道数为3】,从而可能会影响信息的有效性。这时候就需要进行逐点卷积。逐点卷积这个名字听起来很高大上,但是实质就是用1x1的卷积核进行升维。【1x1的卷积大家应该很熟悉了,在GoogleNet中就大量用到了1x1的卷积核,那里主要是用来降维。1x1的卷积核的主要作用就是对特征图进行升维和降维。】同样的,通过一些图片进行理解:可以看出我们从上一步得到了3个特征图【或者可以说是一个有三个通道的特征图】,卷积核大小为1x1x3,卷积核个数为4,这样卷积后就可以得到4个特征图【得到特征图的个数取决于卷积核的个数】。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xq2zXtKN-1645335379572)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218195652792.png)]](https://img-blog.csdnimg.cn/8d047e55e5b84de4815b662a1614dedc.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
同样的,我们再举一个具体的例子来巩固逐点卷积。当进行深度卷积后,得到8x8x3的特征图,此时用256个大小为1x1x3的卷积核进行卷积,得到特征图尺寸为8x8x256。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0pxLfM3L-1645335379573)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218200426517.png)]](https://img-blog.csdnimg.cn/b9131c41c131434e93d75174408220cc.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
图片来源于知乎R.JD
参数量和计算量
读到这里,其实MobileNet的核心就讲完了,是不是发现还挺容易的🌻🌻🌻接下来我们再次回到开头所说的轻量级网络,即我们要讨论为什么通过上面的深度可分离卷积操作可以实现轻量级网络。我们通过比较标准的卷积和深度可分离卷积所需要的参数量和计算量来进行分析。【对参数量、计算量不清楚可参考链接,当然下文也会对参数量、计算量进行解释】
1、标准卷积
- 参数量:卷积核的尺寸是DK x DK×M,一共有N个,所以标准卷积的参数量是DK x DK×MxN
- 计算量:卷积核的尺寸是DK x DK×M,一共有N个,每一个都要进行DF x DF次运算【假设输出的特征图尺寸也是DF x DF】,所以标准卷积的计算量是DK x DK×MxNxDF x DF。
【这里简单说一下参数量和计算量。参数量是指网络中需要多少参数,对于卷积来说,就是卷积核里所有的值的个数,它往往和空间使用情况有关;计算量是指网络中我们进行了多少次乘加运算,对于卷积来说,我们得到的特征图都是进行一系列的乘加运算得到的,计算公式就是卷积核的尺寸DK x DK×M、卷积核个数N、及输出特征图尺寸DF x DF的乘积,计算量往往和时间消耗有关。】
2、深度可分离卷积✨✨✨
深度可分离卷积由深度卷积核逐点卷积构成。
-
参数量
- 深度卷积:深度卷积的卷积核尺寸DK x DK×1,个数为M,所以参数量为DK x DK×M。
- 逐点卷积: 逐点卷积的卷积核尺寸为1×1×M,个数为N,所以参数量为M x N。
因此深度可分离卷积的参数量为DK x DK×M+M x N。
-
计算量
- 深度卷积:深度卷积的卷积核尺寸DK x DK×1,个数为M,每个都要做DF x DF次乘加运算,所以计算量为DK x DK×MxDF x DF。
- 逐点卷积:逐点卷积的卷积核尺寸为1×1×M,个数为N,每个都要做DF x DF次乘加运算,所以计算量为MxNxDF x DF。
因此深度可分离卷积的参数量为DK x DK×MxDF x DF+MxNxDF x DF。
得到了标准卷积和深度可分离卷积的参数量和计算量,我们用它们的比值做一些比较:一般的,N较大, 可忽略不计,DK 表示卷积核的大小,若DK =3, 。即我们若使用常见的3×3的卷积核,那么使用深度可分离卷积的参数量和计算量下降到原来的九分之一左右。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HBwUjji6-1645335379575)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218214107946.png)]](https://img-blog.csdnimg.cn/ffebfbda2d56433b98a51607d0d966dd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
MobileNetV1的网络结构及效果
讲到这里,MobileNet的最本质的深度可分离卷积算是叙述清楚了!!!明白了深度可分离卷积,接下来就很简单,我们可以先来看一下MobileNet的网络结构,如下图所示:明白了我之前文章中对于卷积后特征图的变化及本文前文的讲述,这个结构各步特征图变化是很好推导的,这里不做过多阐述。但下图中标黄部分采用了步长为2的卷积后,特征图大小前后没有改变,当然这是可以通过padding达到的,但是既然想保持特征图不变,为什么不采用步长为1的卷积呢?这是我的疑惑之处,如若有知道原因的,恳请解答📝📝📝
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-93DxmYGI-1645335379577)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218220906298.png)]](https://img-blog.csdnimg.cn/37b7b0da332a4bb5bc19f357ee3c64b2.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
最后,我们来看一下实验结果:可以发现,作为轻量级网络的MobileNet计算量和参数量均小于GoogleNet,同时在分类效果上比GoogleNet还要好,这就是深度可分离卷积的功劳了。VGG16的计算量参数量比MobileNet大了30倍,但是结果也仅仅只高了1%不到。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J9fj8SzR-1645335379578)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220218221808320.png)]](https://img-blog.csdnimg.cn/00f8860f3e5141d39a23c62b761e1bfa.png#pic_center)
其实,在MobileNet的论文中还提及了使用超参数来灵活调整网络,使网络在性能降低不多的情况下大量减少参数量和使用量,但我觉得这部分理解起来就较为简单了,就是用超参数来控制图像尺寸大小及卷积核个数以达到改变模型大小的功能,感兴趣的可以去看看原论文,下载地址:https://arxiv.org/abs/1704.04861。
MobileNetV2
在MobileNetV1的实际训练过程中,很多人发现深度卷积时卷积核特别容易废掉,即训练完成后很多卷积核是空的,这时候MobileV2就来了。前面谈到的V1深度卷积中卷积核容易报废,V2认为造成这样的原因是由于Relu函数造成的(Relu默默流下了眼泪😢😢😢)可以看一下论文中的描述:下图标黄文字的大致意思就是说**在输入维度是2,3时,输出和输入相比丢失了较多信息;但是在输入维度是15到30时,输出则保留了输入的较多信息。**这就是说我们在使用Relu函数时,当输入的维度较低时,会丢失较多信息,因此我们这里可以想到两种思路,一是把Relu激活函数替换成别的,而是通过升维将输入的维度变高。事实上V2就是这么做的,V2的题目为Inverted Residuals and Linear Bottlenecks , Linear Bottlenecks和Inverted Residuals就是V2的核心,也是上述所说两种思路的描述。

Linear Bottlenecks✨✨✨
首先我们先来看一下MobileNetV1中深度可分离卷积的每个块的细节:左边是标准卷积,右边是深度可分离卷积。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iKf2pXZ1-1645335379580)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219150041065.png)]](https://img-blog.csdnimg.cn/0c3a6ae3b71547e4a509febef29c2d94.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
深度可分离卷积的每个块构成:首先是一个3x3的深度卷积,其次是BN、Relu层,接下来是1x1的逐点卷积,最后又是BN和Relu层。我们前文说需要把Relu激活函数替换成别的,V2将Relu替换成线性激活函数。但是需要注意的是,并不是将所有的Relu激活都换成了线性激活,而是将上图中标黄的Relu变成了线性激活函数。变换后的块文章中称为Linear Bottlenecks,结构如下图所示:
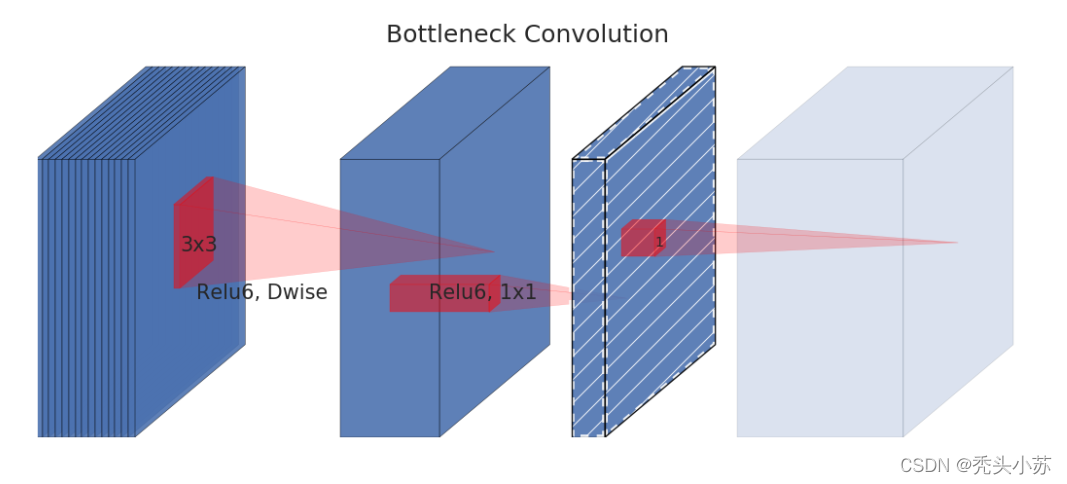
Inverted Residuals✨✨✨
Inverted Residuals中文是倒残差结构,我们来看看其和正常的残差结构之前有什么区别和联系:通过下图可以看出,左侧为ResNet中的残差结构,其结构为1x1卷积降维->3x3卷积->1x1卷积升维;右侧为MobileNetV2中的倒残差结构,其结构为1x1卷积升维->3x3DW卷积->1x1卷积降维。V2先使用1x1进行升维的原因也是前面所说的高维信息通过ReLU激活函数后丢失的信息更少。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SYjmrHVU-1645335379582)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219152328879.png)]](https://img-blog.csdnimg.cn/f3225c811f8945198e3641580aed18d4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
这部分需要注意的是只有当s=1,即步长为1时,才有shortcut连接,步长为2是没有的,如下图所示。
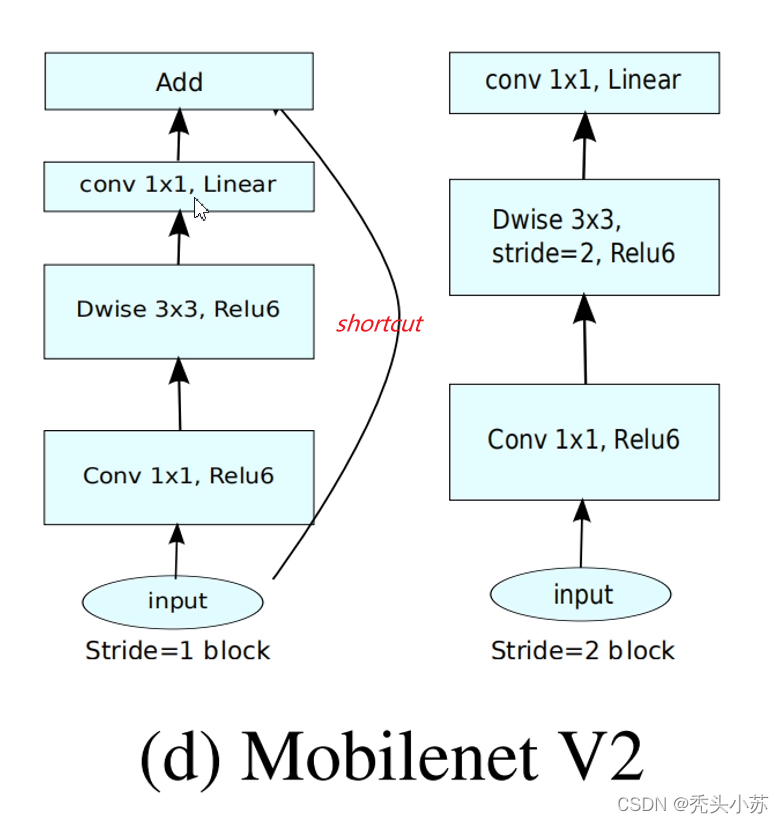
MobileNetV2的网络结构及效果
下图是V2的网络结构,每一步变化也很好计算,特别需要注意的是步距s,当有多个bottleneck,s只针对第一个bottleneck,后面s都为1。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-trAHgf2h-1645335379583)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219155011654.png)]](https://img-blog.csdnimg.cn/3c20639d9d3d426da416843d2039e0b6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
V2的效果如下:可以看到V2所用的参数更少,但Map值和其它的差不多,甚至超过了Yolov2。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iF52dBsy-1645335379585)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219155920209.png)]](https://img-blog.csdnimg.cn/fcb768850dd3466e9aeb4d5736d87c8c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
原论文下载地址:MobileNetV2
MobileNetV3
前面已经讨论了V1和V2版本的mobileNet,接下来将谈谈V3版本的MobileNet💯💯💯当刚打开论文看摘要时,就发现出现了一个生词NAS(网络结构搜索)。怎么理解呢,这里谈谈自己的看法。之前的网络,不管是VGG、ResNet、MobileNetV1、MobileNetV2,网络结构都是我们自己手动去设计的,像网络的层数、卷积核大小、步长等等参数都需要自己设置。而NAS是通过计算机来实现最优的参数设定,通过比较不同参数的网络模型效果,从而选择最优的参数设置。这么看来,NAS简直太好了,但是这也对计算机的性能要求也特别的高,感觉是土豪玩的游戏🙈🙈🙈NAS这里就不多说了,感觉离我太远,知道个大概就好,感兴趣的可以了解下!!!接下来主要谈谈论文中其它的一些改进之处。

新增SE模块✨✨✨
下图上半部分是V2的block,下半部分是V3的block。V2的block在上文已经提及,这里不再赘述;V3的block和V2基本一致,主要是加入了SE模块(图中黄色框部分)。怎么理解这个SE模块呢?它首先是将特征图的每个通道都进行平均池化,然后进行两个全连接层得到一个输出结果,这个结果会和原始的特征图进行相乘,得到新的特征图。【需要注意的是第一个全连接层的输出设置为原来通道数的1/4(本论文中是这么设置的),第二个全连接层输出设置为通道数】
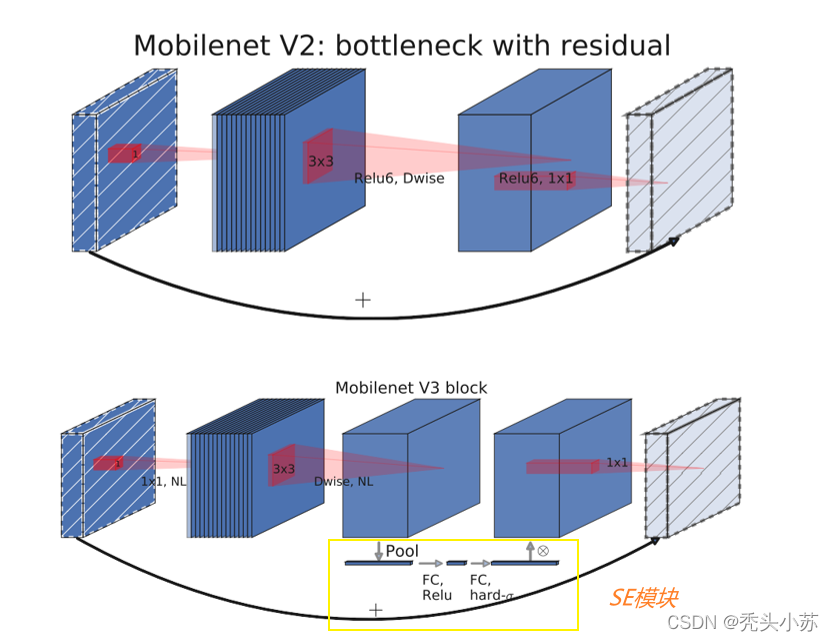
是不是还没看懂,下面用一个例子来通俗解释一下。首先下图左上角表示为两个通道的特质图,经平均池化后得到左下角的图;再次经过两次全连接层后,转化成了右下角的图,最后用右下角的0.5、0.6分别乘原始的特质图,则得到最终的右上角的图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XhC6a19q-1645335379587)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219210356512.png)]](https://img-blog.csdnimg.cn/8fbd957aec054d8ca08eb4452f42a1c0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
图片来自B站UP主霹雳吧啦Wz
重新设计耗时层结构
-
减少第一个卷积层卷积核个数(32——>16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eHMQeQYs-1645335379588)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219213131983.png)]](https://res-hd.hc-cdn.cn/ecology/9.3.209/v2_resources/ydcomm/libs/images/loading.gif)
-
精简Last Stage
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eHMQeQYs-1645335379588)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219213131983.png)]](https://img-blog.csdnimg.cn/53af8e07e113405885c394b8b3b6c60b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
Original Last Stage是通过NAS算出来的,但最后实际测试发现Efficient Last Stage结构可以在不损失精度情况下去年一些多余的层。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hztcM66h-1645335379589)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219213846251.png)]](https://img-blog.csdnimg.cn/6952043c57ec43f483bdec03e0cc0550.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
重新设计激活函数✨✨✨
在V1和V2版本中我们用到的Relu激活函数其实是Relu6激活函数,前文没有讲述,这里进行统一讲解。下图为Relu和Relu6的图像和表达式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gW9tojVJ-1645335379591)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219215335231.png)]](https://img-blog.csdnimg.cn/98f070210c954002b68db7800515d6d9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
V3版本使用的激活函数为h-swish,其图像和表达式如下图所示:图中包括了一些其他相关的一些函数表达式及图像。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cy1enWzu-1645335379592)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219220359028.png)]](https://img-blog.csdnimg.cn/bed44c5e9bb340c5a19ab2339f875f9f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
MobileNetV3的网络结构及结果
V3的网络结构如下,每一步也很好推,这里也不再进行描述。下图是V3-Large的网络结构,V3-small与其类似,这里不在叙述。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4BdFDCs4-1645335379593)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219221747292.png)]](https://img-blog.csdnimg.cn/d6253b5a869c44789c36c08a4fe63420.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
V3的模型效果如下:优势还是挺明显的💯💯💯
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vH5PperE-1645335379594)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219222229812.png)]](https://img-blog.csdnimg.cn/cb60249b31c24f3290a66ca8a0121d19.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
原论文下载地址:MobileNetV3
如若文章对你有所帮助,那就🛴🛴🛴
咻咻咻咻~~duang~~点个赞呗

- 点赞
- 收藏
- 关注作者
评论(0)